Do MLLMs Capture How Interfaces Guide User Behavior? A Benchmark for Multimodal UI/UX Design Understanding
作者: Jaehyun Jeon, Min Soo Kim, Jang Han Yoon, Sumin Shim, Yejin Choi, Hanbin Kim, Dae Hyun Kim, Youngjae Yu
分类: cs.CL, cs.LG
发布日期: 2025-05-08 (更新: 2026-01-11)
备注: 25 pages, 24 figures, Our code and dataset: https://github.com/jeochris/wiserui-bench
💡 一句话要点
提出WiserUI-Bench基准,评估MLLM在理解UI/UX设计对用户行为影响方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 用户界面设计 用户体验 A/B测试 基准数据集 用户行为分析 视觉设计 事后解释
📋 核心要点
- 现有MLLM在UI评估中侧重表面特征,未能深入理解UI/UX设计对用户行为的深远影响。
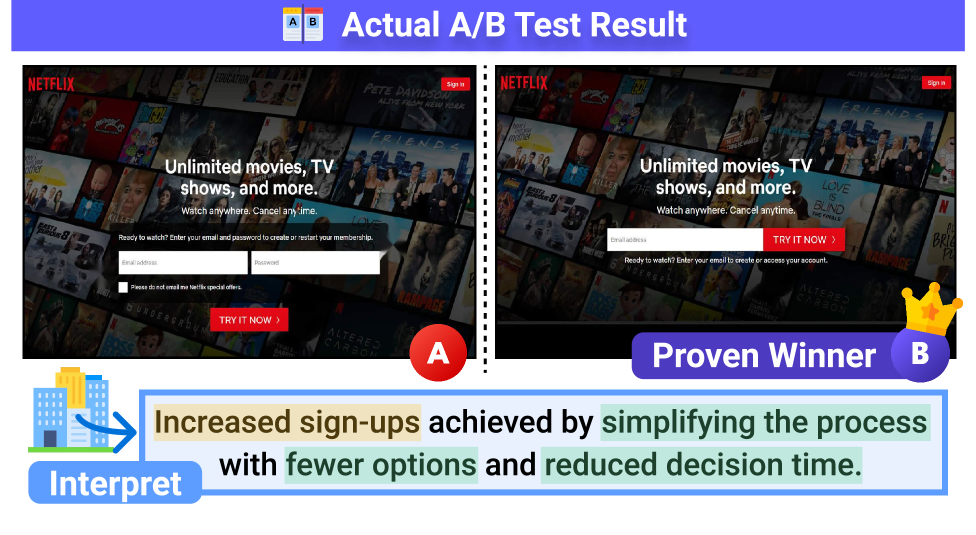
- 论文构建WiserUI-Bench基准,包含真实A/B测试的UI图像对,并提供专家解释,用于评估MLLM对用户行为影响的理解。
- 实验表明,现有MLLM在预测更有效的UI设计和提供合理事后解释方面表现有限,揭示了其在UI/UX理解上的不足。
📝 摘要(中文)
用户界面(UI)设计不仅仅是视觉呈现,更塑造用户体验(UX),UI/UX正朝着统一概念发展。现有研究利用多模态大语言模型(MLLM)进行UI评估,但主要关注表面特征,忽略了设计选择如何大规模影响用户行为。为了填补这一空白,我们提出了WiserUI-Bench,这是一个新颖的基准,用于多模态理解UI/UX设计如何影响用户行为。该基准基于来自行业A/B测试的300个真实UI图像对,并包含经验证的、能诱导更多用户行为的胜出设计。为了促进实践中未来的设计进展,还需要对这些胜出设计为何能成功吸引大量用户进行事后理解;我们通过专家策划的每个实例的关键解释来支持这一点。在WiserUI-Bench上对多个MLLM进行的实验,包括预测A/B测试对中更有效的UI图像,以及与专家解释一致的事后解释,表明模型对UI/UX设计对行为的影响理解有限。我们相信我们的工作将促进利用MLLM进行用户行为背景下的视觉设计研究。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在理解用户界面(UI)和用户体验(UX)设计如何影响用户行为方面的不足。现有方法主要关注UI的表面视觉特征,缺乏对设计选择如何驱动用户行为的深入理解,无法解释为何某些设计在A/B测试中表现更好。
核心思路:论文的核心思路是构建一个高质量的基准数据集,用于评估MLLM在理解UI/UX设计对用户行为影响方面的能力。通过提供真实世界的A/B测试UI图像对,并结合专家对胜出设计的解释,可以更全面地评估MLLM的推理和解释能力。这种方法旨在推动MLLM在视觉设计和用户行为分析方面的研究进展。
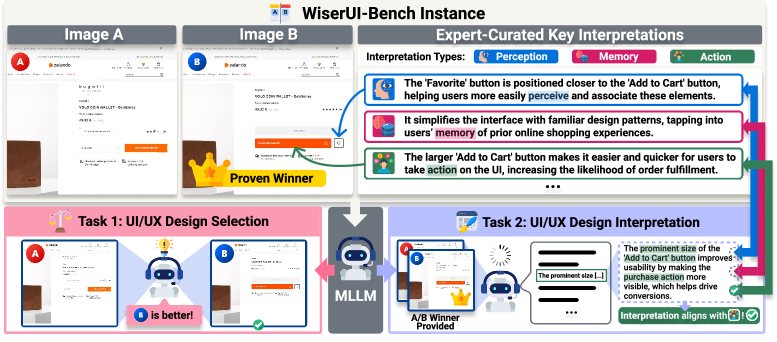
技术框架:WiserUI-Bench基准包含以下几个关键组成部分:1) 从实际A/B测试中收集的300个UI图像对,每个图像对包含两个不同的UI设计;2) 经验证的胜出设计,即在A/B测试中表现更好的UI;3) 专家策划的解释,用于解释胜出设计为何能更有效地引导用户行为。评估任务包括:1) 预测任务,即给定一个UI图像对,MLLM需要预测哪个设计更有效;2) 解释任务,即MLLM需要提供对胜出设计有效性的解释,并与专家解释进行比较。
关键创新:该论文的关键创新在于构建了一个专门用于评估MLLM在UI/UX设计理解方面的基准数据集。与现有UI评估数据集相比,WiserUI-Bench更注重设计选择对用户行为的影响,并提供了专家解释作为ground truth,从而可以更全面地评估MLLM的推理和解释能力。此外,该基准基于真实世界的A/B测试数据,更贴近实际应用场景。
