Faster MoE LLM Inference for Extremely Large Models
作者: Haoqi Yang, Luohe Shi, Qiwei Li, Zuchao Li, Ping Wang, Bo Du, Mengjia Shen, Hai Zhao
分类: cs.CL, cs.LG
发布日期: 2025-05-06
💡 一句话要点
针对超大MoE LLM,提出更快速的推理方法,提升效率并优化性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 大语言模型 模型推理 性能优化 细粒度模型
📋 核心要点
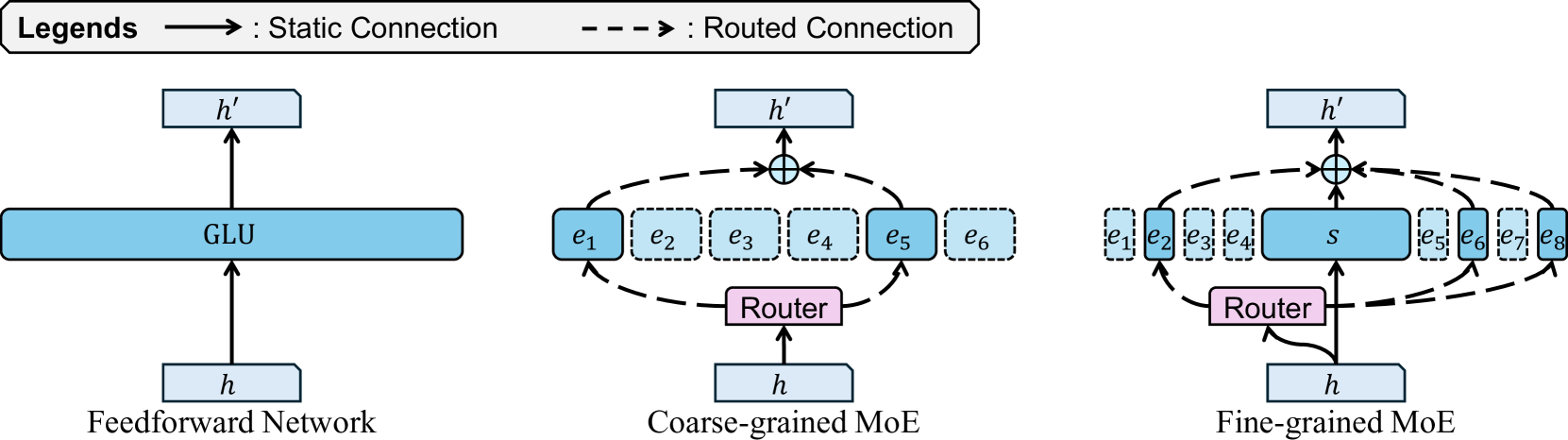
- 现有MoE优化主要集中于粗粒度架构,忽略了细粒度MoE模型,尤其是在不同负载下的效率动态。
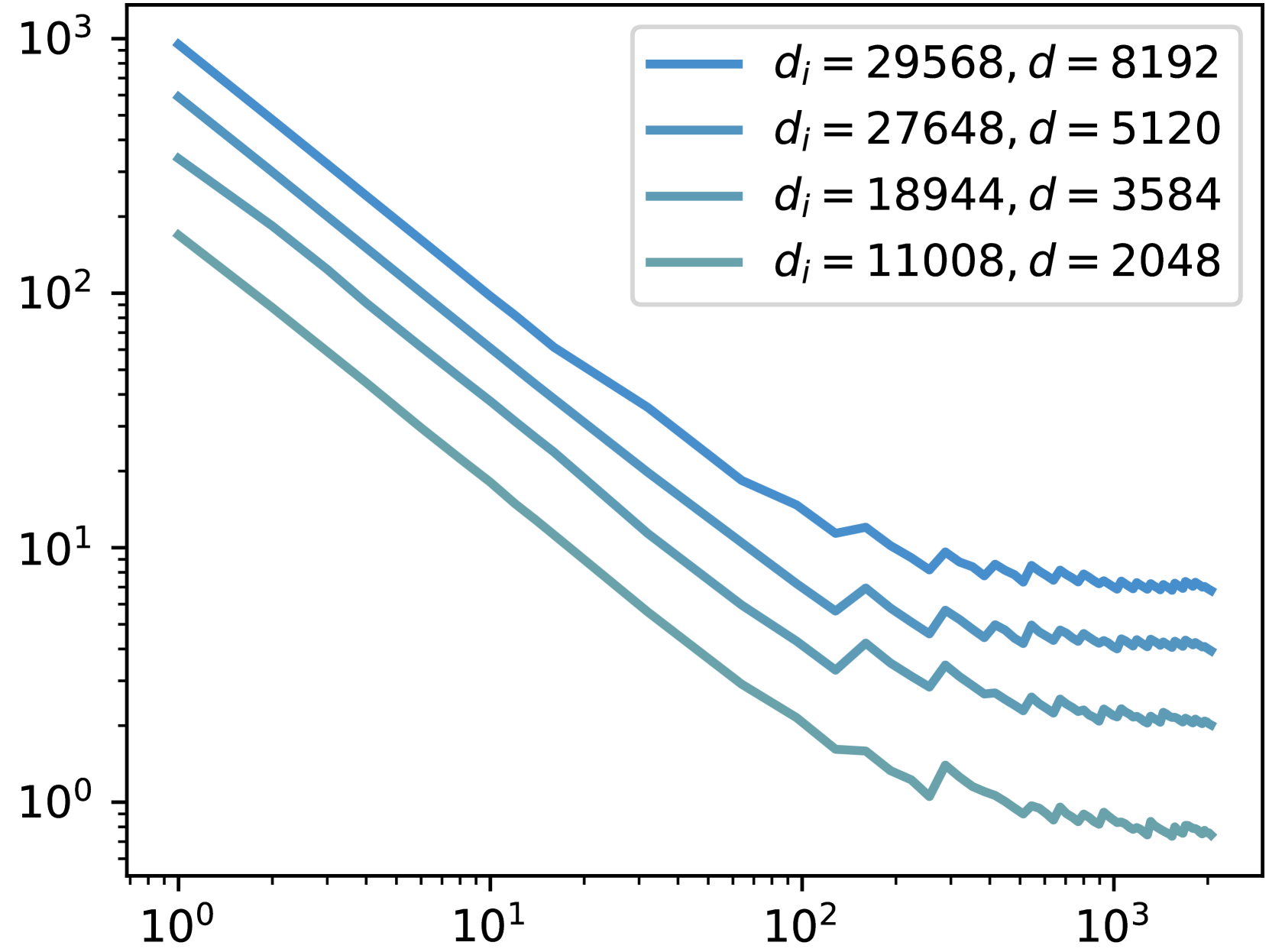
- 通过减少激活专家数量,在性能损失较小的情况下显著提升效率,探索MoE效率与性能的权衡。
- 实验表明,该方法在不降低性能的前提下,至少可以将吞吐量提高10%,具有实际应用价值。
📝 摘要(中文)
稀疏混合专家(MoE)大语言模型(LLM)正逐渐成为超大规模模型的主流方法。目前针对MoE模型的优化主要集中在粗粒度MoE架构上。随着DeepSeek模型的出现,细粒度MoE模型越来越受欢迎,但对其研究仍然有限。因此,本文旨在探讨不同服务负载下的效率动态。此外,细粒度模型允许部署者减少路由专家的数量(包括激活计数和总计数),这就提出了一个问题:这种减少如何影响MoE效率和性能之间的权衡。研究表明,虽然部署MoE模型面临更大的挑战,但也提供了重要的优化机会。在某些情况下,减少激活专家的数量可以显著提高效率,而性能只会略有下降。减少专家总数带来的效率提升有限,但会导致严重的性能下降。本文提出的方法可以在不降低性能的情况下,将吞吐量提高至少10%。总而言之,MoE推理优化仍然是一个具有巨大探索和改进潜力的领域。
🔬 方法详解
问题定义:现有MoE模型的优化主要集中在粗粒度架构上,对于新兴的细粒度MoE模型,尤其是在不同服务负载下的效率动态缺乏深入研究。此外,如何有效地减少细粒度MoE模型中路由专家的数量,在效率和性能之间取得平衡,是一个亟待解决的问题。现有方法在减少专家总数时,性能下降严重。
核心思路:本文的核心思路是探索减少激活专家数量对MoE模型效率和性能的影响。通过动态调整激活专家的数量,可以在保证性能的前提下,显著提高推理效率。同时,研究减少专家总数对性能的影响,避免过度优化导致的性能损失。
技术框架:论文主要研究了在不同服务负载下,减少激活专家数量和减少专家总数对MoE模型推理效率和性能的影响。具体流程包括:1) 分析不同负载下的效率动态;2) 评估减少激活专家数量对效率和性能的权衡;3) 评估减少专家总数对效率和性能的影响;4) 提出优化策略,在不降低性能的前提下提高吞吐量。
关键创新:本文的关键创新在于深入研究了细粒度MoE模型中,减少激活专家数量对效率和性能的精细化影响。与以往研究不同,本文关注的是在保证性能的前提下,如何通过减少激活专家数量来提高推理效率,而不是盲目地减少专家总数。
关键设计:论文的关键设计在于对激活专家数量和专家总数进行区分,并分别评估其对效率和性能的影响。通过实验确定了在不同负载下,减少激活专家数量的最佳策略,以及减少专家总数的限制。具体的参数设置和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法可以在不降低性能的情况下,将MoE模型的吞吐量提高至少10%。通过减少激活专家的数量,可以在某些场景下显著提高效率,而性能只会略有下降。这表明,在细粒度MoE模型中,存在着巨大的优化空间。
