RICo: Refined In-Context Contribution for Automatic Instruction-Tuning Data Selection
作者: Yixin Yang, Qingxiu Dong, Linli Yao, Fangwei Zhu, Zhifang Sui
分类: cs.CL
发布日期: 2025-05-08 (更新: 2025-05-18)
💡 一句话要点
提出RICo,通过上下文学习改进指令微调数据选择,提升大模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 数据选择 上下文学习 大语言模型 无梯度方法
📋 核心要点
- 指令微调的数据选择对于提升大语言模型性能和降低训练成本至关重要,但现有方法存在不足。
- RICo通过上下文学习量化样本对任务和全局性能的细粒度贡献,从而更准确地选择高价值数据。
- 实验表明,使用RICo选择的少量数据训练的模型,性能显著优于使用全量数据和其他选择方法训练的模型。
📝 摘要(中文)
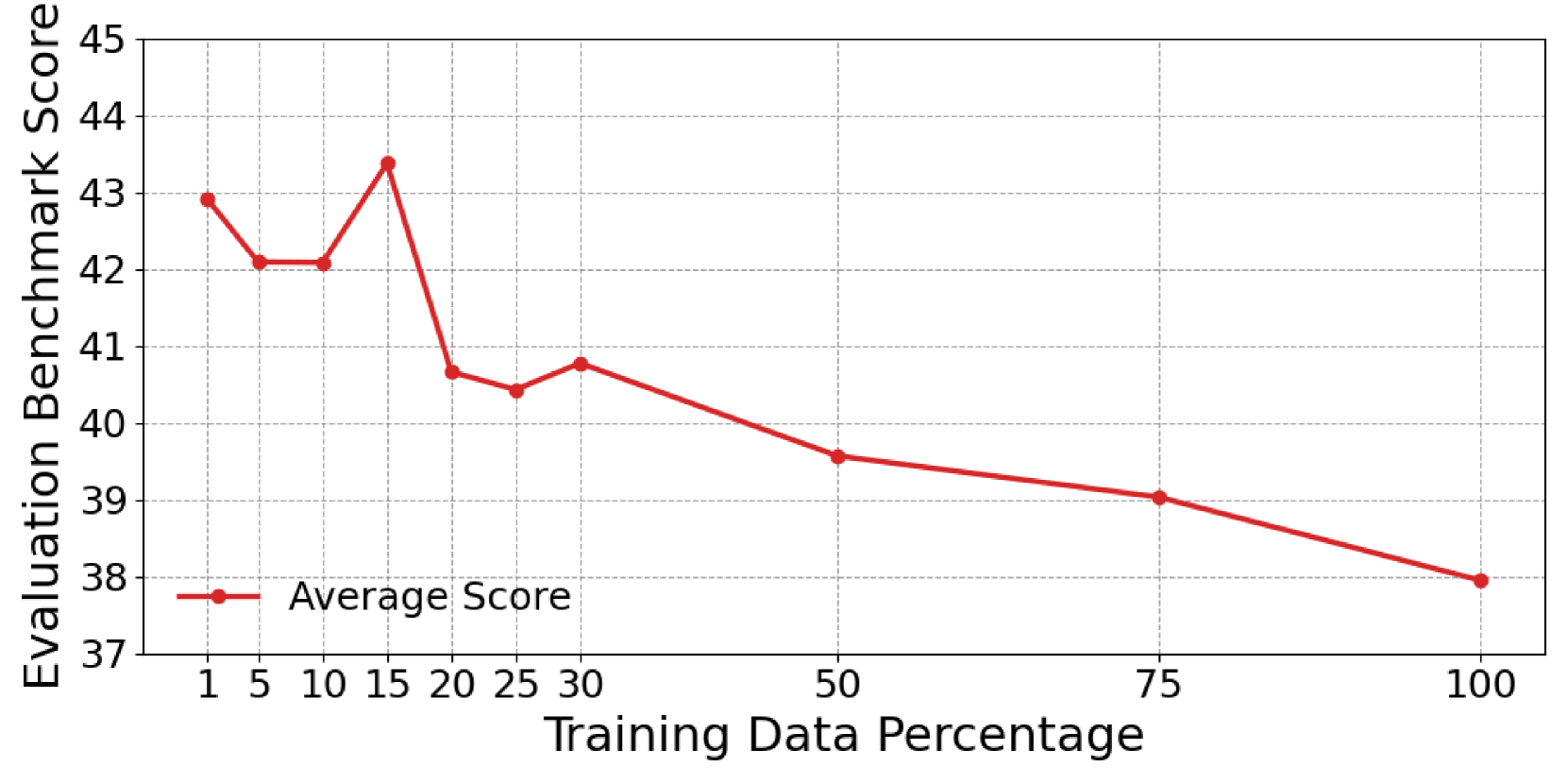
本文提出了一种名为RICo(Refined Contribution Measurement with In-Context Learning)的新型无梯度方法,用于指令微调的数据选择。RICo量化了单个样本对任务级和全局级模型性能的细粒度贡献,从而更准确地识别高贡献数据,实现更好的指令微调。此外,本文还引入了一种基于RICo分数训练的轻量级选择范式,实现了严格线性推理复杂度的可扩展数据选择。在三个大型语言模型、12个基准测试和5个成对评估集上的大量实验表明了RICo的有效性。值得注意的是,在LLaMA3.1-8B上,使用RICo选择的15%数据训练的模型,性能超过了使用完整数据集训练的模型5.42个百分点,并且超过了广泛使用的选择方法的最佳性能2.06个百分点。进一步分析表明,RICo选择的高贡献样本既包含多样化的任务,也包含适当的难度级别,而不仅仅是最难的样本。
🔬 方法详解
问题定义:指令微调的数据选择旨在从大量数据中挑选出对模型性能提升最有帮助的子集,以降低训练成本并提高效率。现有方法通常基于启发式规则或简单的评分机制,无法准确评估每个样本的真实贡献,导致选择的数据质量不高,影响模型性能。
