Sailing by the Stars: A Survey on Reward Models and Learning Strategies for Learning from Rewards
作者: Xiaobao Wu
分类: cs.CL
发布日期: 2025-05-05 (更新: 2025-06-12)
备注: 36 Pages
🔗 代码/项目: GITHUB
💡 一句话要点
综述:基于奖励模型的LLM奖励学习策略研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 奖励模型 强化学习 人机对齐 学习策略
📋 核心要点
- 现有LLM训练方法主要依赖静态数据,缺乏从动态反馈中学习的能力,限制了模型对齐人类偏好和进行深度推理。
- 本文综述了“从奖励中学习”这一范式,该范式利用奖励信号引导LLM行为,实现从被动学习到主动学习的转变。
- 该综述涵盖了奖励模型和学习策略,讨论了奖励模型的基准和主要应用,并指出了该领域面临的挑战和未来方向。
📝 摘要(中文)
大型语言模型(LLM)的最新发展已经从预训练扩展到后训练和测试时扩展。在这些发展中,一个关键的统一范式已经出现:从奖励中学习,其中奖励信号充当引导LLM行为的指路明灯。它支撑了广泛流行的技术,例如强化学习(RLHF、RLAIF、DPO和GRPO)、奖励引导解码和事后校正。至关重要的是,这种范式实现了从被动地从静态数据中学习到主动地从动态反馈中学习的转变。这赋予了LLM对齐的偏好和对各种任务的深度推理能力。在本调查中,我们从奖励模型的角度和跨训练、推理和后推理阶段的学习策略的角度,全面概述了从奖励中学习。我们进一步讨论了奖励模型的基准和主要应用。最后,我们强调了挑战和未来的方向。我们在https://github.com/bobxwu/learning-from-rewards-llm-papers维护了一个论文集。