关键设计:WiserUI-Bench的数据集构建过程包括:1) 从行业合作伙伴收集A/B测试数据;2) 对数据进行清洗和预处理,确保图像质量和标注准确性;3) 邀请UI/UX专家对每个UI图像对进行分析,并提供对胜出设计有效性的解释。评估指标包括预测准确率和解释一致性。具体而言,解释一致性通过计算MLLM生成的解释与专家解释之间的语义相似度来衡量,例如使用BLEU或ROUGE等指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有MLLM在WiserUI-Bench基准上的表现远低于人类水平,预测准确率和解释一致性均有待提高。例如,在预测任务中,最佳MLLM的准确率仅为60%左右,与人类专家的85%相比仍有较大差距。这表明MLLM在理解UI/UX设计对用户行为的影响方面仍存在显著不足,为未来的研究提供了明确的方向。
🎯 应用场景
该研究成果可应用于自动化UI/UX设计评估、智能设计辅助工具、用户行为预测和个性化推荐系统等领域。通过利用MLLM理解UI/UX设计对用户行为的影响,可以帮助设计师更高效地创建更具吸引力和用户友好的界面,提升用户体验和业务指标。未来,该研究可扩展到更复杂的交互设计和跨平台用户体验分析。
📄 摘要(原文)
User interface (UI) design goes beyond visuals to shape user experience (UX), underscoring the shift toward UI/UX as a unified concept. While recent studies have explored UI evaluation using Multimodal Large Language Models (MLLMs), they largely focus on surface-level features, overlooking how design choices influence user behavior at scale. To fill this gap, we introduce WiserUI-Bench, a novel benchmark for multimodal understanding of how UI/UX design affects user behavior, built on 300 real-world UI image pairs from industry A/B tests, with empirically validated winners that induced more user actions. For future design progress in practice, post-hoc understanding of why such winners succeed with mass users is also required; we support this via expert-curated key interpretations for each instance. Experiments across multiple MLLMs on WiserUI-Bench for two main tasks, (1) predicting the more effective UI image between an A/B-tested pair, and (2) explaining it post-hoc in alignment with expert interpretations, show that models exhibit limited understanding of the behavioral impact of UI/UX design. We believe our work will foster research on leveraging MLLMs for visual design in user behavior contexts.