The Aloe Family Recipe for Open and Specialized Healthcare LLMs
作者: Dario Garcia-Gasulla, Jordi Bayarri-Planas, Ashwin Kumar Gururajan, Enrique Lopez-Cuena, Adrian Tormos, Daniel Hinjos, Pablo Bernabeu-Perez, Anna Arias-Duart, Pablo Agustin Martin-Torres, Marta Gonzalez-Mallo, Sergio Alvarez-Napagao, Eduard Ayguadé-Parra, Ulises Cortés
分类: cs.CL, cs.AI
发布日期: 2025-05-07 (更新: 2025-05-28)
备注: Follow-up work from arXiv:2405.01886
💡 一句话要点
Aloe家族开源医疗LLM:优化数据处理与训练,提升安全性和有效性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医疗LLM 开源模型 直接偏好优化 检索增强生成 安全性对齐 思维链 医疗应用
📋 核心要点
- 现有医疗LLM在安全性和有效性方面存在不足,且缺乏高质量的开源模型。
- Aloe家族模型通过定制数据集、合成思维链示例以及DPO对齐,提升模型性能。
- 实验表明,Aloe模型在医疗基准测试中表现出色,安全性显著提高,且更受医护人员青睐。
📝 摘要(中文)
随着医疗领域大型语言模型(LLMs)的进步,对具有竞争力的开源模型的需求日益增长,以保护公共利益。本研究通过优化数据预处理和训练的关键阶段,为开源医疗LLM领域做出贡献,同时展示了如何通过直接偏好优化(DPO)提高模型安全性,以及通过检索增强生成(RAG)提高模型有效性。所使用的评估方法,包括四种不同类型的测试,为该领域定义了一个新的标准。最终的模型,被证明与最好的私有替代方案具有竞争力,并以宽松的许可证发布。
🔬 方法详解
问题定义:论文旨在解决医疗领域缺乏高质量、安全且开源的大型语言模型的问题。现有方法要么是闭源的,要么在安全性和专业性上存在不足,无法满足医疗场景的严格要求。此外,针对医疗领域的jailbreak攻击日益增多,对模型的安全性提出了更高的挑战。
核心思路:论文的核心思路是构建一个开源的、针对医疗领域优化的LLM,通过优化数据预处理、模型训练和对齐策略,提升模型的性能、安全性和可靠性。同时,采用严格的评估方法,确保模型的有效性和安全性。
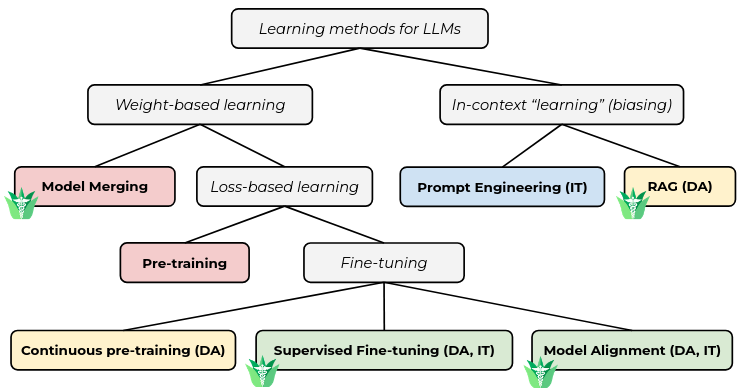
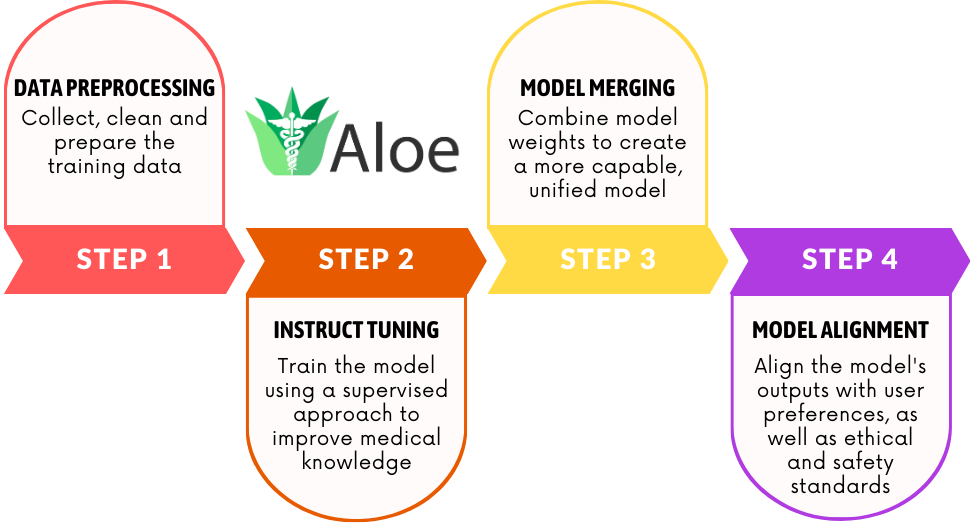
技术框架:Aloe家族模型构建于强大的基础模型之上,如Llama 3.1和Qwen 2.5。主要流程包括:1) 使用定制数据集增强公共数据,并生成合成的思维链示例;2) 使用直接偏好优化(DPO)进行模型对齐,强调模型在面对jailbreak攻击时的伦理和策略一致性;3) 使用包括封闭式、开放式、安全性和人工评估在内的四种不同类型的测试进行评估。
关键创新:论文的关键创新在于:1) 提出了一个完整的、可复现的开源医疗LLM构建流程;2) 通过定制数据集和DPO对齐,显著提升了模型的安全性和有效性;3) 提出了一个包含多种评估方法的综合评估体系,为该领域定义了新的标准。
关键设计:在数据方面,论文使用了定制数据集,并合成了思维链示例,以增强模型的推理能力。在模型对齐方面,采用了直接偏好优化(DPO),以提高模型在面对jailbreak攻击时的鲁棒性。此外,论文还针对医疗领域进行了详细的风险评估,以确保模型的安全发布。
🖼️ 关键图片

📊 实验亮点
Aloe家族模型在医疗基准测试中表现出与最佳私有模型相媲美的性能,并在安全性方面取得了显著提升,能够有效抵御未知的jailbreak攻击。医护人员更倾向于选择Aloe模型,表明其在实际应用中具有更高的可用性和可靠性。详细的风险评估报告也为模型的负责任发布提供了保障。
🎯 应用场景
该研究成果可应用于医疗诊断辅助、医学知识问答、患者咨询、药物研发等领域。开源的Aloe模型能够降低医疗机构和研究人员使用LLM的门槛,促进医疗AI的创新和发展,并最终提升医疗服务的质量和效率。未来,该模型有望集成到各种医疗信息系统中,为医护人员提供更智能化的支持。