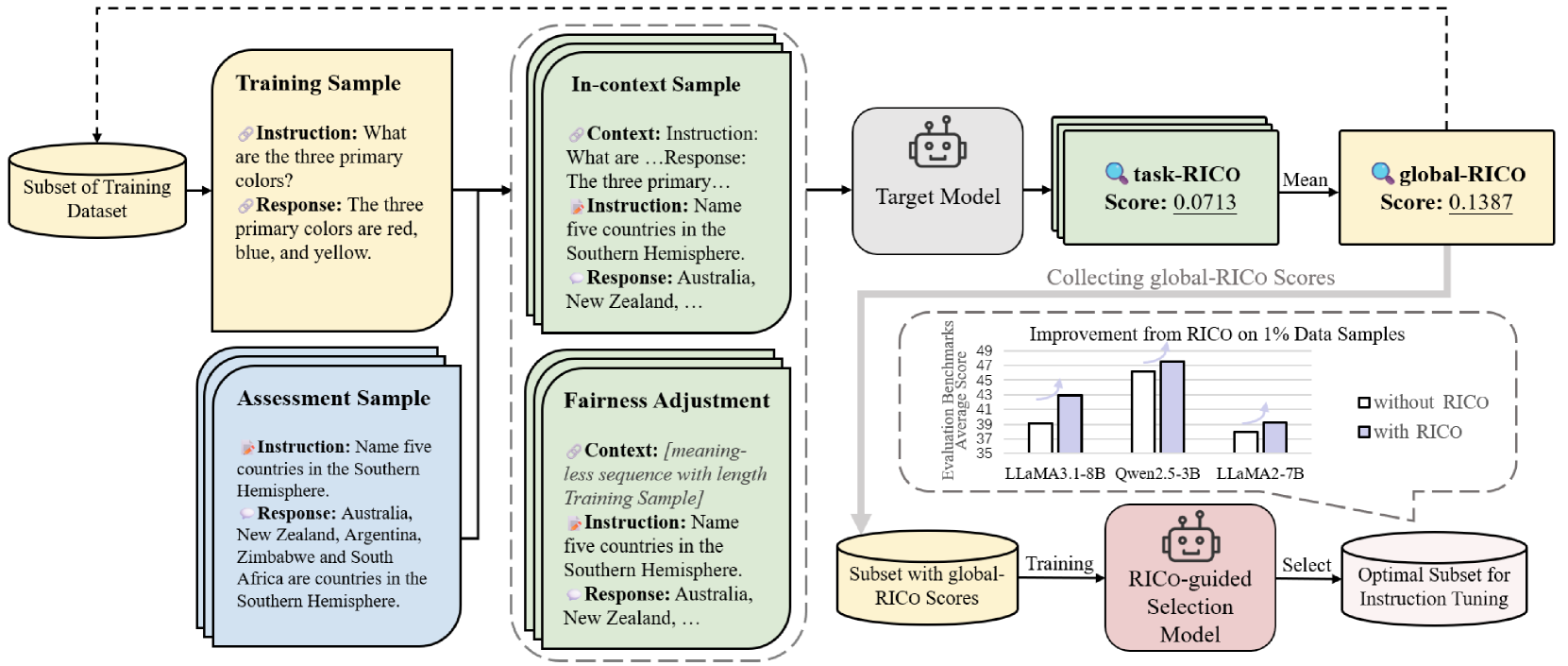
核心思路:RICo的核心思想是利用上下文学习(In-Context Learning)来评估每个样本对模型性能的贡献。具体来说,RICo通过构建包含目标样本的上下文提示,观察模型在给定提示下的表现,从而推断该样本对模型学习特定任务或提升整体性能的价值。这种方法避免了直接计算梯度,降低了计算复杂度。
技术框架:RICo主要包含两个阶段:1) 贡献度量阶段:使用上下文学习评估每个样本对任务级和全局级模型性能的贡献,得到RICo分数。2) 数据选择阶段:基于RICo分数,使用轻量级选择范式选择高贡献数据。该范式通过训练一个简单的线性模型来预测RICo分数,从而实现高效的数据选择。
关键创新:RICo的关键创新在于使用上下文学习来量化样本贡献。与传统的基于梯度或启发式规则的方法相比,RICo能够更准确地评估样本的真实价值,因为它直接考察了样本对模型在实际应用中的影响。此外,轻量级选择范式保证了数据选择过程的可扩展性。
关键设计:在贡献度量阶段,RICo使用不同的上下文提示来评估样本对任务级和全局级性能的贡献。任务级贡献通过在提示中包含任务描述和少量示例来评估,全局级贡献则通过在提示中包含多个不同任务的示例来评估。在数据选择阶段,线性模型的训练目标是最小化预测的RICo分数与真实RICo分数之间的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在LLaMA3.1-8B上,使用RICo选择的15%数据训练的模型,性能超过了使用完整数据集训练的模型5.42个百分点,并且超过了广泛使用的选择方法的最佳性能2.06个百分点。这表明RICo能够有效地选择高贡献数据,显著提升模型性能。
🎯 应用场景
RICo可应用于各种指令微调场景,尤其适用于资源受限的情况,例如在计算能力有限的设备上训练大型语言模型。通过选择高质量的训练数据,RICo可以显著降低训练成本,提高模型性能,并加速大语言模型在各个领域的应用,如智能客服、文本生成、机器翻译等。
📄 摘要(原文)
Data selection for instruction tuning is crucial for improving the performance of large language models (LLMs) while reducing training costs. In this paper, we propose Refined Contribution Measurement with In-Context Learning (RICo), a novel gradient-free method that quantifies the fine-grained contribution of individual samples to both task-level and global-level model performance. RICo enables more accurate identification of high-contribution data, leading to better instruction tuning. We further introduce a lightweight selection paradigm trained on RICo scores, enabling scalable data selection with a strictly linear inference complexity. Extensive experiments on three LLMs across 12 benchmarks and 5 pairwise evaluation sets demonstrate the effectiveness of RICo. Remarkably, on LLaMA3.1-8B, models trained on 15% of RICo-selected data outperform full datasets by 5.42% points and exceed the best performance of widely used selection methods by 2.06% points. We further analyze high-contribution samples selected by RICo, which show both diverse tasks and appropriate difficulty levels, rather than just the hardest ones.