Scientific Hypothesis Generation and Validation: Methods, Datasets, and Future Directions
作者: Adithya Kulkarni, Fatimah Alotaibi, Xinyue Zeng, Longfeng Wu, Tong Zeng, Barry Menglong Yao, Minqian Liu, Shuaicheng Zhang, Lifu Huang, Dawei Zhou
分类: cs.CL, cs.LG
发布日期: 2025-05-06
💡 一句话要点
综述:大型语言模型驱动的科学假设生成与验证方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 科学假设生成 科学假设验证 知识图谱 因果推理 人机协作 检索增强生成
📋 核心要点
- 现有科学假设生成方法在新颖性发现和可扩展性方面存在不足,难以有效应对复杂科学问题。
- 论文综述了利用大型语言模型进行科学假设生成与验证的各种方法,包括符号框架、生成模型和混合系统。
- 论文整理了多个科学领域的数据集,并提出了未来研究方向,旨在推动LLM在科学发现中的应用。
📝 摘要(中文)
大型语言模型(LLMs)通过信息综合、潜在关系发现和推理增强,正在变革科学假设的生成与验证。本综述系统地概述了LLM驱动的方法,包括符号框架、生成模型、混合系统和多智能体架构。我们研究了检索增强生成、知识图谱补全、模拟、因果推理和工具辅助推理等技术,强调了可解释性、新颖性和领域对齐方面的权衡。我们将早期的符号发现系统(例如,BACON、KEKADA)与现代LLM流程进行了对比,后者利用上下文学习和通过微调、检索和符号 grounding 进行的领域自适应。对于验证,我们回顾了模拟、人机协作、因果建模和不确定性量化,强调了开放世界背景下的迭代评估。该综述绘制了跨生物医学、材料科学、环境科学和社会科学的数据集,并介绍了 AHTech 和 CSKG-600 等新资源。最后,我们概述了一个路线图,强调新颖性感知生成、多模态-符号集成、人机环路系统和伦理保障,将 LLM 定位为有原则、可扩展的科学发现的智能体。
