SOAEsV2-7B/72B: Full-Pipeline Optimization for State-Owned Enterprise LLMs via Continual Pre-Training, Domain-Progressive SFT and Distillation-Enhanced Speculative Decoding
作者: Jingyang Deng, Ran Chen, Jo-Ku Cheng, Jinwen Ma
分类: cs.CL
发布日期: 2025-05-07
💡 一句话要点
SOAEsV2-7B/72B:面向国资企业的全流程优化大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 领域特定模型 持续预训练 监督微调 知识蒸馏 推测解码 国资企业
📋 核心要点
- 现有领域大模型面临模型容量限制、过度依赖领域数据以及推理效率低下的问题。
- SOAEsV2通过持续预训练、领域渐进式SFT和蒸馏增强推测解码,实现领域知识融合和推理加速。
- 实验表明,该方法在保持通用能力的同时显著提升领域性能,并加速推理过程。
📝 摘要(中文)
本研究旨在解决为中国国资企业开发领域特定大语言模型(LLM)的关键挑战。现有方法存在三个局限性:1)模型容量受限,限制了知识整合和跨任务适应性;2)过度依赖领域特定的监督微调(SFT)数据,忽略了通用语言模式的广泛适用性;3)大型模型处理长上下文时推理加速效率低下。为此,我们提出了SOAEsV2-7B/72B,一个通过三阶段框架开发的专业LLM系列:1)持续预训练整合领域知识,同时保留基础能力;2)领域渐进式SFT采用基于课程的学习策略,从弱相关对话数据过渡到专家标注的SOAEs数据集,以优化领域特定任务;3)蒸馏增强推测解码通过72B目标模型和7B草稿模型之间的logit蒸馏来加速推理,在不损失质量的情况下实现1.39-1.52倍的加速。实验结果表明,我们的领域特定预训练阶段保持了99.8%的原始通用语言能力,同时显著提高了领域性能,Rouge-1得分提高了1.08倍,BLEU-4得分提高了1.17倍。消融研究进一步表明,领域渐进式SFT优于单阶段训练,Rouge-1提高了1.02倍,BLEU-4提高了1.06倍。我们的工作为优化SOAEs LLM 引入了一种全面的全流程方法,弥合了通用语言能力和领域特定专业知识之间的差距。
🔬 方法详解
问题定义:论文旨在解决为中国国资企业(SOAEs)定制大语言模型时面临的挑战。现有方法的痛点在于:模型容量不足以有效整合领域知识,过度依赖领域特定数据导致泛化能力受限,以及大型模型推理效率低下,难以处理长文本上下文。
核心思路:论文的核心思路是通过一个三阶段的全流程优化框架,在保留通用语言能力的基础上,逐步注入领域知识,并利用蒸馏技术加速推理过程。这种方法旨在平衡通用性和专业性,提高模型在特定领域的实用性。
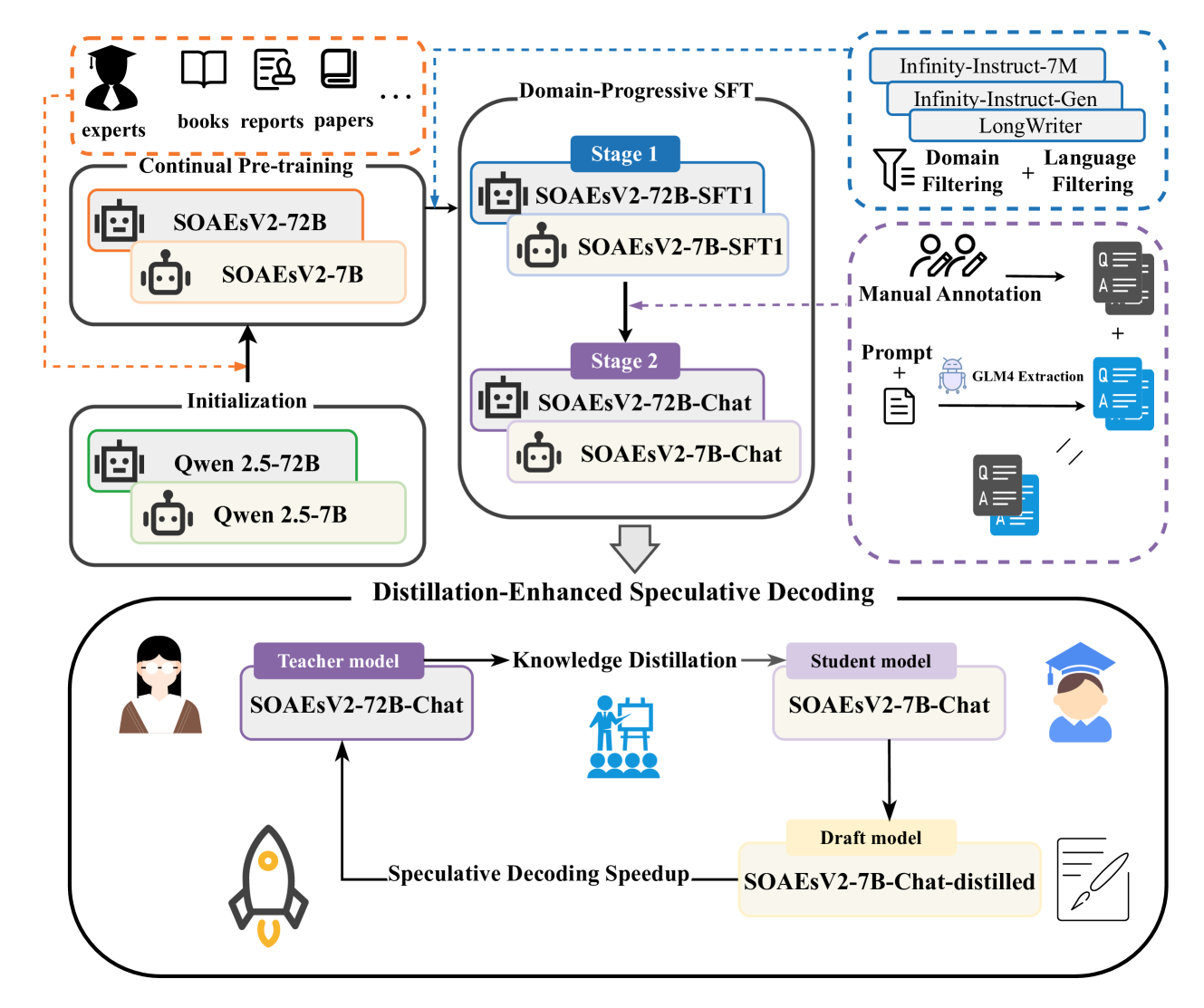
技术框架:SOAEsV2的整体框架包含三个主要阶段:1) 持续预训练:在通用预训练模型的基础上,使用领域相关数据进行持续预训练,以融入领域知识。2) 领域渐进式SFT:采用课程学习策略,从通用对话数据逐步过渡到专家标注的SOAEs数据集进行监督微调,优化领域特定任务。3) 蒸馏增强推测解码:使用72B模型作为教师模型,7B模型作为学生模型,通过logit蒸馏进行知识迁移,并利用推测解码加速推理过程。
关键创新:该论文的关键创新在于提出了一个全流程的优化框架,将持续预训练、领域渐进式SFT和蒸馏增强推测解码相结合,从而在提升领域性能的同时,保持了模型的通用语言能力和推理效率。领域渐进式SFT策略也是一个重要的创新点,它通过课程学习的方式,逐步引导模型学习领域知识,避免了直接在领域数据上微调可能导致的灾难性遗忘问题。
关键设计:在持续预训练阶段,选择合适的领域数据至关重要,需要平衡数据的质量和数量。在领域渐进式SFT阶段,需要精心设计课程,确定不同阶段的数据选择和训练策略。在蒸馏增强推测解码阶段,需要选择合适的蒸馏损失函数和温度参数,以保证知识迁移的有效性,并避免学生模型过度拟合教师模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SOAEsV2在保持99.8%通用语言能力的同时,显著提升了领域性能,Rouge-1得分提高了1.08倍,BLEU-4得分提高了1.17倍。消融实验证明,领域渐进式SFT优于单阶段训练,Rouge-1提高了1.02倍,BLEU-4提高了1.06倍。此外,蒸馏增强推测解码在不损失质量的情况下,实现了1.39-1.52倍的推理加速。
