LecEval: An Automated Metric for Multimodal Knowledge Acquisition in Multimedia Learning
作者: Joy Lim Jia Yin, Daniel Zhang-Li, Jifan Yu, Haoxuan Li, Shangqing Tu, Yuanchun Wang, Zhiyuan Liu, Huiqin Liu, Lei Hou, Juanzi Li, Bin Xu
分类: cs.CL, cs.AI
发布日期: 2025-05-04
备注: 6 pages, 3 figures
🔗 代码/项目: GITHUB
💡 一句话要点
LecEval:一种用于多媒体学习中多模态知识获取的自动化评估指标
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多媒体学习 自动化评估 知识获取 幻灯片教学 认知理论
📋 核心要点
- 现有幻灯片教学质量评估方法存在可扩展性差、无法充分捕捉上下文以及存在偏差等问题。
- LecEval基于多媒体学习认知理论,通过内容相关性、表达清晰度等四个维度评估幻灯片教学效果。
- 实验表明,LecEval模型在幻灯片教学质量评估方面,比现有指标更准确,更贴近人工评估结果。
📝 摘要(中文)
评估基于幻灯片的多媒体教学质量极具挑战。现有的方法,如人工评估、基于参考的指标和大型语言模型评估器,在可扩展性、上下文捕捉或偏差方面都存在局限性。本文介绍了一种基于Mayer多媒体学习认知理论的自动化指标LecEval,用于评估基于幻灯片学习中的多模态知识获取效果。LecEval使用四个标准来评估有效性:内容相关性(CR)、表达清晰度(EC)、逻辑结构(LS)和受众参与度(AE)。我们整理了一个大规模数据集,包含来自50多个在线课程视频的2000多张幻灯片,并对这些幻灯片进行了细粒度的人工评分。基于该数据集训练的模型,与现有指标相比,表现出更高的准确性和适应性,弥合了自动化评估和人工评估之间的差距。我们已在https://github.com/JoylimJY/LecEval上发布了我们的数据集和工具包。
🔬 方法详解
问题定义:论文旨在解决多媒体教学中,特别是基于幻灯片的教学内容质量评估问题。现有方法,如人工评估成本高昂且难以规模化,基于参考的指标需要预先定义的标准答案,而大型语言模型评估器可能存在偏差,无法准确反映教学内容的质量。这些方法都难以高效、客观地评估幻灯片教学的有效性。
核心思路:论文的核心思路是,基于Mayer的多媒体学习认知理论,将教学质量分解为几个关键维度,并构建自动化指标来评估这些维度。通过学习大量人工标注的数据,使模型能够模仿人类专家对教学内容的判断,从而实现高效、客观的评估。
技术框架:LecEval的整体框架包含以下几个主要模块:1) 数据收集与标注:构建包含大量幻灯片及其对应人工评分的数据集。2) 特征提取:从幻灯片中提取文本、图像等多种模态的特征。3) 模型训练:使用提取的特征训练模型,使其能够预测幻灯片在内容相关性、表达清晰度、逻辑结构和受众参与度等方面的得分。4) 评估与分析:将LecEval的预测结果与人工评分进行比较,评估其性能。
关键创新:LecEval的关键创新在于:1) 基于多媒体学习认知理论构建评估指标,使其更符合教学规律。2) 构建大规模多模态数据集,为模型训练提供充足的数据支持。3) 提出一种自动化评估方法,能够高效、客观地评估幻灯片教学质量。与现有方法相比,LecEval更具可扩展性和适应性。