🔬 方法详解
问题定义:现有的大型语言模型训练方法,如预训练,主要依赖于大规模的静态数据集。这种方法的局限性在于模型难以根据动态的用户反馈进行调整,从而导致模型行为与人类偏好不一致,并且缺乏深度推理能力。因此,如何使LLM能够从动态奖励信号中学习,并根据这些信号调整自身行为,是一个重要的研究问题。
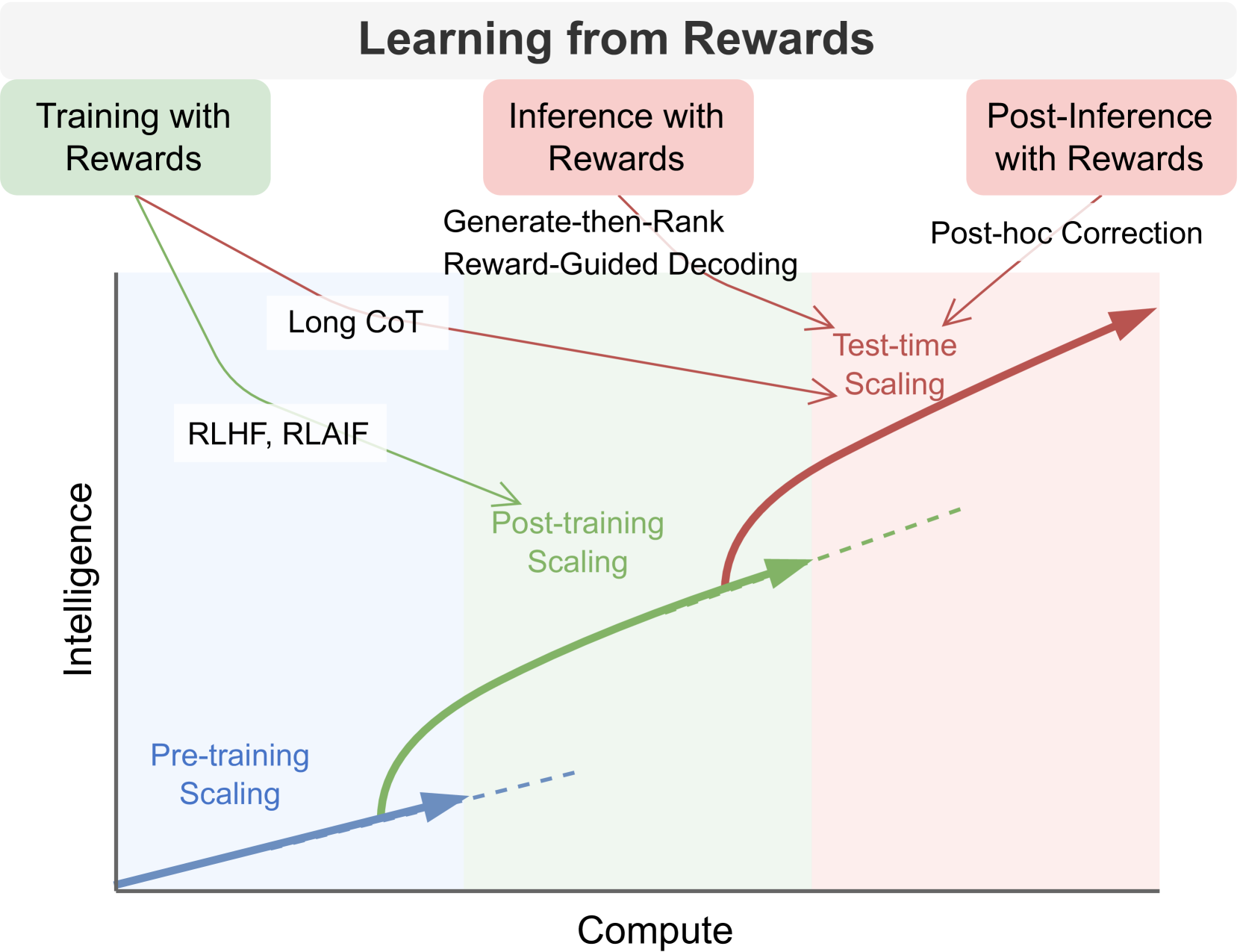
核心思路:本文的核心思路是综述“从奖励中学习”(Learning from Rewards)这一范式。该范式将奖励信号作为引导LLM行为的关键,通过奖励模型和学习策略,使LLM能够从动态反馈中学习,从而更好地对齐人类偏好,并提升深度推理能力。这种方法的核心在于将静态学习转变为主动学习,使模型能够根据环境反馈进行自我改进。
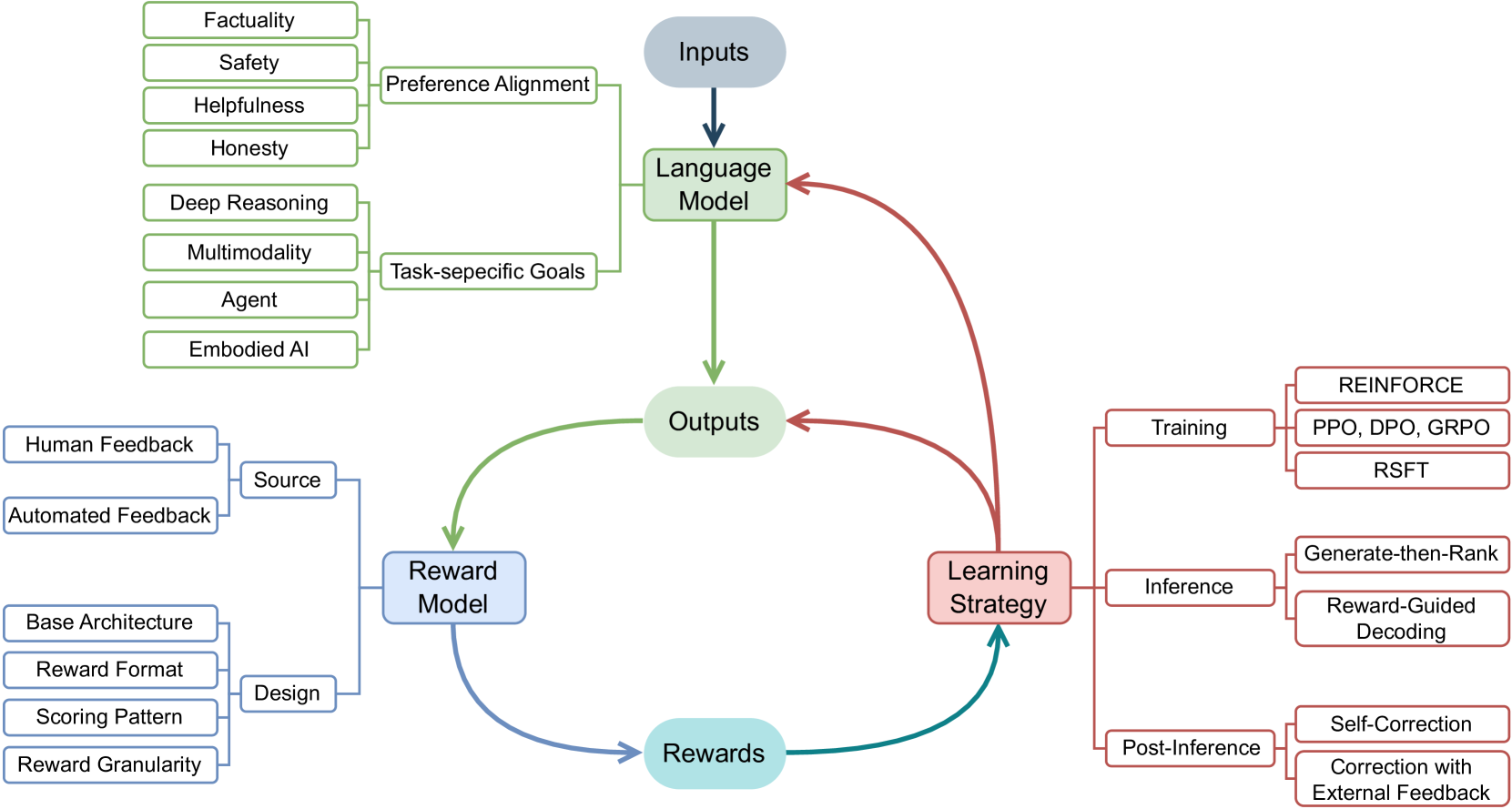
技术框架:本文的综述框架主要包含以下几个部分:首先,介绍了奖励模型的概念和作用,以及常用的奖励模型架构。其次,详细阐述了基于奖励的学习策略,包括训练阶段(如RLHF、DPO等)、推理阶段(如奖励引导解码)和后推理阶段(如事后校正)。然后,讨论了奖励模型的评估基准和主要应用。最后,总结了该领域面临的挑战和未来的研究方向。
关键创新:本文的创新之处在于对“从奖励中学习”这一新兴范式进行了全面的综述,并从奖励模型和学习策略两个角度对该领域的研究进行了系统性的梳理。与以往的综述不同,本文不仅关注了传统的强化学习方法,还涵盖了奖励引导解码和事后校正等新兴技术,从而为研究人员提供了一个更全面的视角。
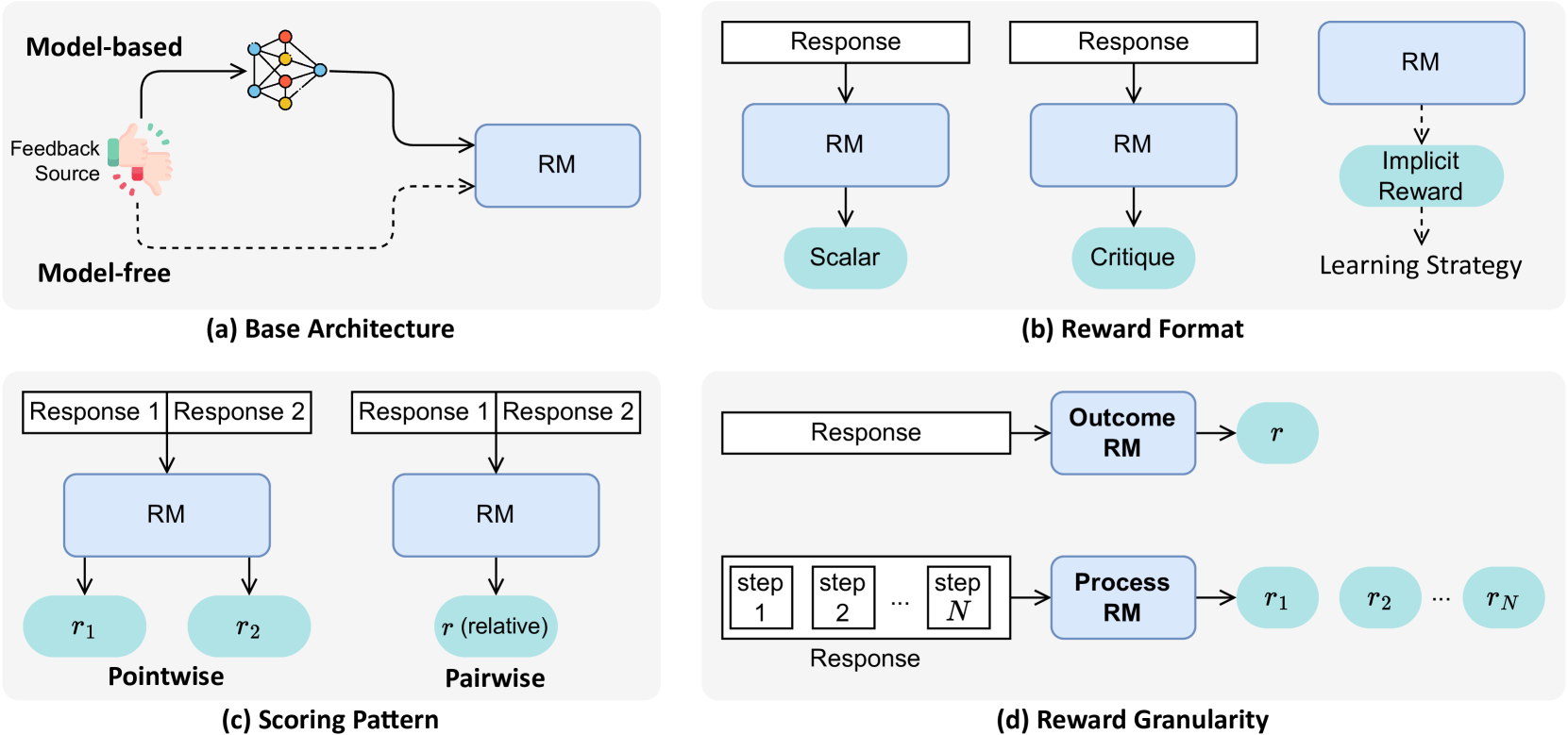
