Efficient Shapley Value-based Non-Uniform Pruning of Large Language Models
作者: Chuan Sun, Han Yu, Lizhen Cui, Xiaoxiao Li
分类: cs.CL, cs.AI
发布日期: 2025-05-03 (更新: 2025-05-21)
💡 一句话要点
提出基于Shapley值的非均匀剪枝方法,提升大语言模型剪枝后的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 非均匀剪枝 Shapley值 模型压缩
📋 核心要点
- 传统逐层剪枝方法采用均匀稀疏策略,忽略了Transformer层重要性的差异,导致性能欠佳。
- 论文提出SV-NUP方法,通过Shapley值量化各层贡献,实现非均匀剪枝,保留关键参数。
- 实验表明,SV-NUP在LLaMA等模型上显著降低了困惑度,优于SparseGPT等基线方法。
📝 摘要(中文)
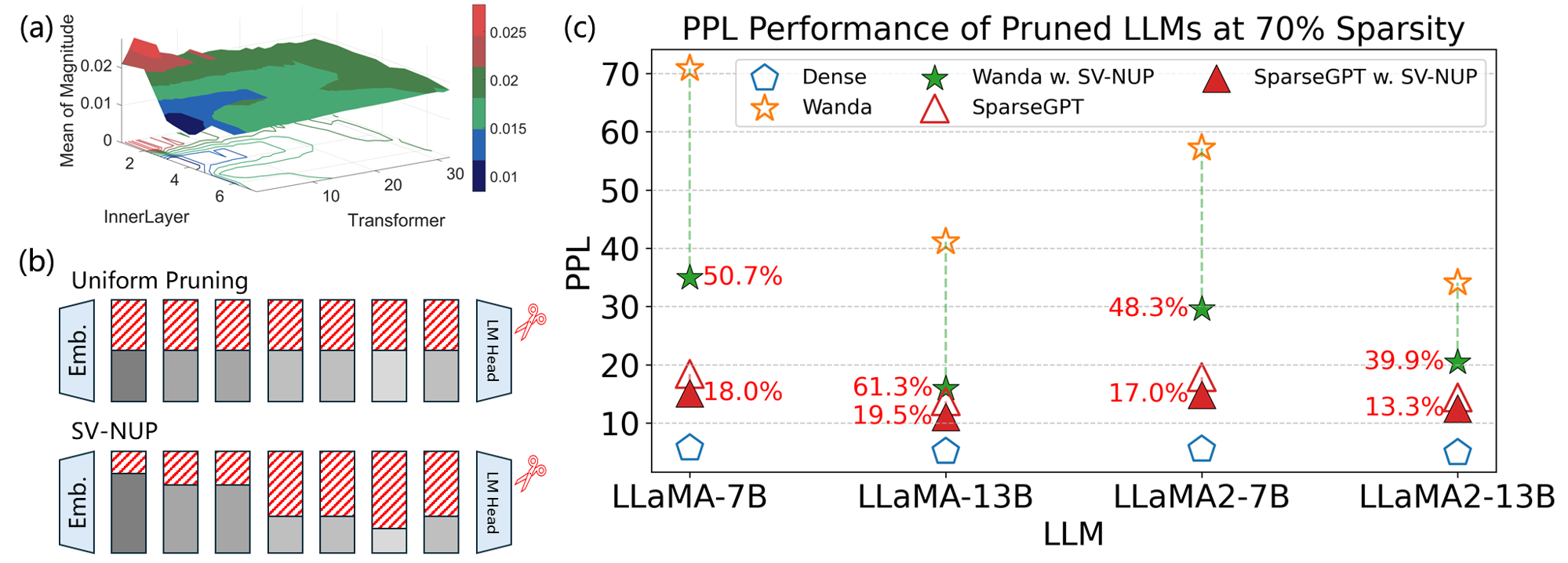
本文提出了一种基于Shapley值的非均匀剪枝(SV-NUP)方法,用于大语言模型(LLMs)的剪枝。该方法量化了每个Transformer层对整体模型性能的贡献,从而能够为不同的层分配定制的剪枝预算,以保留关键参数。为了进一步提高效率,设计了一种基于滑动窗口的Shapley值近似方法,与精确的Shapley值计算方法相比,大大降低了计算开销。在包括LLaMA-v1、LLaMA-v2和OPT在内的各种LLM上的大量实验表明,该方法是有效的。结果表明,非均匀剪枝显著提高了剪枝模型的性能。值得注意的是,在70%的稀疏度下,SV-NUP在LLaMA-7B和LLaMA-13B上分别实现了18.01%和19.55%的困惑度(PPL)降低,优于SparseGPT。
🔬 方法详解
问题定义:现有的大语言模型剪枝方法通常采用均匀剪枝策略,即对所有Transformer层应用相同的稀疏度。然而,不同的Transformer层对模型的性能贡献不同,均匀剪枝无法区分重要层和非重要层,导致剪枝后的模型性能下降。因此,如何根据各层的重要性进行非均匀剪枝,以在保持模型性能的同时减小模型尺寸,是一个亟待解决的问题。
核心思路:论文的核心思路是利用Shapley值来量化每个Transformer层对模型性能的贡献。Shapley值是一种博弈论概念,可以公平地分配合作博弈中每个参与者的贡献。在这里,每个Transformer层被视为一个参与者,模型的性能被视为合作博弈的收益。通过计算每个Transformer层的Shapley值,可以确定其对模型性能的重要性,从而为不同的层分配不同的剪枝预算。
技术框架:SV-NUP方法的整体框架包括以下几个主要阶段:1) 计算每个Transformer层的Shapley值。2) 根据Shapley值确定每个层的剪枝预算。3) 根据剪枝预算对模型进行剪枝。4) 对剪枝后的模型进行微调。为了提高Shapley值的计算效率,论文提出了一种基于滑动窗口的Shapley值近似方法。
关键创新:该论文最重要的技术创新点在于将Shapley值应用于大语言模型的非均匀剪枝。与传统的均匀剪枝方法相比,SV-NUP方法能够根据各层的重要性进行剪枝,从而更好地保留关键参数,提高剪枝后的模型性能。此外,提出的滑动窗口Shapley值近似方法有效地降低了计算复杂度。
