Joint Detection of Fraud and Concept Drift inOnline Conversations with LLM-Assisted Judgment
作者: Ali Senol, Garima Agrawal, Huan Liu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-07
💡 一句话要点
提出LLM辅助的欺诈和概念漂移联合检测框架,用于在线对话场景
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线欺诈检测 概念漂移 大型语言模型 集成学习 社交工程
📋 核心要点
- 现有在线对话欺诈检测方法难以适应动态对话,易将正常话题转移误判为欺诈。
- 提出两阶段框架,先用集成模型检测可疑对话,再用LLM判断概念漂移是否为欺诈。
- 实验表明,该框架提高了欺诈检测的准确性和可解释性,优于双LLM基线。
📝 摘要(中文)
检测数字通信平台中的虚假互动仍然是一个具有挑战性且未被充分解决的问题。这些互动可能表现为无害的垃圾信息,或升级为复杂的诈骗尝试,难以尽早标记恶意意图。传统检测方法通常依赖于静态异常检测技术,无法适应动态的对话转变。一个关键的限制是将良性的话题转换(称为概念漂移)误解为欺诈行为,导致误报或漏报。我们提出了一个两阶段检测框架,首先使用定制的集成分类模型识别可疑对话。为了提高检测的可靠性,我们结合了概念漂移分析步骤,使用单类漂移检测器(OCDD)来隔离标记对话中的对话转变。当检测到漂移时,大型语言模型(LLM)评估该转变是否表明欺诈性操纵或合法的话题变化。在未发现漂移的情况下,该行为被推断为类似垃圾信息。我们使用社交工程聊天场景数据集验证了我们的框架,并证明了其在提高实时欺诈检测的准确性和可解释性方面的实际优势。为了说明权衡,我们将我们的模块化方法与使用不同语言模型执行检测和判断的双LLM基线进行了比较。
🔬 方法详解
问题定义:在线对话欺诈检测面临的挑战是,对话内容会随着时间发生变化,即存在概念漂移。传统方法难以区分正常的话题转移和欺诈者有意为之的操纵性话题转移,导致较高的误报率和漏报率。现有方法缺乏对概念漂移的有效建模和利用,无法准确识别欺诈行为。
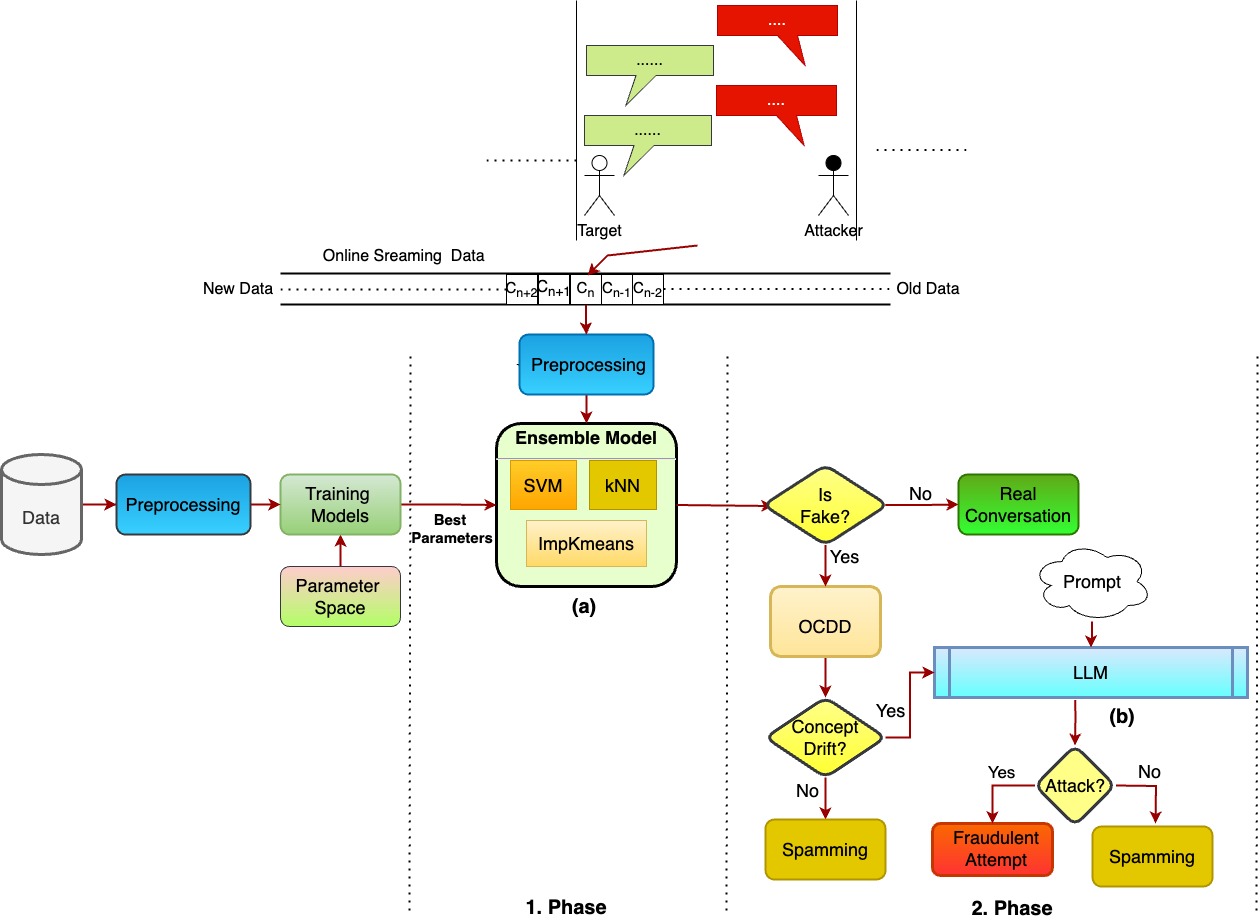
核心思路:论文的核心思路是利用大型语言模型(LLM)的语义理解能力,辅助判断概念漂移的性质。首先,使用传统的机器学习方法初步筛选出可疑的对话。然后,利用单类漂移检测器(OCDD)检测对话中是否存在概念漂移。最后,如果检测到概念漂移,则使用LLM判断该漂移是良性的还是欺诈性的。如果未检测到漂移,则直接判定为垃圾信息。
