Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders
作者: Boyi Deng, Yu Wan, Yidan Zhang, Baosong Yang, Fuli Feng
分类: cs.CL
发布日期: 2025-05-08 (更新: 2025-05-27)
备注: ACL 2025 main
🔗 代码/项目: GITHUB
💡 一句话要点
利用稀疏自编码器揭示大型语言模型中的语言特定特征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多语言能力 稀疏自编码器 特征提取 单语性 消融实验 steering vectors
📋 核心要点
- 现有方法在分析LLM多语言能力时,受限于神经元叠加和层间激活差异,难以准确识别语言特定机制。
- 论文提出使用稀疏自编码器分解LLM激活,提取更具区分性的语言特征,并设计指标评估特征的单语性。
- 实验表明,消融特定语言的SAE特征会显著降低LLM在该语言上的能力,且可利用这些特征增强steering vectors以控制生成语言。
📝 摘要(中文)
本文研究了大型语言模型(LLM)中多语言能力背后的机制,以往的研究通常基于神经元或内部激活,但面临叠加和层间激活差异等挑战,限制了其可靠性。本文提出使用稀疏自编码器(SAE)来分解LLM的激活,将其表示为SAE特征的稀疏线性组合,从而进行更细致的分析。我们引入了一种新的指标来评估SAE特征的单语性,发现一些特征与特定语言密切相关。此外,我们证明了消融这些SAE特征只会显著降低LLM在一种语言上的能力,而几乎不影响其他语言。有趣的是,我们发现一些语言具有多个协同的SAE特征,同时消融它们比单独消融效果更好。此外,我们利用这些SAE导出的语言特定特征来增强steering vectors,从而控制LLM生成的语言。代码已公开。
