Benchmarking LLMs' Swarm intelligence
作者: Kai Ruan, Mowen Huang, Ji-Rong Wen, Hao Sun
分类: cs.MA, cs.CL
发布日期: 2025-05-07 (更新: 2025-10-15)
🔗 代码/项目: GITHUB
💡 一句话要点
SwarmBench:评估LLM在严格群体智能约束下涌现协同能力的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 群体智能 大型语言模型 多智能体系统 去中心化协同 基准测试
📋 核心要点
- 现有基准测试未能充分捕捉到智能体在信息不完备情况下进行去中心化协同的挑战。
- SwarmBench通过模拟严格的局部感知和通信约束,系统评估LLM的群体智能能力。
- 实验结果表明,现有LLM在去中心化场景下的鲁棒远程规划和自适应策略形成方面存在困难。
📝 摘要(中文)
大型语言模型(LLM)在复杂推理方面展现出潜力,但当在严格的群体智能约束(有限的局部感知和通信)下运行时,它们在多智能体系统(MAS)中涌现协同能力的能力在很大程度上仍未被探索。现有的基准通常不能完全捕捉到智能体在不完整的时空信息下运行的去中心化协同的独特挑战。为了弥合这一差距,我们引入了SwarmBench,这是一个新颖的基准,旨在系统地评估LLM作为去中心化智能体的群体智能能力。SwarmBench包含五个基础的MAS协同任务(追逐、同步、觅食、集群、运输),在一个可配置的2D网格环境中,迫使智能体仅依赖于局部感官输入(k×k视野)和局部通信。我们提出了协同有效性的指标,并分析了涌现的群体动态。对领先的LLM(例如,deepseek-v3,o4-mini)的零样本评估显示出显著的与任务相关的性能变化。虽然观察到了一些基本的协同,但我们的结果表明,当前的LLM在这些去中心化场景中固有的不确定性下,在鲁棒的远程规划和自适应策略形成方面存在显著困难。在这样的群体智能约束下评估LLM对于理解它们在未来去中心化智能系统中的效用至关重要。我们将SwarmBench作为一个开放的、可扩展的工具包发布——建立在一个可定制的物理系统之上——提供环境、提示、评估脚本和全面的数据集。这旨在促进对基于LLM的MAS协同的可重复研究,以及在严重的信息去中心化下涌现的集体行为的理论基础。
🔬 方法详解
问题定义:论文旨在解决现有LLM在多智能体系统中,于严格的群体智能约束下(如有限的局部感知和通信)进行去中心化协同时,能力不足的问题。现有基准测试往往无法充分模拟这种信息不完备的场景,导致无法有效评估LLM在此类环境中的表现。现有方法的痛点在于缺乏一个专门用于评估LLM在去中心化协同任务中涌现行为的基准。
核心思路:论文的核心思路是构建一个名为SwarmBench的新基准,该基准专门设计用于评估LLM作为去中心化智能体时的群体智能能力。通过模拟具有局部感知和通信限制的2D网格环境,迫使LLM智能体仅依赖于有限的信息进行协同,从而考察其在复杂任务中的涌现行为。这种设计旨在更真实地反映实际去中心化系统的挑战。
技术框架:SwarmBench包含以下主要组成部分: 1. 环境:一个可配置的2D网格环境,模拟物理世界。 2. 任务:五个基础的MAS协同任务,包括追逐、同步、觅食、集群和运输。 3. 智能体:LLM作为去中心化智能体,通过局部感知和通信与其他智能体交互。 4. 评估指标:用于评估协同有效性和分析涌现群体动态的指标。 5. 提示工程:为LLM设计的提示,引导其完成任务。
关键创新:SwarmBench的关键创新在于其专门针对LLM在去中心化协同任务中的涌现行为进行评估。与现有基准不同,SwarmBench强调智能体的局部感知和通信限制,从而更真实地模拟了实际去中心化系统的挑战。此外,SwarmBench提供了一个开放且可扩展的平台,方便研究人员进行可重复的研究。
关键设计:SwarmBench的关键设计包括: 1. 局部感知:智能体只能观察到其周围k×k的区域。 2. 局部通信:智能体只能与附近的智能体进行通信。 3. 任务多样性:五个不同的协同任务,涵盖了不同的协同需求。 4. 评估指标:包括协同完成度、效率、鲁棒性等指标。
🖼️ 关键图片
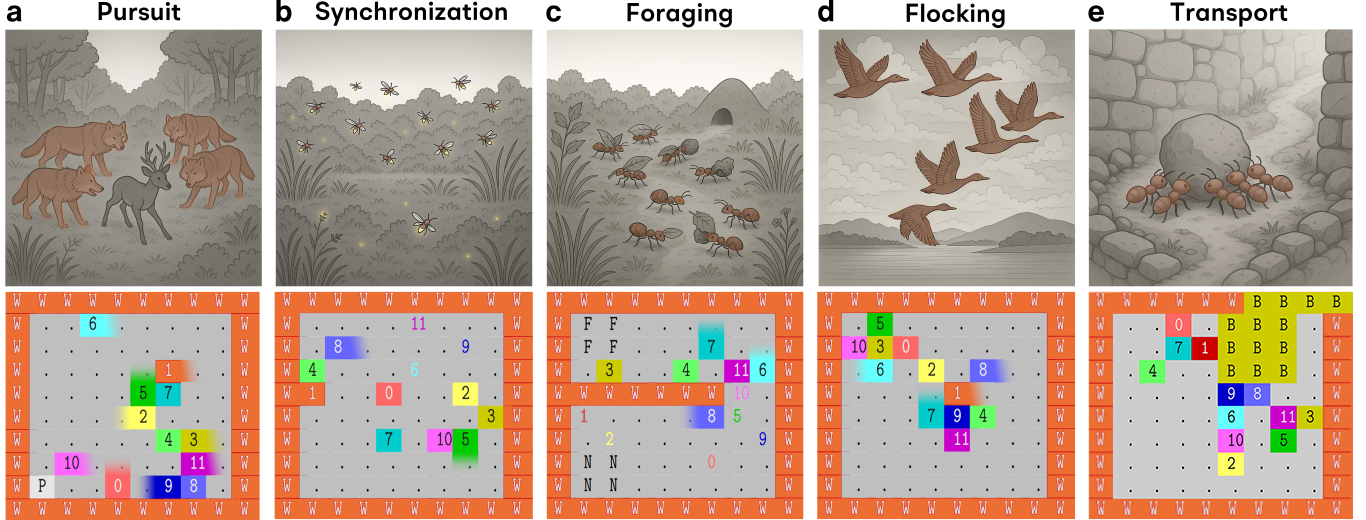
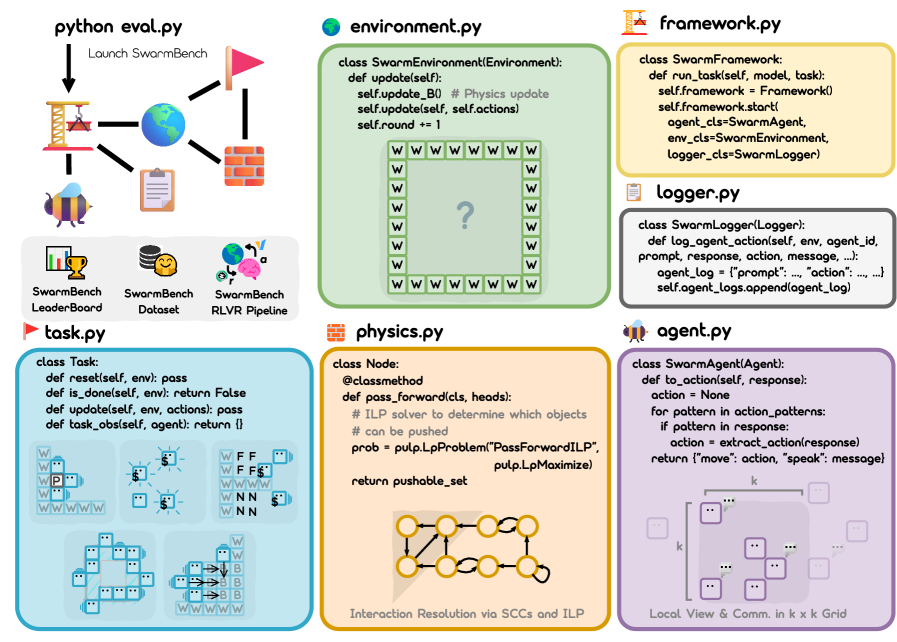

📊 实验亮点
实验结果表明,现有LLM在SwarmBench的各项任务中表现出显著的性能差异。虽然观察到了一些基本的协同行为,但LLM在鲁棒的远程规划和自适应策略形成方面存在显著困难。例如,在某些任务中,LLM智能体能够实现简单的同步,但在面对复杂环境或干扰时,协同效果迅速下降。Deepseek-v3和o4-mini等领先LLM在零样本评估中表现出不同的优势和劣势。