🔬 方法详解
问题定义:当前科学假设生成方法面临的主要问题是难以有效处理大规模、复杂的科学数据,并且在新颖性发现方面存在局限性。传统的符号方法虽然具有可解释性,但在处理复杂关系时表现不足。现有的方法在可解释性、新颖性和领域对齐方面存在权衡,难以满足实际科研需求。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的信息综合、潜在关系发现和推理能力,来辅助甚至自动化科学假设的生成与验证过程。通过结合不同的LLM架构和技术,例如检索增强生成、知识图谱补全等,旨在提升科学发现的效率和质量。
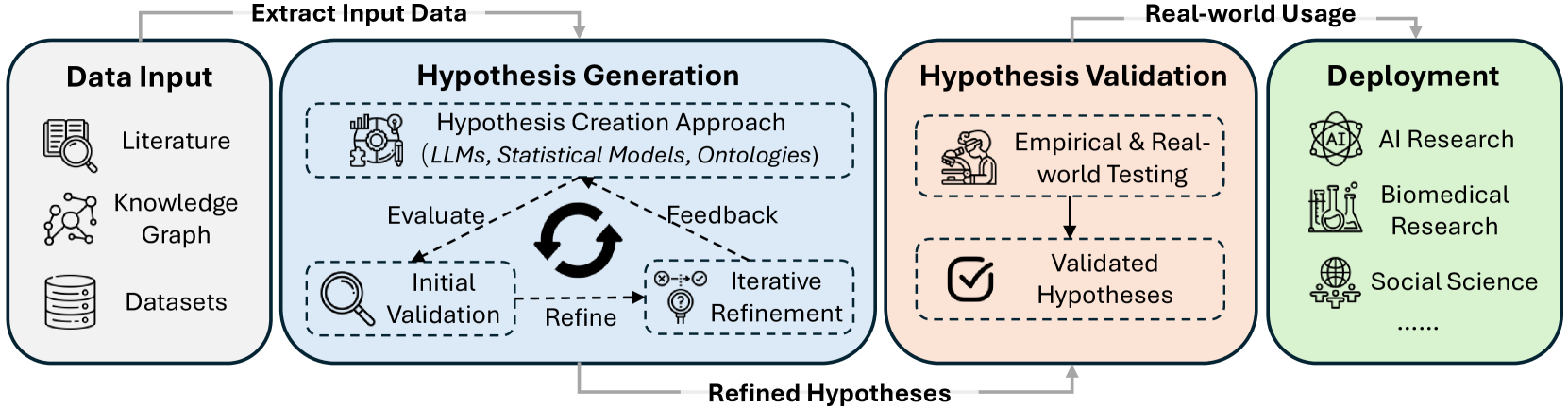
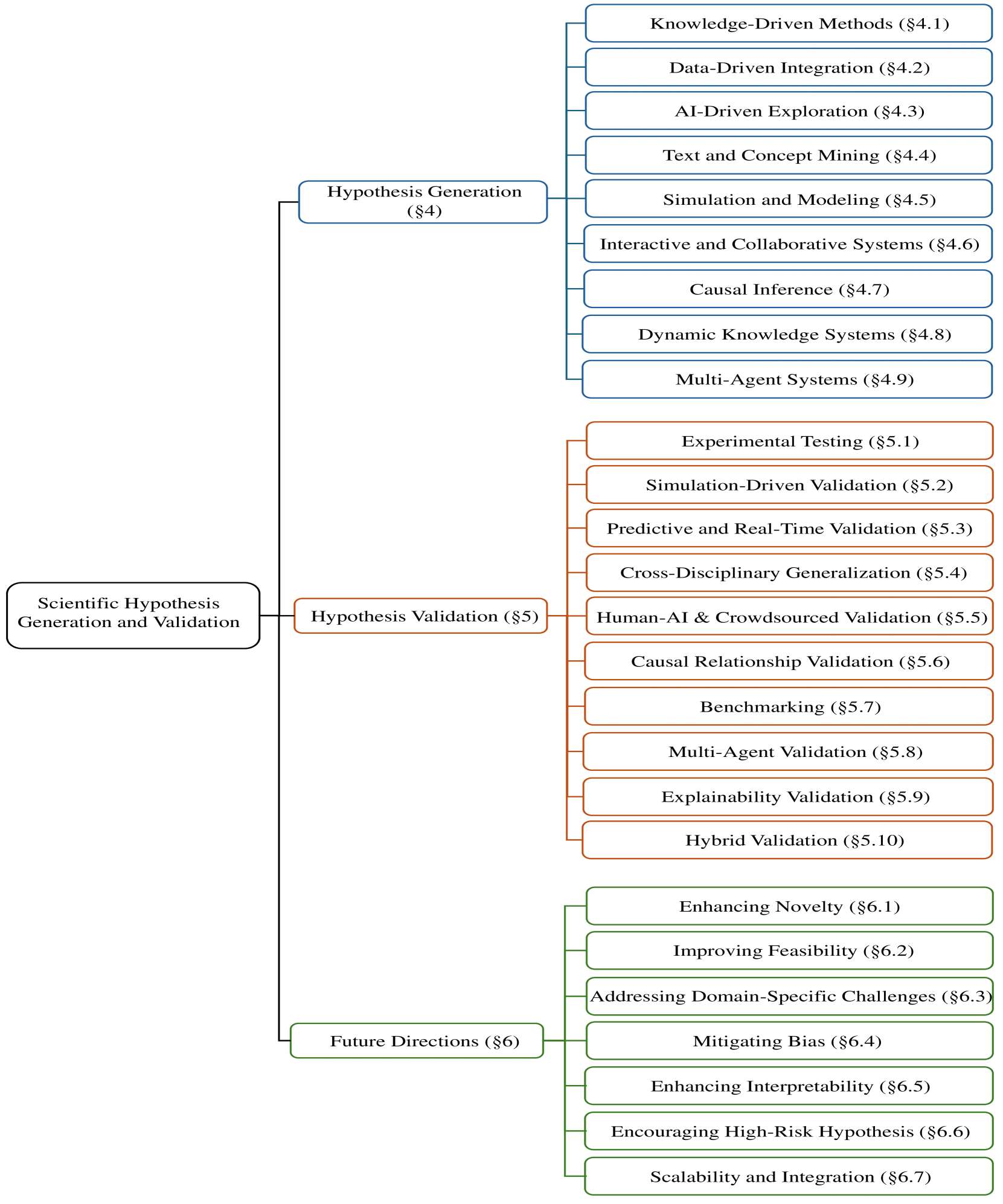
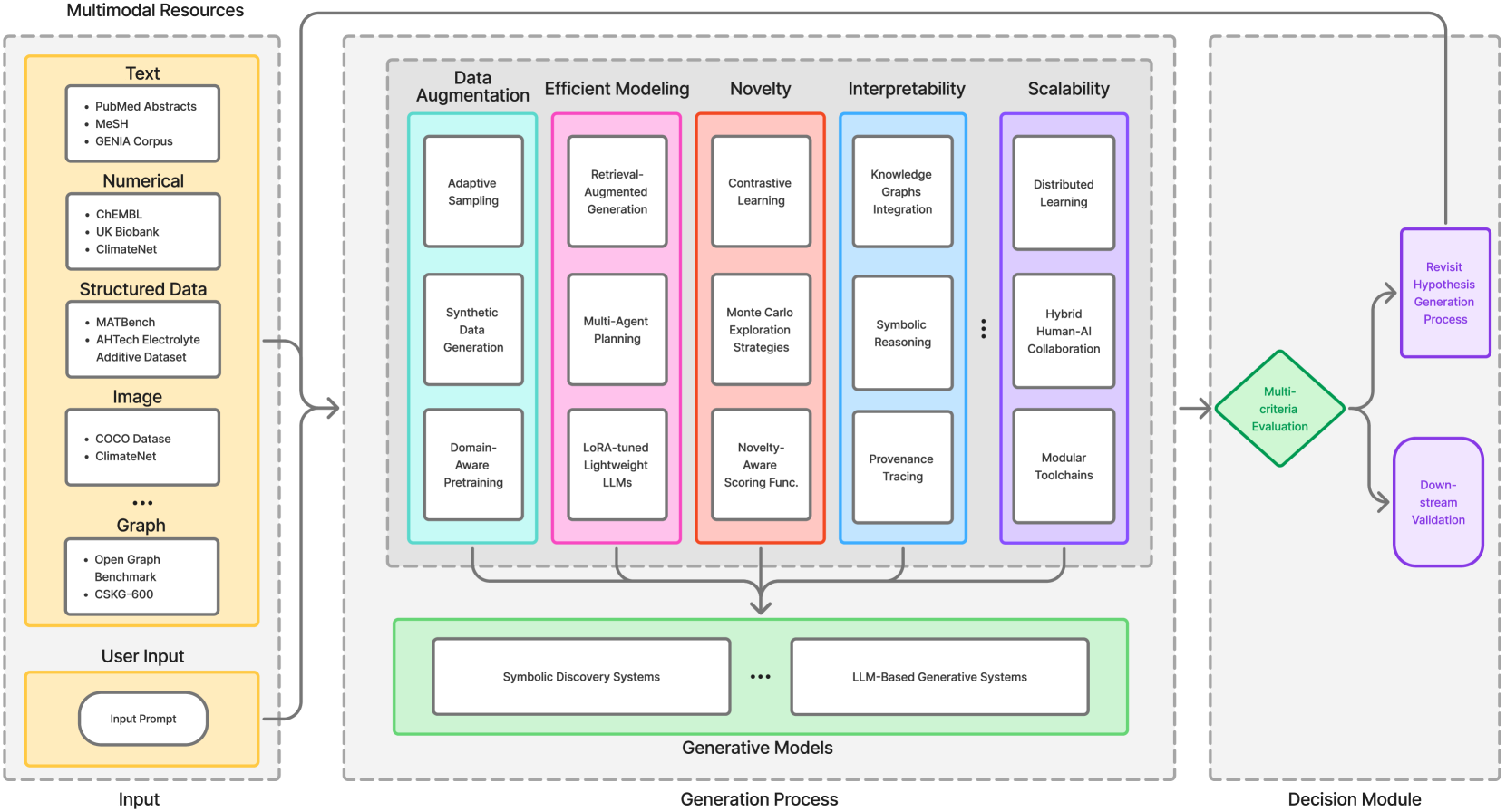
技术框架:论文综述的整体框架包括:1) LLM驱动的科学假设生成方法,涵盖符号框架、生成模型、混合系统和多智能体架构;2) 科学假设验证方法,包括模拟、人机协作、因果建模和不确定性量化;3) 跨多个科学领域的数据集,例如生物医学、材料科学等;4) 未来研究方向,强调新颖性感知生成、多模态-符号集成等。
关键创新:论文的关键创新在于系统性地总结了LLM在科学假设生成与验证中的应用,并提出了未来研究方向。与现有方法相比,LLM能够更好地处理非结构化数据,发现隐藏的科学规律,并生成更具新颖性的假设。此外,论文还强调了人机协作的重要性,旨在构建更智能、更高效的科学发现系统。
