Measuring Hong Kong Massive Multi-Task Language Understanding
作者: Chuxue Cao, Zhenghao Zhu, Junqi Zhu, Guoying Lu, Siyu Peng, Juntao Dai, Weijie Shi, Sirui Han, Yike Guo
分类: cs.CL
发布日期: 2025-05-04
💡 一句话要点
提出香港多任务语言理解基准HKMMLU,评估LLM在香港语言文化环境下的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言理解 大型语言模型 香港语言文化 评估基准 粤语 多任务学习 知识推理
📋 核心要点
- 现有评估基准缺乏对香港独特语言文化环境的针对性,无法准确衡量LLM在此环境下的理解能力。
- 构建包含多学科选择题和普通话-粤语翻译任务的HKMMLU基准,全面评估LLM的语言理解和文化知识。
- 实验结果表明,现有LLM在HKMMLU上的表现远低于其他基准,揭示了其在香港特定语言文化知识方面的不足。
📝 摘要(中文)
本文提出了HKMMLU,一个多任务语言理解基准,旨在评估大型语言模型(LLM)在香港特定语言能力和社会文化知识方面的表现。香港的语言环境独特,以传统中文书写,粤语口语,并具有独特的文化背景。HKMMLU包含66个学科的26698个多项选择题,分为科学、技术、工程和数学(STEM)、社会科学、人文和其他四个类别。为了评估LLM的多语言理解能力,还额外包含了90550个普通话-粤语翻译任务。在HKMMLU上对GPT-4o、Claude 3.7 Sonnet和18个不同规模的开源LLM进行了全面实验。结果表明,性能最佳的模型DeepSeek-V3的准确率也难以达到75%,远低于在MMLU和CMMLU上的表现。这一性能差距凸显了提高LLM在香港特定语言和知识领域能力的需求。此外,还研究了问题语言、模型大小、提示策略以及问题和推理token长度如何影响模型性能。