LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis
作者: Qingkai Fang, Yan Zhou, Shoutao Guo, Shaolei Zhang, Yang Feng
分类: cs.CL, cs.AI, cs.SD, eess.AS
发布日期: 2025-05-05
备注: Preprint. Project: https://github.com/ictnlp/LLaMA-Omni2
💡 一句话要点
LLaMA-Omni2:基于LLM的实时流式语音聊天机器人
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音聊天机器人 语音语言模型 实时语音交互 自回归语音合成 大语言模型微调
📋 核心要点
- 现有语音聊天机器人通常需要大量语音数据训练,且实时性和交互质量有待提升。
- LLaMA-Omni 2通过集成语音编码器和自回归流式语音解码器,构建高效的语音语言模型。
- 实验表明,LLaMA-Omni 2在少量数据下超越了在海量数据上训练的现有模型,性能显著提升。
📝 摘要(中文)
本文介绍了LLaMA-Omni 2,一系列参数规模从0.5B到14B的语音语言模型(SpeechLM),能够实现高质量的实时语音交互。LLaMA-Omni 2构建于Qwen2.5系列模型之上,集成了语音编码器和自回归流式语音解码器。尽管仅在20万多轮语音对话样本上进行训练,LLaMA-Omni 2在多个口语问答和语音指令跟随基准测试中表现出强大的性能,超越了之前最先进的SpeechLM,如GLM-4-Voice,后者在数百万小时的语音数据上进行训练。
🔬 方法详解
问题定义:现有语音聊天机器人通常需要大量的训练数据,特别是语音数据,这使得训练成本高昂。此外,如何在保证语音交互质量的同时,实现实时性也是一个挑战。现有方法在数据效率和实时性方面存在不足。
核心思路:LLaMA-Omni 2的核心思路是利用预训练的大语言模型(LLM)的强大能力,通过少量的语音数据进行微调,从而快速构建高性能的语音聊天机器人。通过集成语音编码器和自回归流式语音解码器,实现实时语音交互。
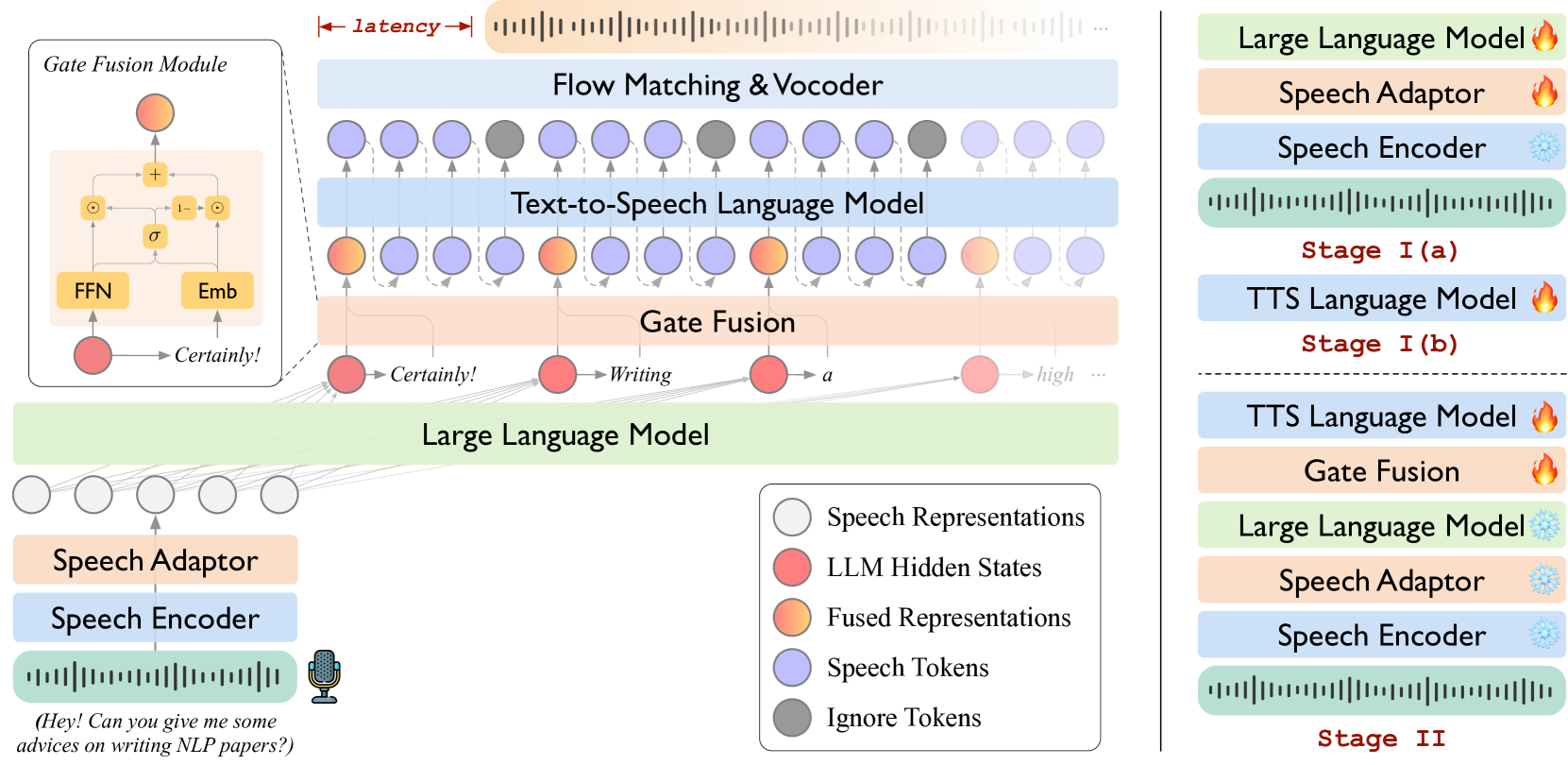
技术框架:LLaMA-Omni 2的整体架构包括三个主要模块:1) 语音编码器:将输入的语音信号转换为特征表示;2) LLM:使用Qwen2.5系列模型作为LLM的核心,负责理解语音特征并生成文本回复;3) 自回归流式语音解码器:将LLM生成的文本回复转换为语音信号,并以流式的方式输出,实现实时性。整个流程是:语音输入 -> 语音编码 -> LLM文本生成 -> 语音解码 -> 语音输出。
关键创新:最重要的技术创新点在于利用预训练的LLM作为语音聊天机器人的核心,并结合流式语音解码器,实现了在少量语音数据下构建高性能实时语音聊天机器人。与现有方法相比,LLaMA-Omni 2在数据效率和实时性方面具有显著优势。