技术框架:该框架包含两个主要阶段:1) 可疑对话检测:使用定制的集成分类模型,对对话进行初步筛选,识别出可能存在欺诈行为的对话。2) 概念漂移分析与LLM辅助判断:使用单类漂移检测器(OCDD)检测可疑对话中是否存在概念漂移。如果检测到漂移,则使用LLM对漂移的性质进行判断,区分良性话题转移和欺诈性操纵。如果未检测到漂移,则直接判定为垃圾信息。
关键创新:该论文的关键创新在于将概念漂移分析与LLM的语义理解能力相结合,用于在线对话欺诈检测。传统方法通常忽略概念漂移,或者简单地将其视为异常。该论文提出的方法能够区分不同类型的概念漂移,从而更准确地识别欺诈行为。此外,使用LLM进行判断,可以提高检测的可解释性。
关键设计:在集成分类模型中,使用了多种不同的分类器,并采用投票的方式进行决策。单类漂移检测器(OCDD)使用历史数据训练一个单类分类器,然后使用该分类器检测新的数据点是否与历史数据分布不同。LLM的使用方式是,将对话内容和漂移发生前后的上下文输入LLM,然后让LLM判断该漂移是良性的还是欺诈性的。具体的LLM选择和prompt设计未知。
🖼️ 关键图片

📊 实验亮点
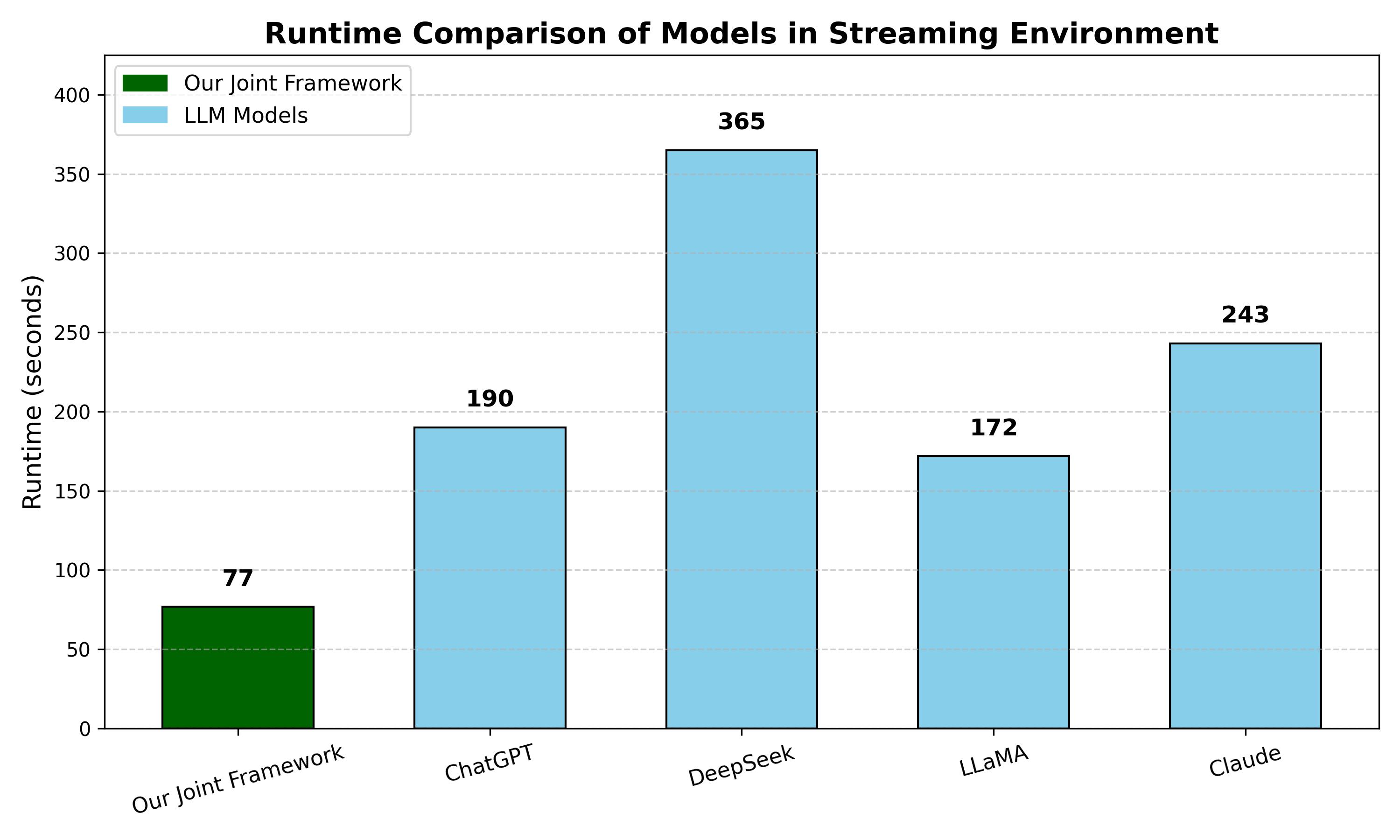
实验结果表明,该框架在社交工程聊天场景数据集上取得了良好的效果,提高了欺诈检测的准确性和可解释性。与双LLM基线相比,该框架在性能上具有优势,并且能够提供更清晰的判断依据。具体的性能数据未知,但论文强调了该方法在实际应用中的优势。
🎯 应用场景
该研究成果可应用于各种在线社交平台、电商平台和客户服务系统,用于实时检测和阻止欺诈行为,保护用户免受经济损失和声誉损害。通过提高欺诈检测的准确性和可解释性,可以有效减少误报和漏报,提升用户体验和平台安全性。未来可扩展到其他类型的在线欺诈检测,例如虚假评论和恶意账号。
📄 摘要(原文)
Detecting fake interactions in digital communication platforms remains a challenging and insufficiently addressed problem. These interactions may appear as harmless spam or escalate into sophisticated scam attempts, making it difficult to flag malicious intent early. Traditional detection methods often rely on static anomaly detection techniques that fail to adapt to dynamic conversational shifts. One key limitation is the misinterpretation of benign topic transitions referred to as concept drift as fraudulent behavior, leading to either false alarms or missed threats. We propose a two stage detection framework that first identifies suspicious conversations using a tailored ensemble classification model. To improve the reliability of detection, we incorporate a concept drift analysis step using a One Class Drift Detector (OCDD) to isolate conversational shifts within flagged dialogues. When drift is detected, a large language model (LLM) assesses whether the shift indicates fraudulent manipulation or a legitimate topic change. In cases where no drift is found, the behavior is inferred to be spam like. We validate our framework using a dataset of social engineering chat scenarios and demonstrate its practical advantages in improving both accuracy and interpretability for real time fraud detection. To contextualize the trade offs, we compare our modular approach against a Dual LLM baseline that performs detection and judgment using different language models.