🔬 方法详解
问题定义:大型语言模型(LLM)展现出强大的多语言能力,但其内部机制尚不明确。现有的基于神经元或内部激活的方法,由于神经元叠加现象和层间激活差异,难以准确识别和分离不同语言对应的特征,从而限制了对LLM多语言能力的深入理解和有效控制。
核心思路:本文的核心思路是利用稀疏自编码器(SAE)来分解LLM的内部激活,将复杂的激活模式表示为一组稀疏的、更易于解释的特征的线性组合。通过分析这些SAE特征,可以更清晰地识别与特定语言相关的特征,并进一步研究这些特征在LLM多语言能力中的作用。这种方法旨在克服神经元叠加和层间激活差异带来的挑战,提供更可靠的分析结果。
技术框架:整体框架包括以下几个主要步骤:1) 使用LLM处理多语言文本,获取内部激活数据;2) 使用SAE对这些激活数据进行训练,得到一组稀疏特征;3) 设计新的指标来评估每个SAE特征的单语性,即该特征与特定语言的关联程度;4) 通过消融实验,验证特定语言的SAE特征对LLM在该语言上的性能影响;5) 利用识别出的语言特定特征来增强steering vectors,从而控制LLM生成的语言。
关键创新:最重要的技术创新点在于使用SAE来分解LLM的激活,并提出了一种新的单语性指标。与直接分析神经元激活相比,SAE能够提取更具区分性的特征,从而更好地分离不同语言的信息。此外,通过消融实验和steering vectors控制,验证了这些语言特定特征的有效性。
关键设计:SAE的训练目标是最小化重构误差,同时鼓励特征的稀疏性。具体来说,损失函数通常包括重构损失(例如均方误差)和稀疏性惩罚项(例如L1正则化)。单语性指标的设计需要考虑如何量化一个SAE特征与特定语言的关联程度,例如可以基于该特征在不同语言文本上的激活强度差异来计算。steering vectors的增强方法需要仔细设计,以确保能够有效地控制LLM生成的语言,同时避免引入不必要的副作用。
