A Benchmark Dataset and a Framework for Urdu Multimodal Named Entity Recognition
作者: Hussain Ahmad, Qingyang Zeng, Jing Wan
分类: cs.CL
发布日期: 2025-05-08
备注: 16 pages, 5 figures. Preprint
💡 一句话要点
提出U-MNER框架与Twitter2015-Urdu数据集,推进乌尔都语多模态命名实体识别研究。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态命名实体识别 乌尔都语 低资源语言 跨模态融合 Urdu-BERT ResNet Twitter2015-Urdu数据集
📋 核心要点
- 多模态命名实体识别在低资源语言(如乌尔都语)中面临数据集稀缺和基线不足的挑战。
- U-MNER框架通过结合Urdu-BERT文本嵌入和ResNet视觉特征,利用跨模态融合模块对齐信息。
- Twitter2015-Urdu数据集上的实验表明,该模型性能优越,为低资源语言MNER研究奠定基础。
📝 摘要(中文)
本文针对自然语言处理中日益重要的多模态命名实体识别(MNER)任务,特别是文本和图像结合的社交媒体内容,关注了乌尔都语等低资源语言在此领域的欠探索现状。主要挑战在于缺乏带标注的多模态数据集和标准化的基线。为解决这些问题,我们提出了U-MNER框架,并发布了Twitter2015-Urdu数据集,这是首个乌尔都语MNER资源。该数据集改编自广泛使用的Twitter2015数据集,并根据乌尔都语语法规则进行了标注。我们通过在该数据集上评估基于文本和多模态的模型,建立了基准线,为未来的乌尔都语MNER研究提供比较分析。U-MNER框架利用Urdu-BERT进行文本嵌入,ResNet提取视觉特征,并通过跨模态融合模块对齐和融合信息。我们的模型在Twitter2015-Urdu数据集上实现了最先进的性能,为低资源语言的MNER研究奠定了基础。
🔬 方法详解
问题定义:本文旨在解决乌尔都语多模态命名实体识别(MNER)任务中数据集匮乏和缺乏基准模型的问题。现有方法在处理低资源语言时,由于缺乏高质量的标注数据和针对性的模型设计,难以取得理想的效果。这限制了乌尔都语等多模态信息处理的发展。
核心思路:核心思路是构建一个高质量的乌尔都语MNER数据集,并设计一个能够有效融合文本和图像信息的模型。通过迁移学习的思想,利用已有的英文数据集的结构,并结合乌尔都语的特点进行标注,从而降低数据标注的成本。同时,设计跨模态融合模块,使得模型能够充分利用文本和图像的互补信息。
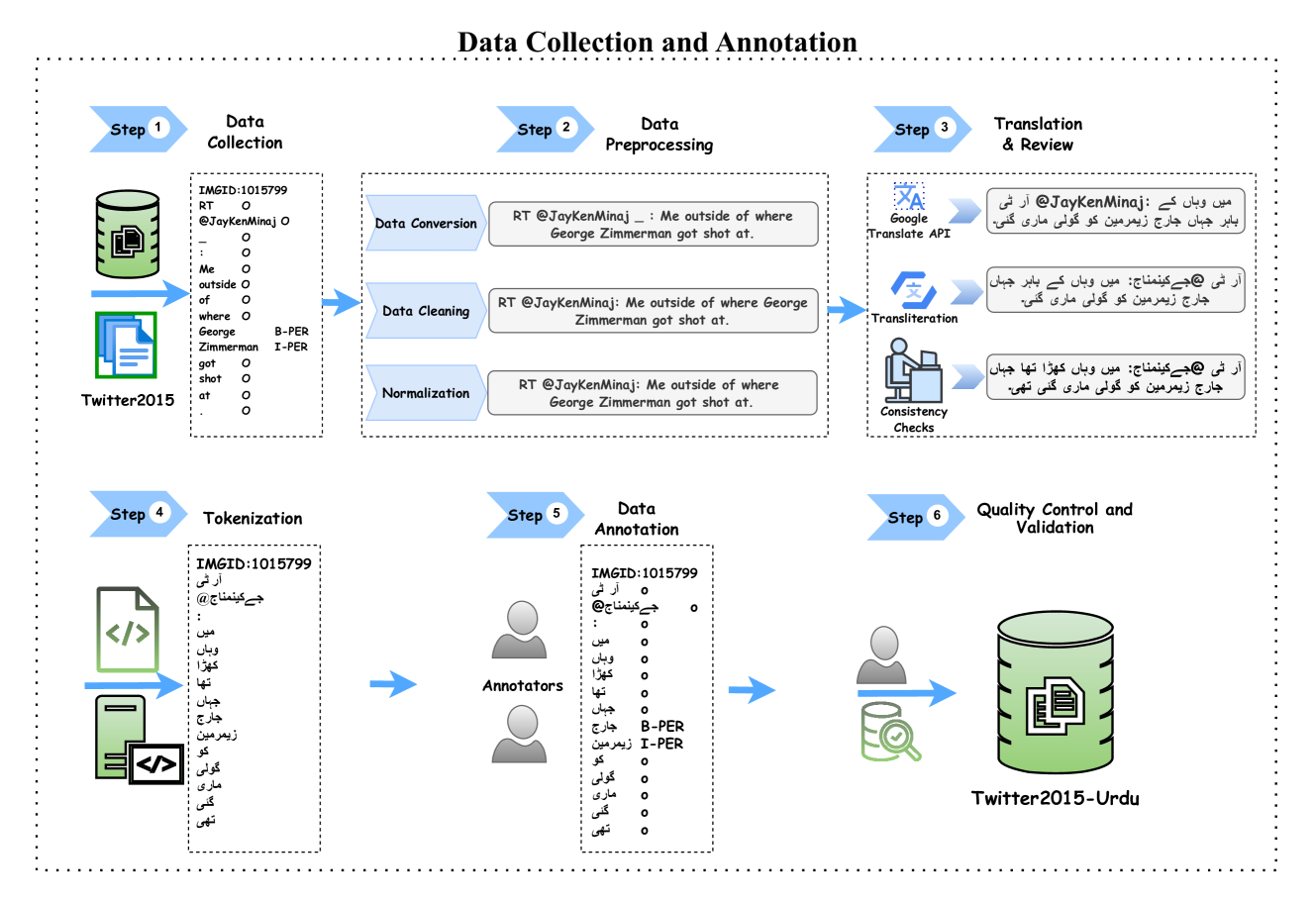
技术框架:U-MNER框架主要包含三个模块:文本特征提取模块、视觉特征提取模块和跨模态融合模块。文本特征提取模块使用Urdu-BERT模型,将文本信息转换为向量表示。视觉特征提取模块使用ResNet模型,提取图像的视觉特征。跨模态融合模块负责将文本和图像特征进行对齐和融合,最终输出命名实体识别的结果。
关键创新:主要创新点在于构建了首个乌尔都语MNER数据集Twitter2015-Urdu,并提出了一个有效的跨模态融合模块。该模块能够自适应地学习文本和图像特征的权重,从而更好地融合多模态信息。与现有方法相比,U-MNER框架更适用于低资源语言的MNER任务。
