Decoding Open-Ended Information Seeking Goals from Eye Movements in Reading
作者: Cfir Avraham Hadar, Omer Shubi, Yoav Meiri, Amit Heshes, Yevgeni Berzak
分类: cs.CL, cs.AI
发布日期: 2025-05-04 (更新: 2025-09-25)
💡 一句话要点
首次提出仅从阅读时的眼动追踪数据解码开放式信息搜寻目标
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 眼动追踪 阅读理解 信息搜寻 目标解码 多模态学习
📋 核心要点
- 现有方法缺乏利用眼动数据解码开放式阅读目标的能力,限制了对阅读行为的深入理解。
- 本文提出利用大规模眼动追踪数据,结合多模态LLM,实现对开放式阅读目标的自动解码。
- 实验结果表明,该方法在目标选择和文本重建任务上均表现出显著的性能,为相关研究奠定基础。
📝 摘要(中文)
本文首次探讨了是否能够仅从阅读时的眼动追踪数据中自动解码开放式的阅读目标。为了解决这个问题,作者引入了目标解码任务和评估框架,使用了大规模的英语阅读眼动追踪数据,其中包含数百个特定于文本的信息搜寻任务。作者开发并比较了几种判别式和生成式的多模态文本和眼动追踪LLM模型来完成这些任务。实验表明,在从多个选项中选择正确目标方面取得了显著成功,并且在自由形式的文本重建精确目标方面也取得了进展。这些结果为进一步科学研究目标驱动的阅读打开了大门,并为开发教育和辅助技术提供了可能,这些技术将依赖于从读者眼动追踪中实时解码阅读目标。
🔬 方法详解
问题定义:论文旨在解决的问题是:能否仅通过阅读时的眼动数据,自动解码读者开放式的、文本特定的信息搜寻目标?现有方法缺乏有效利用眼动数据理解读者阅读意图的能力,难以实现个性化的阅读辅助和教育应用。
核心思路:论文的核心思路是利用大规模的眼动追踪数据,训练多模态的LLM模型,学习眼动模式与阅读目标之间的映射关系。通过将文本信息和眼动数据融合,模型能够理解读者在阅读特定文本时的关注点和兴趣,从而推断出其潜在的阅读目标。
技术框架:整体框架包含数据收集、模型构建和评估三个主要阶段。首先,收集大规模的英语阅读眼动追踪数据,并标注文本特定的信息搜寻任务作为目标。然后,构建多模态LLM模型,该模型接收文本和眼动数据作为输入,并输出对阅读目标的预测。最后,使用目标选择和文本重建等任务对模型进行评估。
关键创新:论文的关键创新在于首次提出了利用眼动数据解码开放式阅读目标的问题,并构建了相应的评估框架和数据集。此外,论文还探索了多种多模态LLM模型,并验证了其在目标解码任务上的有效性。与现有方法相比,该方法能够更准确地理解读者的阅读意图,并为个性化阅读辅助提供支持。
关键设计:论文中使用的多模态LLM模型包括判别式和生成式两种类型。判别式模型用于目标选择任务,通过对候选目标进行排序,选择最符合眼动数据的目标。生成式模型用于文本重建任务,通过生成文本描述来表达阅读目标。具体的网络结构和损失函数选择取决于具体的模型类型,但都旨在学习眼动数据与阅读目标之间的关联。
🖼️ 关键图片

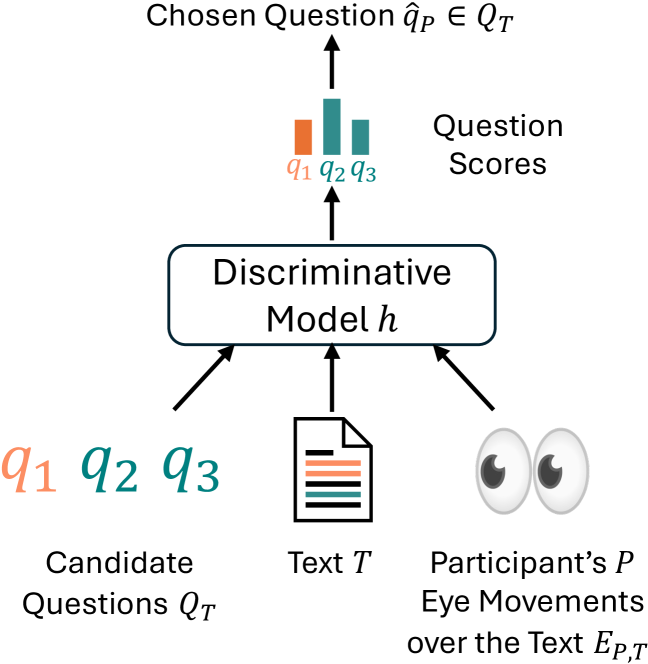
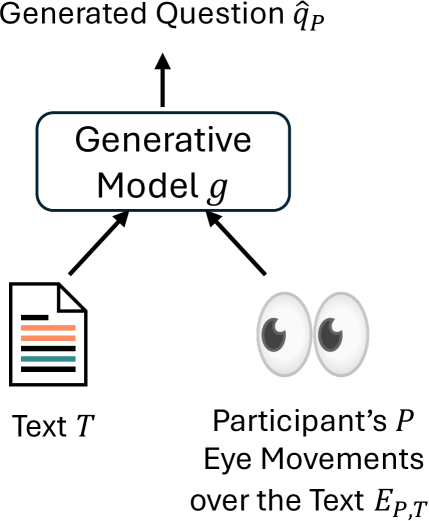
📊 实验亮点
实验结果表明,该方法在目标选择任务上取得了显著成功,能够从多个选项中准确选择正确的阅读目标。此外,在自由形式的文本重建任务上也取得了进展,能够生成一定程度上反映阅读目标的文本描述。这些结果验证了利用眼动数据解码开放式阅读目标的可行性。
🎯 应用场景
该研究成果可应用于教育领域,例如根据学生的阅读目标提供个性化的学习材料和辅导。在辅助技术方面,可以帮助残疾人士更高效地阅读和理解文本。此外,该技术还可用于信息检索和推荐系统,根据用户的阅读行为推荐相关内容。
📄 摘要(原文)
When reading, we often have specific information that interests us in a text. For example, you might be reading this paper because you are curious about LLMs for eye movements in reading, the experimental design, or perhaps you wonder ``This sounds like science fiction. Does it actually work?''. More broadly, in daily life, people approach texts with any number of text-specific goals that guide their reading behavior. In this work, we ask, for the first time, whether open-ended reading goals can be automatically decoded solely from eye movements in reading. To address this question, we introduce goal decoding tasks and evaluation frameworks using large-scale eye tracking for reading data in English with hundreds of text-specific information seeking tasks. We develop and compare several discriminative and generative multimodal text and eye movements LLMs for these tasks. Our experiments show considerable success on the task of selecting the correct goal among several options, and even progress towards free-form textual reconstruction of the precise goal formulation. These results open the door for further scientific investigation of goal driven reading, as well as the development of educational and assistive technologies that will rely on real-time decoding of reader goals from their eye movements.