关键设计:滑动窗口Shapley值近似方法通过在一个小的窗口内计算Shapley值来降低计算复杂度。窗口大小是一个关键参数,需要根据模型的规模和计算资源进行调整。此外,论文还采用了基于梯度的剪枝策略,根据参数的梯度大小来确定哪些参数应该被剪枝。损失函数采用交叉熵损失,微调阶段采用AdamW优化器。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SV-NUP方法在LLaMA-7B和LLaMA-13B模型上,在70%的稀疏度下,分别实现了18.01%和19.55%的困惑度(PPL)降低,显著优于SparseGPT等基线方法。这表明SV-NUP方法能够有效地提高剪枝后模型的性能,并具有很强的竞争力。
🎯 应用场景
该研究成果可应用于各种需要部署大语言模型的场景,例如移动设备、边缘计算设备等。通过非均匀剪枝,可以在显著减小模型尺寸的同时,保持模型的性能,从而降低部署成本和计算资源消耗。该方法还有助于开发更高效、更轻量级的大语言模型,推动人工智能技术在资源受限环境中的应用。
📄 摘要(原文)
Pruning large language models (LLMs) is a promising solution for reducing model sizes and computational complexity while preserving performance. Traditional layer-wise pruning methods often adopt a uniform sparsity approach across all layers, which leads to suboptimal performance due to the varying significance of individual transformer layers within the model not being accounted for. To this end, we propose the Shapley Value-based Non-Uniform Pruning (SV-NUP) method for LLMs. This approach quantifies the contribution of each transformer layer to the overall model performance, enabling the assignment of tailored pruning budgets to different layers to retain critical parameters. To further improve efficiency, we design the Sliding Window-based Shapley Value approximation method. It substantially reduces computational overhead compared to exact SV calculation methods. Extensive experiments on various LLMs including LLaMA-v1, LLaMA-v2 and OPT demonstrate the effectiveness of the proposed approach. The results reveal that non-uniform pruning significantly enhances the performance of pruned models. Notably, SV-NUP achieves a reduction in perplexity (PPL) of 18.01% and 19.55% on LLaMA-7B and LLaMA-13B, respectively, compared to SparseGPT at 70% sparsity.