关键设计:本文作为一篇综述,并没有提出新的技术设计。但是,文章详细介绍了各种奖励模型和学习策略的关键设计,例如,RLHF中的奖励函数设计,DPO中的策略优化方法,以及奖励引导解码中的解码策略等。这些设计细节对于理解和应用“从奖励中学习”这一范式至关重要。
🖼️ 关键图片
📊 实验亮点
本文是一篇综述性文章,因此没有具体的实验结果。然而,文章总结了现有研究中使用的各种奖励模型和学习策略,并讨论了它们的优缺点。通过对这些研究的分析,本文为研究人员提供了一个全面的视角,从而可以更好地选择和应用这些方法。此外,文章还指出了该领域面临的挑战和未来的研究方向,为未来的研究提供了指导。
🎯 应用场景
该研究对大型语言模型的训练和应用具有广泛的潜在应用。通过利用奖励模型和学习策略,可以使LLM更好地对齐人类偏好,从而在对话系统、文本生成、智能助手等领域提供更优质的服务。此外,该研究还可以应用于机器人控制、游戏AI等领域,使智能体能够从奖励信号中学习,并实现更复杂的行为。
📄 摘要(原文)
Recent developments in Large Language Models (LLMs) have shifted from pre-training scaling to post-training and test-time scaling. Across these developments, a key unified paradigm has arisen: Learning from Rewards, where reward signals act as the guiding stars to steer LLM behavior. It has underpinned a wide range of prevalent techniques, such as reinforcement learning (RLHF, RLAIF, DPO, and GRPO), reward-guided decoding, and post-hoc correction. Crucially, this paradigm enables the transition from passive learning from static data to active learning from dynamic feedback. This endows LLMs with aligned preferences and deep reasoning capabilities for diverse tasks. In this survey, we present a comprehensive overview of learning from rewards, from the perspective of reward models and learning strategies across training, inference, and post-inference stages. We further discuss the benchmarks for reward models and the primary applications. Finally we highlight the challenges and future directions. We maintain a paper collection at https://github.com/bobxwu/learning-from-rewards-llm-papers.