RADLADS: Rapid Attention Distillation to Linear Attention Decoders at Scale
作者: Daniel Goldstein, Eric Alcaide, Janna Lu, Eugene Cheah
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-05 (更新: 2026-01-22)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
RADLADS:通过快速注意力蒸馏实现线性注意力解码器的大规模应用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 注意力蒸馏 模型压缩 Transformer 自然语言处理
📋 核心要点
- 传统Softmax注意力Transformer计算复杂度高,难以大规模部署,线性注意力模型是潜在的替代方案。
- RADLADS通过快速注意力蒸馏,将预训练的Softmax注意力模型高效地转换为线性注意力解码器模型。
- 实验表明,转换后的模型在下游任务中表现出色,同时显著降低了计算成本,并开源了相关模型和代码。
📝 摘要(中文)
本文提出了一种名为RADLADS(Rapid Attention Distillation to Linear Attention Decoders at Scale)的协议,用于将softmax注意力Transformer模型快速转换为线性注意力解码器模型。同时,还提出了两种新的RWKV变体架构,并将流行的Qwen2.5开源模型(7B、32B和72B规模)进行了转换。我们的转换过程仅需3.5亿至7亿个token,不到原始教师模型训练所用token数量的0.005%。将模型转换为72B线性注意力模型的成本低于2000美元(按当前价格计算),但推理质量仍接近原始Transformer模型。这些模型在一系列针对其规模的线性注意力模型的标准基准测试中,实现了最先进的下游性能。我们已在HuggingFace上发布了所有模型,采用Apache 2.0许可证,但72B模型也受Qwen许可协议的约束。
🔬 方法详解
问题定义:现有的大规模Transformer模型依赖于Softmax注意力机制,其计算复杂度随序列长度呈平方增长,限制了其在长序列和资源受限环境中的应用。线性注意力模型具有更低的计算复杂度,但通常性能不如Softmax注意力模型。因此,如何高效地将高性能的Softmax注意力模型转换为线性注意力模型,同时保持其性能,是一个重要的研究问题。
核心思路:RADLADS的核心思路是利用注意力蒸馏技术,将预训练的Softmax注意力Transformer模型的知识迁移到线性注意力解码器模型。通过最小化两个模型之间的注意力分布差异,使得线性注意力模型能够学习到Softmax注意力模型的行为,从而在保持性能的同时,降低计算复杂度。
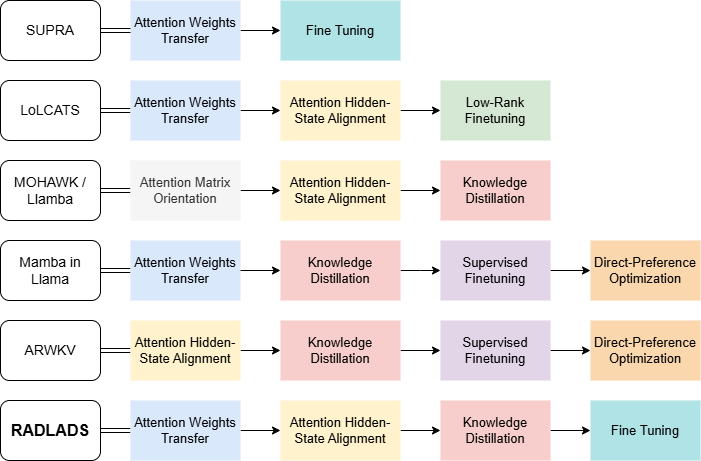
技术框架:RADLADS的整体框架包括以下几个主要步骤:1) 选择一个预训练的Softmax注意力Transformer模型作为教师模型。2) 构建一个线性注意力解码器模型作为学生模型,该模型具有与教师模型相似的架构。3) 使用一个相对较小的数据集(350-700M tokens)对学生模型进行蒸馏训练,目标是最小化学生模型和教师模型之间的注意力分布差异。4) 对蒸馏后的学生模型进行微调,以进一步提高其在下游任务中的性能。
关键创新:RADLADS的关键创新在于其高效的蒸馏协议。通过精心设计的损失函数和训练策略,RADLADS能够在极短的时间内(使用极少的数据)将Softmax注意力模型的知识迁移到线性注意力模型。此外,论文还提出了两种新的RWKV变体架构,进一步提升了线性注意力模型的性能。
关键设计:RADLADS的关键设计包括:1) 使用KL散度作为注意力分布差异的度量标准。2) 采用了一种自适应的学习率调整策略,以加速蒸馏过程。3) 对学生模型的初始化进行了优化,使其更接近教师模型。4) 提出了两种新的RWKV变体架构,并针对线性注意力模型进行了优化。
🖼️ 关键图片
📊 实验亮点
RADLADS仅使用350-700M tokens的数据进行蒸馏,成本低于2000美元,即可将Qwen2.5 72B模型转换为线性注意力模型,且推理质量接近原始Transformer模型。转换后的模型在标准基准测试中取得了最先进的下游性能,证明了RADLADS的有效性和高效性。
🎯 应用场景
RADLADS技术可广泛应用于自然语言处理领域,尤其是在需要处理长序列和资源受限的场景中,例如机器翻译、文本摘要、对话生成等。该技术能够降低模型推理成本,提高部署效率,并促进线性注意力模型在实际应用中的普及。
📄 摘要(原文)
We present Rapid Attention Distillation to Linear Attention Decoders at Scale (RADLADS), a protocol for rapidly converting softmax attention transformers into linear attention decoder models, along with two new RWKV-variant architectures, and models converted from popular Qwen2.5 open source models in 7B, 32B, and 72B sizes. Our conversion process requires only 350-700M tokens, less than 0.005% of the token count used to train the original teacher models. Converting to our 72B linear attention model costs less than \$2,000 USD at today's prices, yet quality at inference remains close to the original transformer. These models achieve state-of-the-art downstream performance across a set of standard benchmarks for linear attention models of their size. We release all our models on HuggingFace under the Apache 2.0 license, with the exception of our 72B models which are also governed by the Qwen License Agreement. Models at https://huggingface.co/collections/recursal/radlads-6818ee69e99e729ba8a87102 Training Code at https://github.com/recursal/RADLADS-paper