HKMMLU有望显著推进LLM在多语言和跨文化背景下的发展,从而实现更广泛和更有影响力的应用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在香港特定语言文化环境下的理解能力评估问题。现有的多语言理解评估基准,如MMLU和CMMLU,无法充分覆盖香港的语言特点(传统中文书写,粤语口语)和文化背景,导致LLM在处理香港相关任务时表现不佳。因此,需要一个专门为香港设计的评估基准,以更准确地衡量LLM在此环境下的能力。
核心思路:论文的核心思路是构建一个包含多学科选择题和普通话-粤语翻译任务的综合性评估基准HKMMLU。选择题旨在评估LLM对香港社会文化知识的理解,而翻译任务则旨在评估其多语言理解能力,特别是普通话和粤语之间的转换能力。通过在HKMMLU上评估LLM的性能,可以更全面地了解其在香港语言文化环境下的优势和不足。
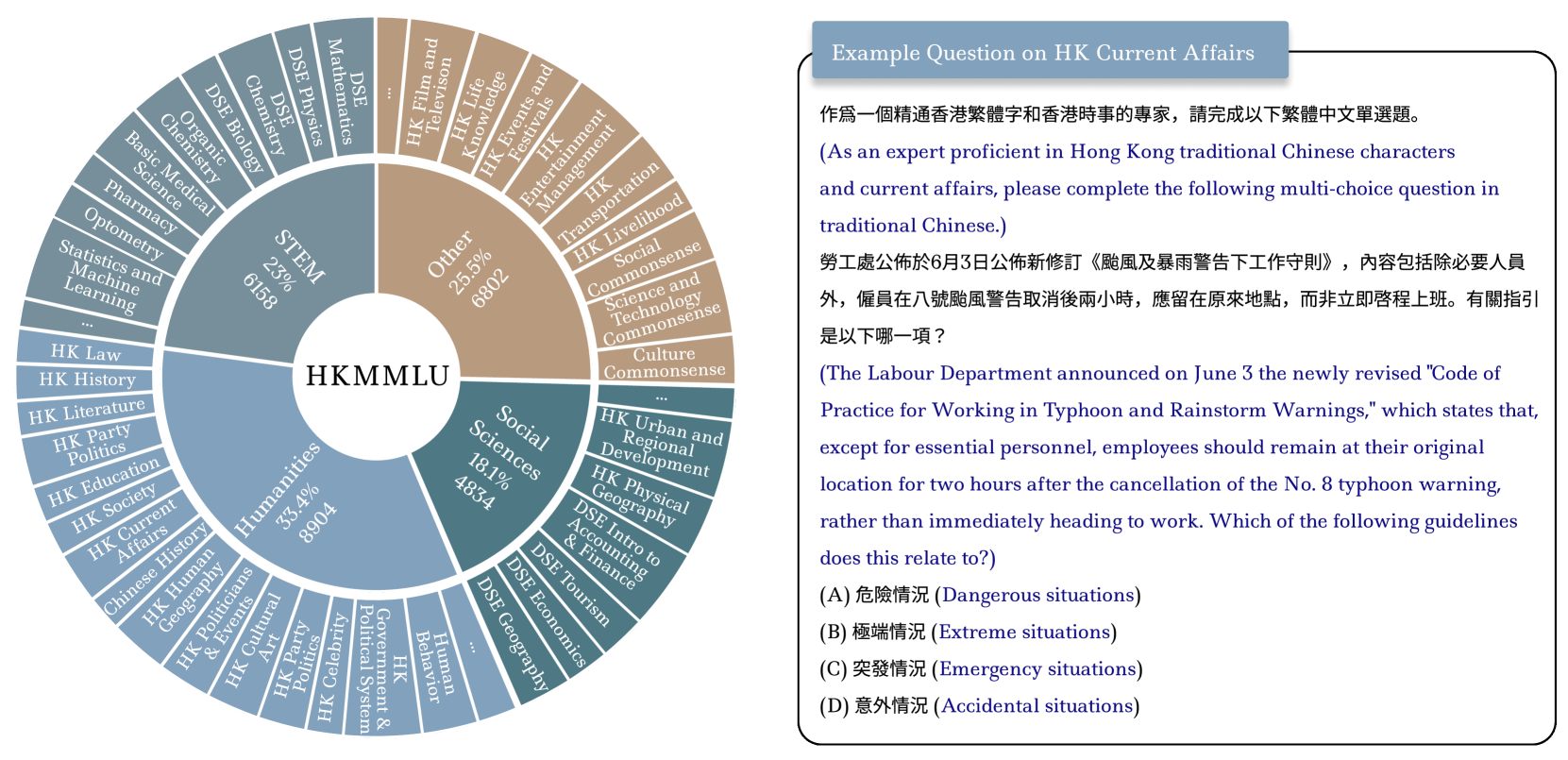
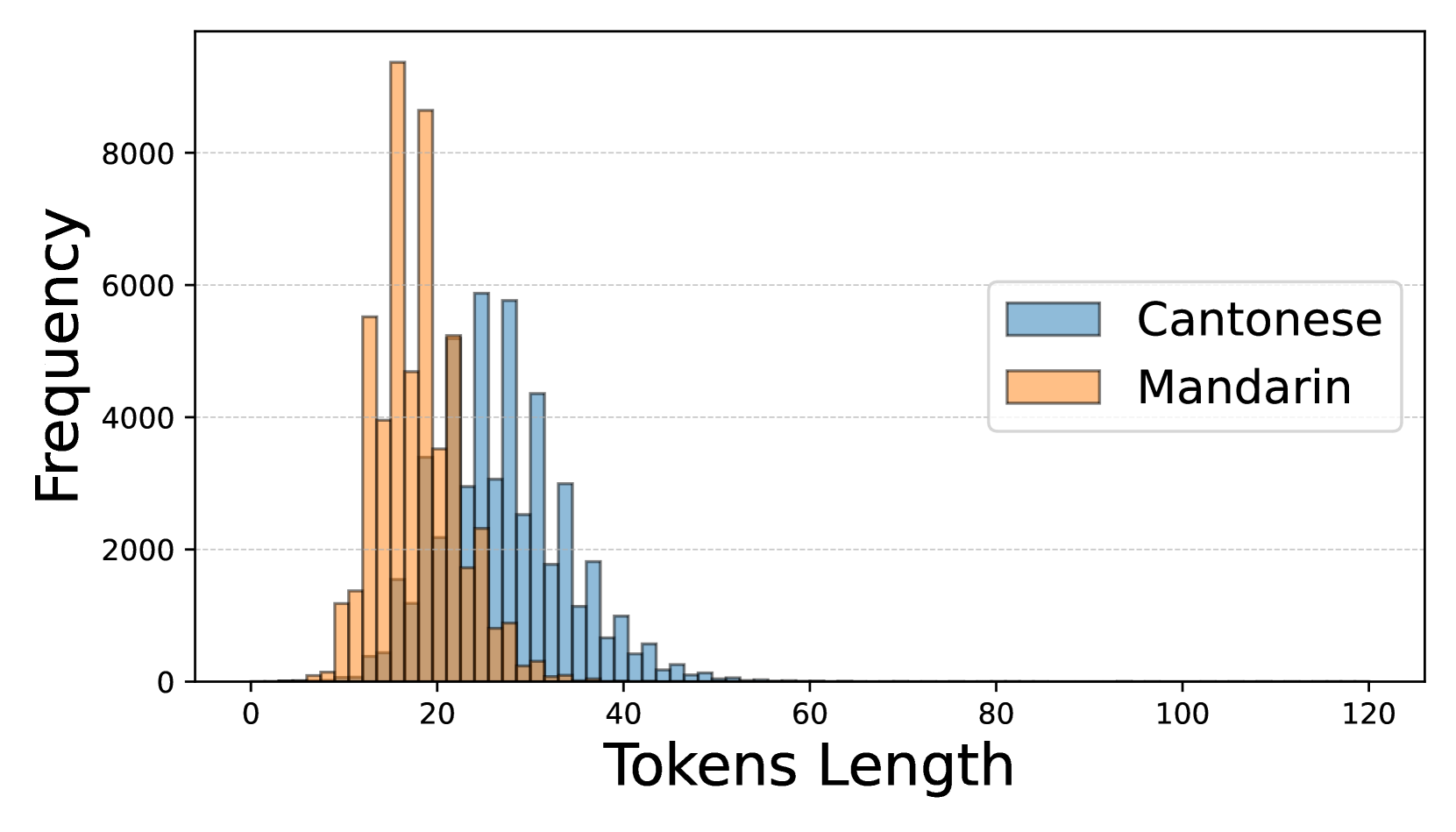
技术框架:HKMMLU基准主要包含两个部分:多项选择题和普通话-粤语翻译任务。多项选择题涵盖66个学科,分为科学、技术、工程和数学(STEM)、社会科学、人文和其他四个类别。每个问题包含一个问题和四个选项,要求LLM选择正确的答案。翻译任务包含90550个普通话-粤语翻译对,要求LLM将普通话文本翻译成粤语文本。
关键创新:HKMMLU的关键创新在于其针对香港特定语言文化环境的设计。它不仅包含了传统中文书写的内容,还考虑了粤语口语的特点,并涵盖了香港的社会文化知识。此外,HKMMLU还包含了大量的普通话-粤语翻译任务,以评估LLM的多语言理解能力。
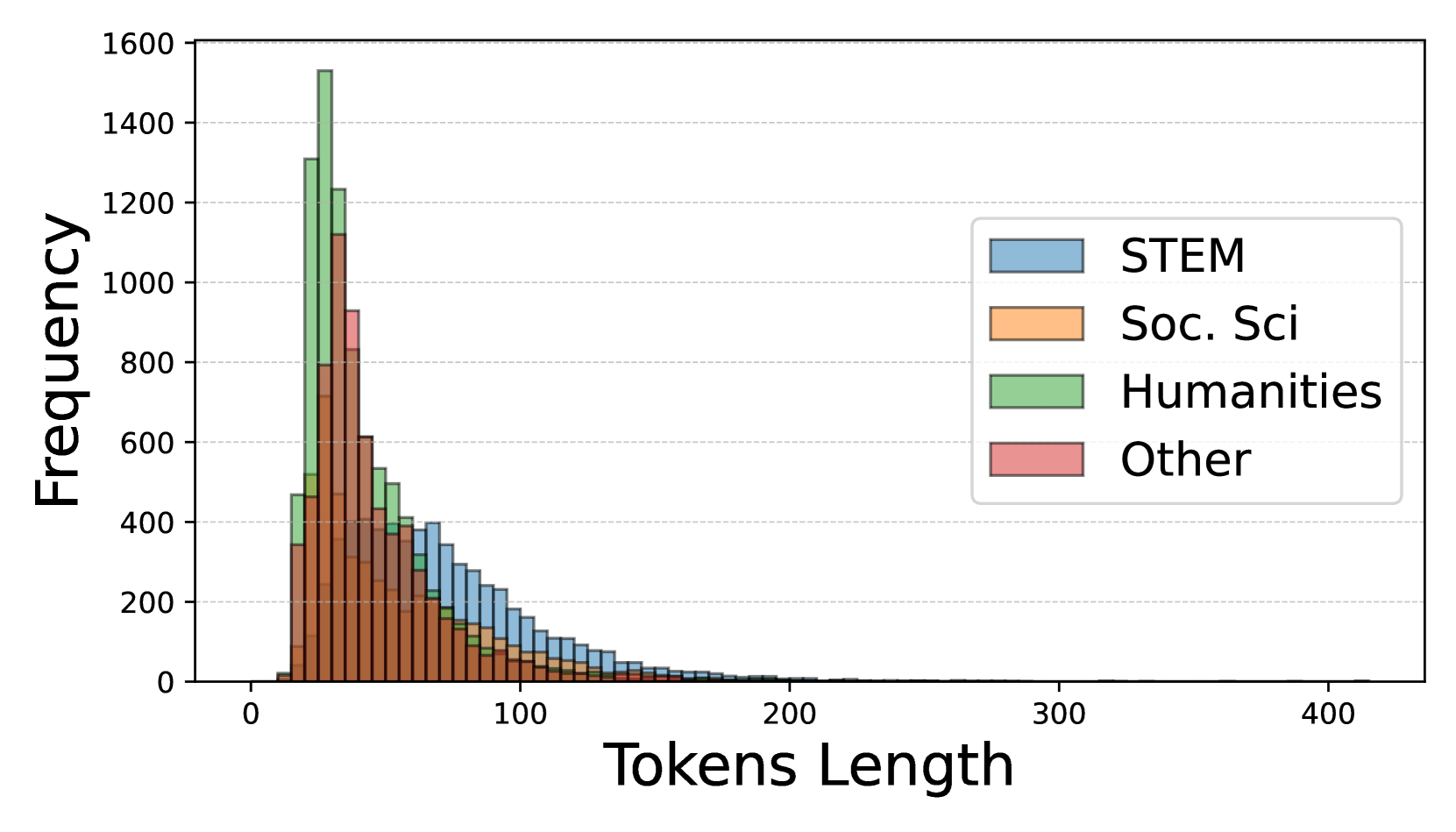
关键设计:HKMMLU的多项选择题涵盖了广泛的学科领域,以确保对LLM的知识覆盖面进行全面评估。翻译任务的设计考虑了普通话和粤语之间的差异,包括词汇、语法和表达方式等。论文还研究了问题语言、模型大小、提示策略以及问题和推理token长度等因素对模型性能的影响,为未来的研究提供了指导。