关键设计:LLaMA-Omni 2的关键设计包括:1) 选择Qwen2.5系列模型作为LLM的基础,利用其强大的语言理解和生成能力;2) 设计自回归流式语音解码器,保证语音输出的实时性;3) 采用少量多轮语音对话数据进行微调,提高模型在语音交互任务上的性能。具体的参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
LLaMA-Omni 2在仅使用20万多轮语音对话样本进行训练的情况下,在多个口语问答和语音指令跟随基准测试中,超越了之前最先进的SpeechLM,如GLM-4-Voice,后者在数百万小时的语音数据上进行训练。这表明LLaMA-Omni 2具有极高的数据效率和强大的泛化能力。
🎯 应用场景
LLaMA-Omni 2可广泛应用于智能客服、语音助手、游戏交互、教育辅导等领域。其低数据需求和实时性特点,使其能够在资源有限的环境下快速部署,并提供自然流畅的语音交互体验。未来,该技术有望推动人机交互方式的变革,使人机沟通更加便捷高效。
📄 摘要(原文)
Real-time, intelligent, and natural speech interaction is an essential part of the next-generation human-computer interaction. Recent advancements have showcased the potential of building intelligent spoken chatbots based on large language models (LLMs). In this paper, we introduce LLaMA-Omni 2, a series of speech language models (SpeechLMs) ranging from 0.5B to 14B parameters, capable of achieving high-quality real-time speech interaction. LLaMA-Omni 2 is built upon the Qwen2.5 series models, integrating a speech encoder and an autoregressive streaming speech decoder. Despite being trained on only 200K multi-turn speech dialogue samples, LLaMA-Omni 2 demonstrates strong performance on several spoken question answering and speech instruction following benchmarks, surpassing previous state-of-the-art SpeechLMs like GLM-4-Voice, which was trained on millions of hours of speech data.