📄 摘要(原文)
Purpose: With advancements in Large Language Models (LLMs) for healthcare, the need arises for competitive open-source models to protect the public interest. This work contributes to the field of open medical LLMs by optimizing key stages of data preprocessing and training, while showing how to improve model safety (through DPO) and efficacy (through RAG). The evaluation methodology used, which includes four different types of tests, defines a new standard for the field. The resultant models, shown to be competitive with the best private alternatives, are released with a permisive license. Methods: Building on top of strong base models like Llama 3.1 and Qwen 2.5, Aloe Beta uses a custom dataset to enhance public data with synthetic Chain of Thought examples. The models undergo alignment with Direct Preference Optimization, emphasizing ethical and policy-aligned performance in the presence of jailbreaking attacks. Evaluation includes close-ended, open-ended, safety and human assessments, to maximize the reliability of results. Results: Recommendations are made across the entire pipeline, backed by the solid performance of the Aloe Family. These models deliver competitive performance across healthcare benchmarks and medical fields, and are often preferred by healthcare professionals. On bias and toxicity, the Aloe Beta models significantly improve safety, showing resilience to unseen jailbreaking attacks. For a responsible release, a detailed risk assessment specific to healthcare is attached to the Aloe Family models. Conclusion: The Aloe Beta models, and the recipe that leads to them, are a significant contribution to the open-source medical LLM field, offering top-of-the-line performance while maintaining high ethical requirements. This work sets a new standard for developing and reporting aligned LLMs in healthcare.