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是性能最佳的模型DeepSeek-V3在HKMMLU上的准确率也低于75%,远低于其在MMLU和CMMLU上的表现。这表明现有LLM在香港特定语言文化知识方面存在显著不足。此外,研究还发现问题语言、模型大小、提示策略以及问题和推理token长度等因素都会影响模型性能。
🎯 应用场景
HKMMLU可用于评估和改进LLM在香港地区的语言理解和文化适应能力,从而促进LLM在教育、医疗、金融、法律等领域的应用。例如,可以利用HKMMLU来开发更智能的粤语聊天机器人、更准确的香港新闻摘要生成器以及更有效的香港本地化搜索引擎。
📄 摘要(原文)
Multilingual understanding is crucial for the cross-cultural applicability of Large Language Models (LLMs). However, evaluation benchmarks designed for Hong Kong's unique linguistic landscape, which combines Traditional Chinese script with Cantonese as the spoken form and its cultural context, remain underdeveloped. To address this gap, we introduce HKMMLU, a multi-task language understanding benchmark that evaluates Hong Kong's linguistic competence and socio-cultural knowledge. The HKMMLU includes 26,698 multi-choice questions across 66 subjects, organized into four categories: Science, Technology, Engineering, and Mathematics (STEM), Social Sciences, Humanities, and Other. To evaluate the multilingual understanding ability of LLMs, 90,550 Mandarin-Cantonese translation tasks were additionally included. We conduct comprehensive experiments on GPT-4o, Claude 3.7 Sonnet, and 18 open-source LLMs of varying sizes on HKMMLU. The results show that the best-performing model, DeepSeek-V3, struggles to achieve an accuracy of 75\%, significantly lower than that of MMLU and CMMLU. This performance gap highlights the need to improve LLMs' capabilities in Hong Kong-specific language and knowledge domains. Furthermore, we investigate how question language, model size, prompting strategies, and question and reasoning token lengths affect model performance. We anticipate that HKMMLU will significantly advance the development of LLMs in multilingual and cross-cultural contexts, thereby enabling broader and more impactful applications.