🖼️ 关键图片
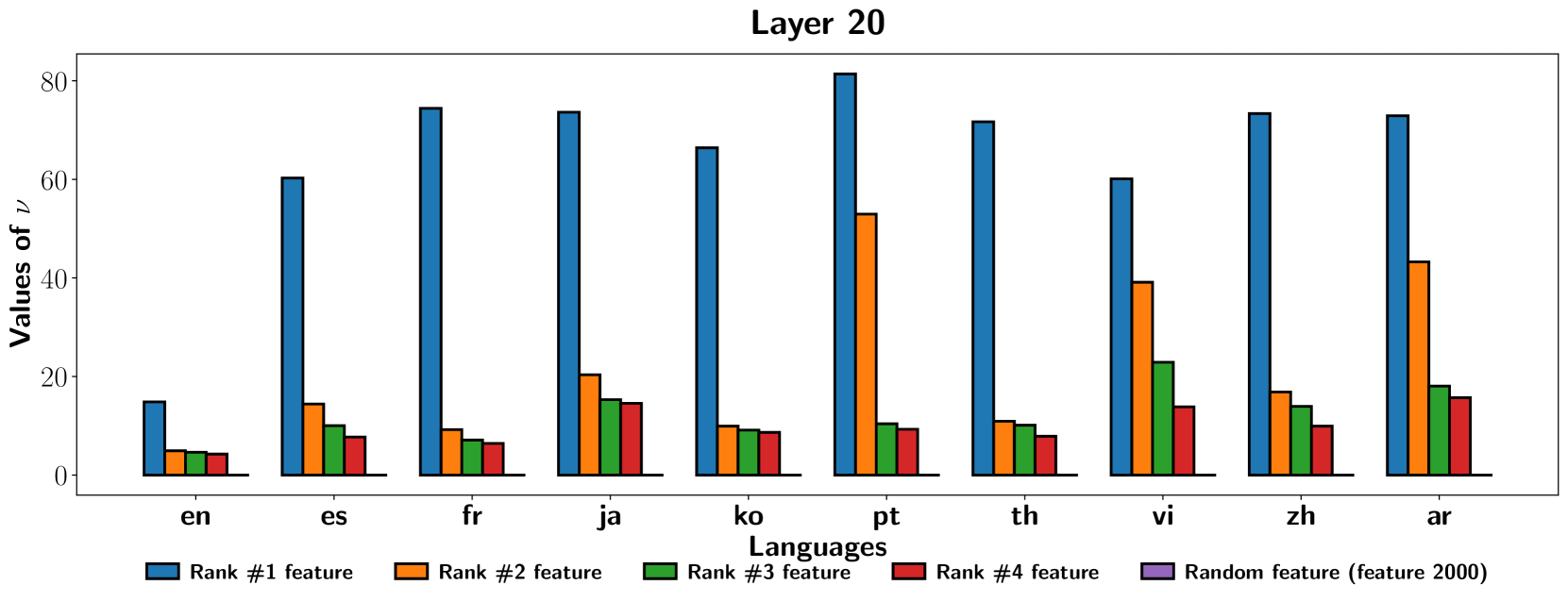
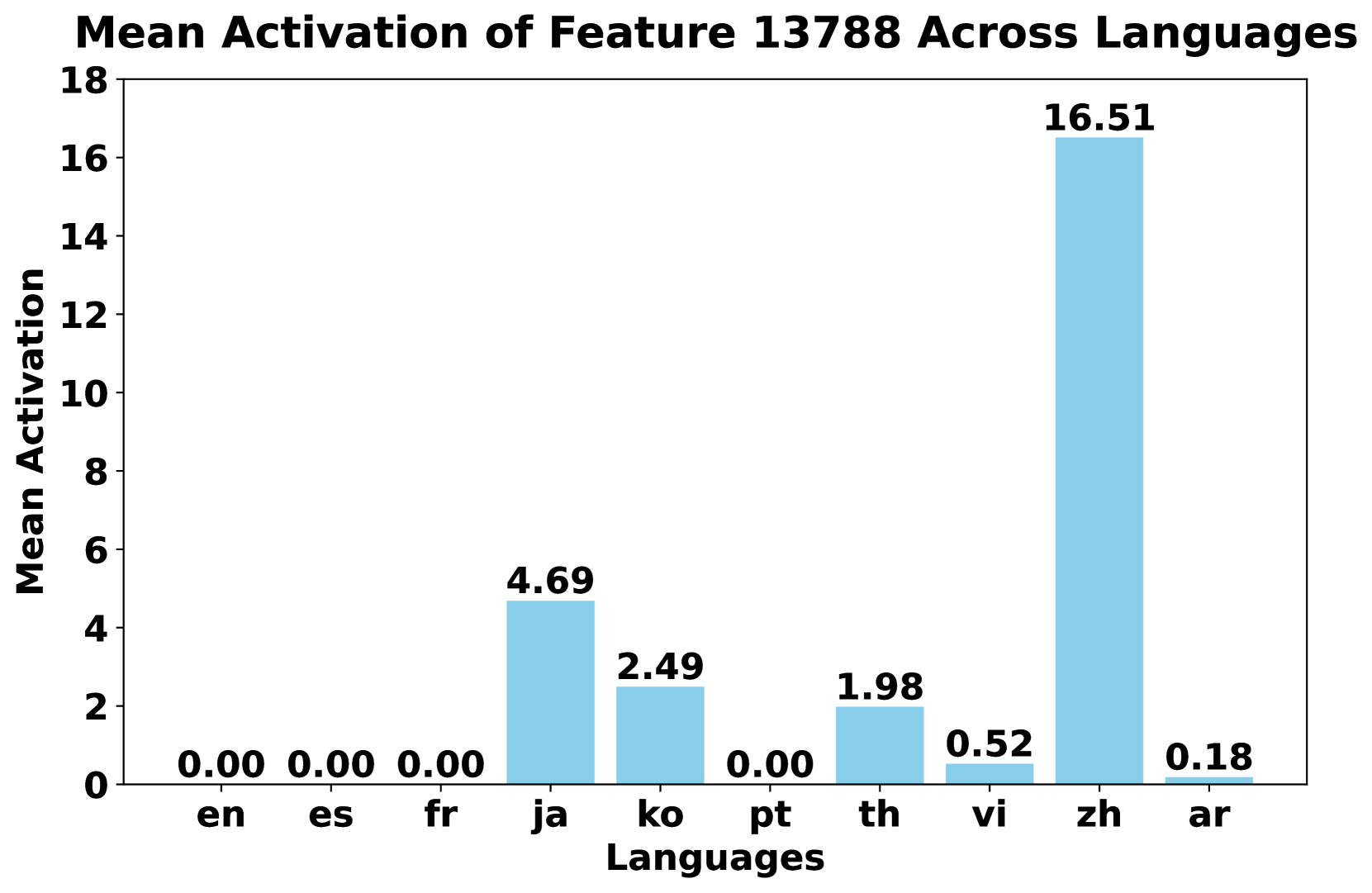
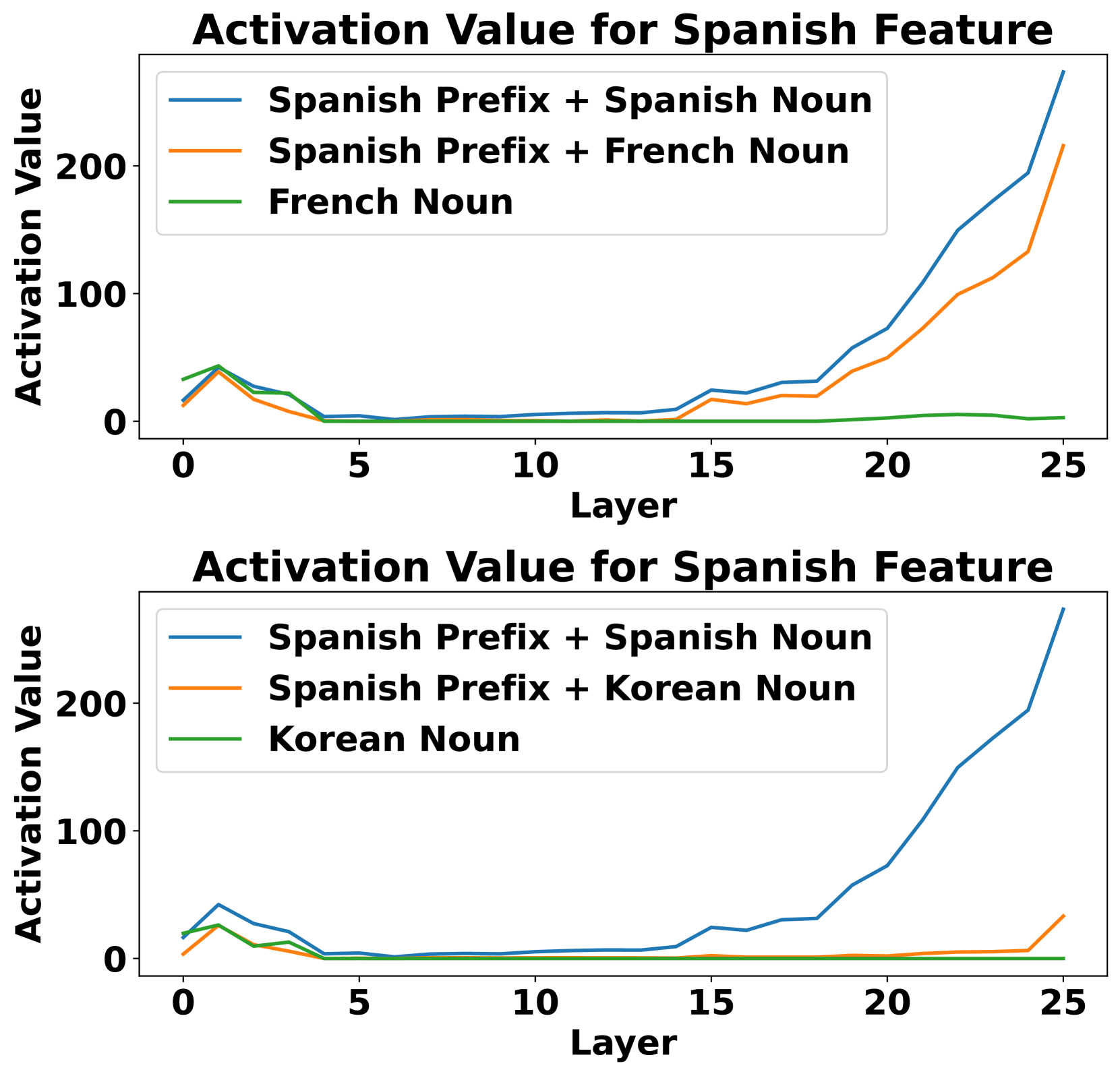
📊 实验亮点
实验结果表明,消融特定语言的SAE特征会显著降低LLM在该语言上的性能,而对其他语言的影响较小。例如,消融与中文相关的SAE特征后,LLM在中文任务上的表现明显下降,而在英文任务上的表现几乎没有变化。此外,利用SAE导出的语言特定特征增强steering vectors,可以有效控制LLM生成的语言。
🎯 应用场景
该研究成果可应用于提升多语言LLM的性能和可控性,例如,可以根据用户需求调整LLM的语言偏好,生成特定语言的内容。此外,该方法还可以用于分析和比较不同LLM的多语言能力,为模型改进提供指导。未来,该研究或可扩展到其他模态,例如多语言语音识别和翻译。
📄 摘要(原文)
The mechanisms behind multilingual capabilities in Large Language Models (LLMs) have been examined using neuron-based or internal-activation-based methods. However, these methods often face challenges such as superposition and layer-wise activation variance, which limit their reliability. Sparse Autoencoders (SAEs) offer a more nuanced analysis by decomposing the activations of LLMs into a sparse linear combination of SAE features. We introduce a novel metric to assess the monolinguality of features obtained from SAEs, discovering that some features are strongly related to specific languages. Additionally, we show that ablating these SAE features only significantly reduces abilities in one language of LLMs, leaving others almost unaffected. Interestingly, we find some languages have multiple synergistic SAE features, and ablating them together yields greater improvement than ablating individually. Moreover, we leverage these SAE-derived language-specific features to enhance steering vectors, achieving control over the language generated by LLMs. The code is publicly available at https://github.com/Aatrox103/multilingual-llm-features.