🎯 应用场景
SwarmBench的研究成果可应用于开发更智能、更自主的去中心化系统,例如自动驾驶车队、分布式机器人集群、以及智能交通管理系统。通过提升LLM在群体智能约束下的协同能力,可以实现更高效、更可靠的资源分配和任务执行,从而在智慧城市、智能制造等领域发挥重要作用。
📄 摘要(原文)
Large Language Models (LLMs) show potential for complex reasoning, yet their capacity for emergent coordination in Multi-Agent Systems (MAS) when operating under strict swarm-like constraints-limited local perception and communication-remains largely unexplored. Existing benchmarks often do not fully capture the unique challenges of decentralized coordination when agents operate with incomplete spatio-temporal information. To bridge this gap, we introduce SwarmBench, a novel benchmark designed to systematically evaluate the swarm intelligence capabilities of LLMs acting as decentralized agents. SwarmBench features five foundational MAS coordination tasks (Pursuit, Synchronization, Foraging, Flocking, Transport) within a configurable 2D grid environment, forcing agents to rely solely on local sensory input ($k\times k$ view) and local communication. We propose metrics for coordination effectiveness and analyze emergent group dynamics. Zero-shot evaluations of leading LLMs (e.g., deepseek-v3, o4-mini) reveal significant task-dependent performance variations. While some rudimentary coordination is observed, our results indicate that current LLMs significantly struggle with robust long-range planning and adaptive strategy formation under the uncertainty inherent in these decentralized scenarios. Assessing LLMs under such swarm-like constraints is crucial for understanding their utility in future decentralized intelligent systems. We release SwarmBench as an open, extensible toolkit-built on a customizable physical system-providing environments, prompts, evaluation scripts, and comprehensive datasets. This aims to foster reproducible research into LLM-based MAS coordination and the theoretical underpinnings of emergent collective behavior under severe informational decentralization. Our code repository is available at https://github.com/x66ccff/swarmbench.