UCSC at SemEval-2025 Task 3: Context, Models and Prompt Optimization for Automated Hallucination Detection in LLM Output
作者: Sicong Huang, Jincheng He, Shiyuan Huang, Karthik Raja Anandan, Arkajyoti Chakraborty, Ian Lane
分类: cs.CL
发布日期: 2025-05-05
备注: 6 pages, 1 figure
💡 一句话要点
UCSC提出基于上下文检索、模型和提示优化的框架,在LLM幻觉检测任务中取得最佳性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 上下文检索 错误内容识别 跨度映射 提示优化 自然语言处理
📋 核心要点
- 大型语言模型存在幻觉问题,尤其是在知识密集型任务中,现有方法难以精确定位幻觉在输出中的位置。
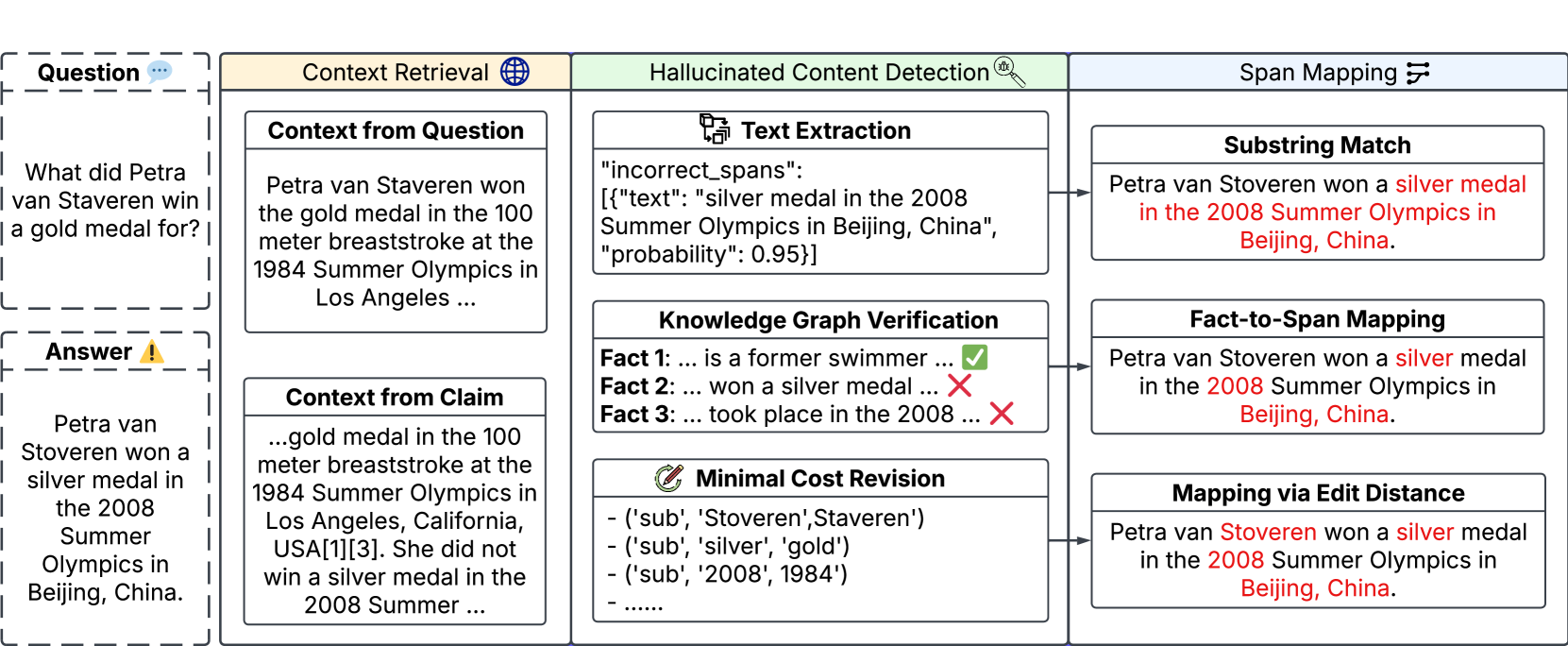
- 该论文提出一个框架,通过检索相关上下文、识别错误内容并将其映射回LLM输出,实现幻觉的精确定位。
- 该系统在SemEval 2025 Task 3 Mu-SHROOM任务中取得了最佳性能,在所有语言的平均排名中位列第一。
📝 摘要(中文)
大型语言模型(LLM)在回答知识密集型问题时,幻觉是一个重大挑战。随着LLM的广泛应用,检测幻觉是否发生以及精确定位幻觉在LLM输出中的位置至关重要。SemEval 2025 Task 3,Mu-SHROOM:关于幻觉和相关可观察过度生成错误的多语言共享任务,是朝着这个方向的最新尝试。本文介绍了UCSC系统在Mu-SHROOM共享任务中的提交。我们引入了一个框架,该框架首先检索相关上下文,然后从答案中识别错误内容,最后将它们映射回LLM输出中的跨度。该过程通过自动优化提示得到进一步增强。我们的系统实现了最高的整体性能,在所有语言的平均排名中排名第一。我们发布了我们的代码和实验结果。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在知识密集型问答中产生的幻觉问题,并精确定位幻觉在LLM输出文本中的具体位置。现有方法通常难以准确识别和定位这些幻觉,导致LLM在实际应用中可靠性降低。
核心思路:论文的核心思路是结合上下文检索、错误内容识别和跨度映射,构建一个多阶段的幻觉检测框架。通过检索与问题相关的上下文信息,可以帮助模型更好地判断LLM生成内容是否真实可靠。错误内容识别模块则负责从LLM的答案中找出不准确或虚假的信息。最后,跨度映射模块将这些错误内容映射回原始的LLM输出,从而精确定位幻觉的位置。
技术框架:该框架主要包含三个阶段:1) 上下文检索:使用信息检索技术,从外部知识库或文档中检索与问题相关的上下文信息。2) 错误内容识别:利用自然语言处理技术,例如文本蕴含或知识图谱验证,判断LLM生成的答案中是否存在错误或虚假信息。3) 跨度映射:将识别出的错误内容映射回LLM输出的文本跨度,从而精确定位幻觉的位置。此外,该框架还包括一个自动提示优化模块,用于提升整体性能。