🎯 应用场景
该研究成果可应用于各种需要领域知识的国资企业场景,例如智能客服、政策咨询、合同生成、风险评估等。通过定制化的大语言模型,可以提高工作效率,降低运营成本,并为决策提供更准确的支持。未来,该技术还可以扩展到其他行业和领域,为各行各业提供更智能化的解决方案。
📄 摘要(原文)
This study addresses key challenges in developing domain-specific large language models (LLMs) for Chinese state-owned assets and enterprises (SOAEs), where current approaches face three limitations: 1) constrained model capacity that limits knowledge integration and cross-task adaptability; 2) excessive reliance on domain-specific supervised fine-tuning (SFT) data, which neglects the broader applicability of general language patterns; and 3) inefficient inference acceleration for large models processing long contexts. In this work, we propose SOAEsV2-7B/72B, a specialized LLM series developed via a three-phase framework: 1) continual pre-training integrates domain knowledge while retaining base capabilities; 2) domain-progressive SFT employs curriculum-based learning strategy, transitioning from weakly relevant conversational data to expert-annotated SOAEs datasets to optimize domain-specific tasks; 3) distillation-enhanced speculative decoding accelerates inference via logit distillation between 72B target and 7B draft models, achieving 1.39-1.52$\times$ speedup without quality loss. Experimental results demonstrate that our domain-specific pre-training phase maintains 99.8% of original general language capabilities while significantly improving domain performance, resulting in a 1.08$\times$ improvement in Rouge-1 score and a 1.17$\times$ enhancement in BLEU-4 score. Ablation studies further show that domain-progressive SFT outperforms single-stage training, achieving 1.02$\times$ improvement in Rouge-1 and 1.06$\times$ in BLEU-4. Our work introduces a comprehensive, full-pipeline approach for optimizing SOAEs LLMs, bridging the gap between general language capabilities and domain-specific expertise.