关键设计:论文没有提出具体的模型或算法设计,而是在综述的基础上,对各种LLM技术在科学假设生成与验证中的应用进行了分析和比较。论文强调了检索增强生成、知识图谱补全、因果推理等技术在提升LLM性能方面的重要性。此外,论文还提到了微调、检索和符号 grounding 等领域自适应技术,旨在提升LLM在特定科学领域的表现。
🖼️ 关键图片
📊 实验亮点
论文重点介绍了AHTech和CSKG-600等新的数据集资源,这些数据集可以用于训练和评估LLM在科学领域的表现。此外,论文还强调了在开放世界背景下进行迭代评估的重要性,旨在提升LLM在实际科研场景中的应用效果。
🎯 应用场景
该研究成果可应用于多个科学领域,例如生物医学、材料科学、环境科学和社会科学。通过利用LLM辅助科学假设生成与验证,可以加速科学发现过程,降低科研成本,并有望解决一些复杂的科学难题。未来的应用方向包括新药研发、新材料设计、气候变化预测等。
📄 摘要(原文)
Large Language Models (LLMs) are transforming scientific hypothesis generation and validation by enabling information synthesis, latent relationship discovery, and reasoning augmentation. This survey provides a structured overview of LLM-driven approaches, including symbolic frameworks, generative models, hybrid systems, and multi-agent architectures. We examine techniques such as retrieval-augmented generation, knowledge-graph completion, simulation, causal inference, and tool-assisted reasoning, highlighting trade-offs in interpretability, novelty, and domain alignment. We contrast early symbolic discovery systems (e.g., BACON, KEKADA) with modern LLM pipelines that leverage in-context learning and domain adaptation via fine-tuning, retrieval, and symbolic grounding. For validation, we review simulation, human-AI collaboration, causal modeling, and uncertainty quantification, emphasizing iterative assessment in open-world contexts. The survey maps datasets across biomedicine, materials science, environmental science, and social science, introducing new resources like AHTech and CSKG-600. Finally, we outline a roadmap emphasizing novelty-aware generation, multimodal-symbolic integration, human-in-the-loop systems, and ethical safeguards, positioning LLMs as agents for principled, scalable scientific discovery.