🎯 应用场景
该研究成果可应用于大规模语言模型的部署和推理服务,尤其是在资源受限的环境下。通过优化MoE模型的推理效率,可以降低计算成本,提高服务吞吐量,并支持更大规模的模型部署。该研究对于构建更高效、更经济的AI基础设施具有重要意义。
📄 摘要(原文)
Sparse Mixture of Experts (MoE) large language models (LLMs) are gradually becoming the mainstream approach for ultra-large-scale models. Existing optimization efforts for MoE models have focused primarily on coarse-grained MoE architectures. With the emergence of DeepSeek Models, fine-grained MoE models are gaining popularity, yet research on them remains limited. Therefore, we want to discuss the efficiency dynamic under different service loads. Additionally, fine-grained models allow deployers to reduce the number of routed experts, both activated counts and total counts, raising the question of how this reduction affects the trade-off between MoE efficiency and performance. Our findings indicate that while deploying MoE models presents greater challenges, it also offers significant optimization opportunities. Reducing the number of activated experts can lead to substantial efficiency improvements in certain scenarios, with only minor performance degradation. Reducing the total number of experts provides limited efficiency gains but results in severe performance degradation. Our method can increase throughput by at least 10\% without any performance degradation. Overall, we conclude that MoE inference optimization remains an area with substantial potential for exploration and improvement.