关键创新:该论文的关键创新在于将上下文检索、错误内容识别和跨度映射三个模块有机结合,形成一个完整的幻觉检测流程。此外,自动提示优化模块也是一个重要的创新点,它可以根据任务特点自动调整提示语,从而提升模型的性能。
关键设计:上下文检索模块可能采用基于向量相似度的检索方法,例如使用预训练语言模型(如BERT或Sentence-BERT)对问题和文档进行编码,然后计算它们的相似度。错误内容识别模块可能使用文本蕴含模型,判断LLM的答案是否与检索到的上下文信息一致。自动提示优化模块可能采用强化学习或进化算法,搜索最优的提示语组合。
🖼️ 关键图片
📊 实验亮点
该系统在SemEval 2025 Task 3 Mu-SHROOM任务中取得了最佳的整体性能,在所有语言的平均排名中位列第一。这表明该框架在多语言幻觉检测方面具有很强的竞争力。具体的性能指标和与其他基线系统的对比数据需要在论文中进一步查找。
🎯 应用场景
该研究成果可应用于各种需要大型语言模型提供知识服务的场景,例如智能客服、问答系统、内容生成等。通过检测和定位LLM输出中的幻觉,可以提高LLM的可靠性和可信度,从而更好地服务于用户。未来,该技术还可以应用于LLM的训练和评估,帮助开发更安全、更可靠的LLM。
📄 摘要(原文)
Hallucinations pose a significant challenge for large language models when answering knowledge-intensive queries. As LLMs become more widely adopted, it is crucial not only to detect if hallucinations occur but also to pinpoint exactly where in the LLM output they occur. SemEval 2025 Task 3, Mu-SHROOM: Multilingual Shared-task on Hallucinations and Related Observable Overgeneration Mistakes, is a recent effort in this direction. This paper describes the UCSC system submission to the shared Mu-SHROOM task. We introduce a framework that first retrieves relevant context, next identifies false content from the answer, and finally maps them back to spans in the LLM output. The process is further enhanced by automatically optimizing prompts. Our system achieves the highest overall performance, ranking #1 in average position across all languages. We release our code and experiment results.