关键设计:论文中关于模型结构、损失函数和参数设置等技术细节并未详细描述,属于未知信息。数据集的构建和标注过程是关键设计之一,保证了数据质量和多样性。具体采用何种模型结构(例如,Transformer或其他深度学习模型)以及如何融合多模态特征,需要在论文原文或代码中进一步考察。
🖼️ 关键图片

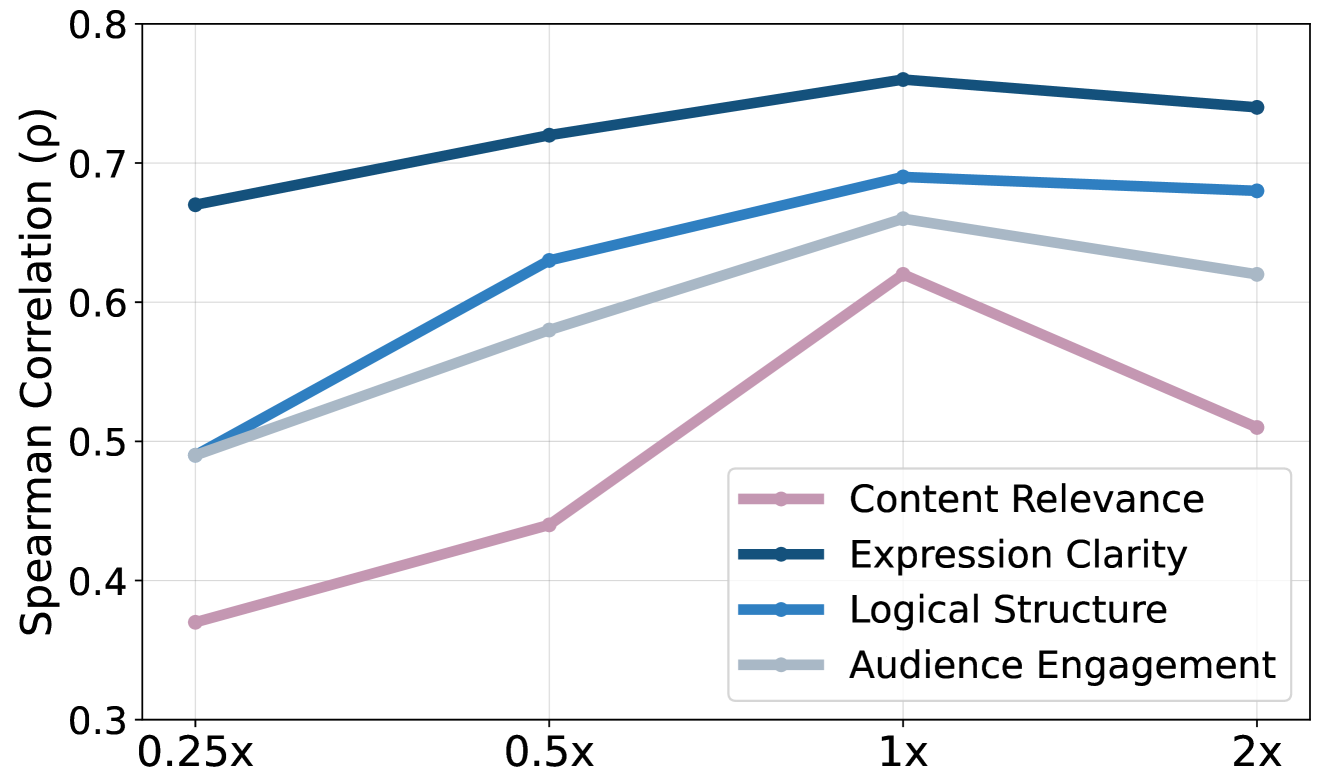
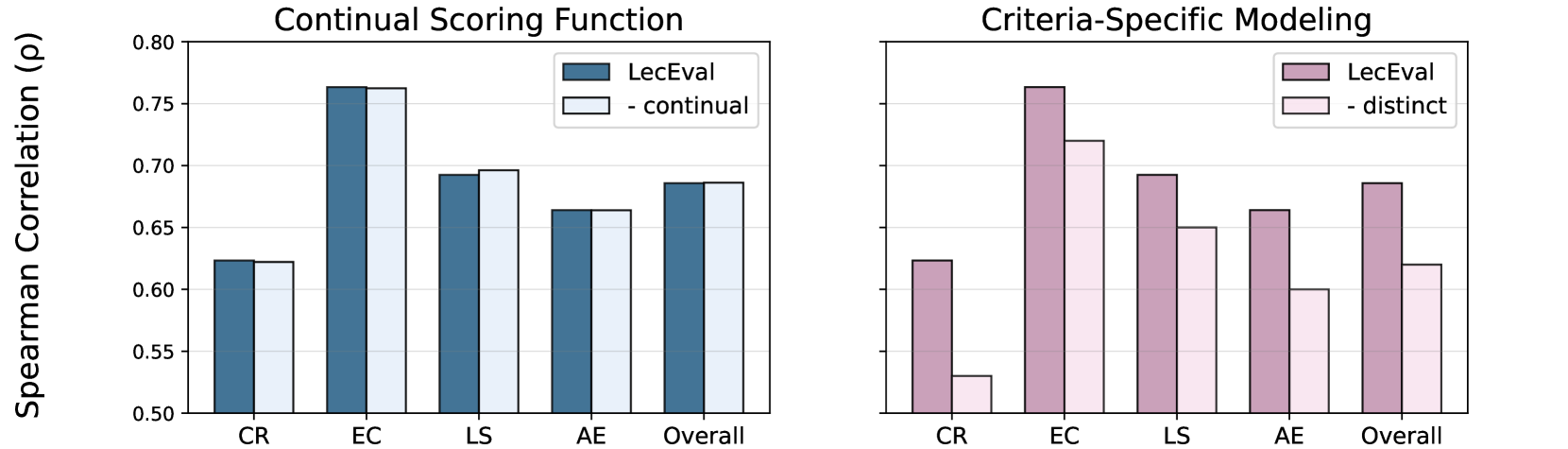
📊 实验亮点
论文构建了一个包含2000多张幻灯片的大规模数据集,并在此基础上训练了一个LecEval模型。实验结果表明,LecEval模型在幻灯片教学质量评估方面,比现有指标更准确,更贴近人工评估结果。具体的性能提升数据需要在论文原文中查找。
🎯 应用场景
LecEval可应用于在线教育平台,自动评估课程质量,为教师提供改进建议。它还可以用于筛选优质教学资源,帮助学生选择更有效的学习材料。此外,LecEval还可用于评估企业培训材料,提升员工学习效果,具有广泛的应用前景和实际价值。
📄 摘要(原文)
Evaluating the quality of slide-based multimedia instruction is challenging. Existing methods like manual assessment, reference-based metrics, and large language model evaluators face limitations in scalability, context capture, or bias. In this paper, we introduce LecEval, an automated metric grounded in Mayer's Cognitive Theory of Multimedia Learning, to evaluate multimodal knowledge acquisition in slide-based learning. LecEval assesses effectiveness using four rubrics: Content Relevance (CR), Expressive Clarity (EC), Logical Structure (LS), and Audience Engagement (AE). We curate a large-scale dataset of over 2,000 slides from more than 50 online course videos, annotated with fine-grained human ratings across these rubrics. A model trained on this dataset demonstrates superior accuracy and adaptability compared to existing metrics, bridging the gap between automated and human assessments. We release our dataset and toolkits at https://github.com/JoylimJY/LecEval.