关键设计:在文本特征提取方面,使用了预训练的Urdu-BERT模型,并针对乌尔都语的特点进行了微调。在视觉特征提取方面,使用了在ImageNet上预训练的ResNet模型。在跨模态融合模块中,使用了注意力机制,学习文本和图像特征的权重。损失函数使用了交叉熵损失函数,优化目标是最小化预测结果与真实标签之间的差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,U-MNER框架在Twitter2015-Urdu数据集上取得了state-of-the-art的性能。相较于仅使用文本信息的模型,U-MNER框架能够显著提升命名实体识别的准确率和召回率。具体的性能数据和对比基线信息在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于社交媒体舆情分析、信息安全监控、智能客服等领域。通过识别社交媒体上的乌尔都语文本和图像中的命名实体,可以更好地理解用户意图、发现潜在风险,并提供个性化服务。未来,该研究可扩展到其他低资源语言,促进多语言多模态信息处理的发展。
📄 摘要(原文)
The emergence of multimodal content, particularly text and images on social media, has positioned Multimodal Named Entity Recognition (MNER) as an increasingly important area of research within Natural Language Processing. Despite progress in high-resource languages such as English, MNER remains underexplored for low-resource languages like Urdu. The primary challenges include the scarcity of annotated multimodal datasets and the lack of standardized baselines. To address these challenges, we introduce the U-MNER framework and release the Twitter2015-Urdu dataset, a pioneering resource for Urdu MNER. Adapted from the widely used Twitter2015 dataset, it is annotated with Urdu-specific grammar rules. We establish benchmark baselines by evaluating both text-based and multimodal models on this dataset, providing comparative analyses to support future research on Urdu MNER. The U-MNER framework integrates textual and visual context using Urdu-BERT for text embeddings and ResNet for visual feature extraction, with a Cross-Modal Fusion Module to align and fuse information. Our model achieves state-of-the-art performance on the Twitter2015-Urdu dataset, laying the groundwork for further MNER research in low-resource languages.