Towards High-Fidelity Synthetic Multi-platform Social Media Datasets via Large Language Models
作者: Henry Tari, Nojus Sereiva, Rishabh Kaushal, Thales Bertaglia, Adriana Iamnitchi
分类: cs.CL, cs.CY
发布日期: 2025-05-02
备注: arXiv admin note: text overlap with arXiv:2407.08323
💡 一句话要点
提出基于大语言模型的多平台社交媒体数据集生成方法,解决数据获取难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交媒体数据集 大型语言模型 数据生成 多平台数据 合成数据 自然语言处理 提示工程
📋 核心要点
- 社交媒体数据获取受限,跨平台数据尤其稀缺,阻碍了相关研究的深入开展。
- 利用大语言模型生成多平台社交媒体数据,通过主题提示确保数据在词汇和语义上的相关性。
- 实验表明,该方法具有潜力,但不同模型表现各异,可能需要后处理以提高数据保真度。
📝 摘要(中文)
社交媒体数据集对于研究虚假信息、影响力操作、仇恨言论检测或网红营销等主题至关重要。然而,由于成本和平台限制,访问社交媒体数据集通常受到限制。获取跨多个平台的数据集对于理解数字生态系统至关重要,但尤其具有挑战性。本文探讨了大型语言模型在多个平台上创建词汇和语义相关的社交媒体数据集的潜力,旨在匹配真实数据的质量。我们提出了基于主题的多平台提示,并采用各种语言模型从两个真实数据集中生成合成数据,每个数据集包含来自三个不同社交媒体平台的帖子。我们评估了合成数据的词汇和语义属性,并将其与真实数据的属性进行比较。我们的实证研究结果表明,使用大型语言模型生成合成多平台社交媒体数据是有希望的,不同的语言模型在保真度方面表现不同,并且可能需要后处理方法来生成用于研究的高保真合成数据集。除了对三种最先进的大型语言模型进行实证评估外,我们的贡献还包括特定于多平台社交媒体数据集的新保真度指标。
🔬 方法详解
问题定义:当前社交媒体研究严重依赖数据集,但获取真实数据集面临成本高昂、平台限制等问题,尤其缺乏跨平台的数据集,这限制了对复杂数字生态系统的理解。现有方法难以生成高质量、多平台、语义相关的社交媒体数据。
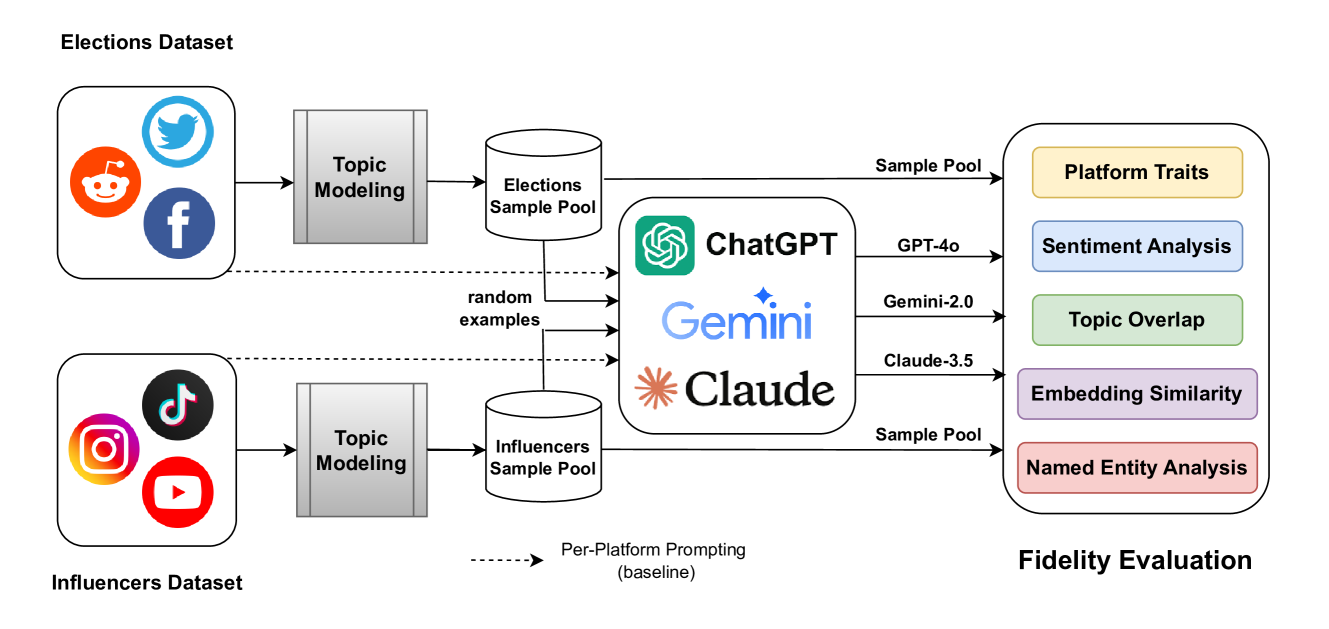
核心思路:利用大型语言模型(LLM)强大的文本生成能力,通过精心设计的提示(prompting)来引导LLM生成具有特定主题和平台特征的社交媒体帖子。核心在于控制生成过程,使其在词汇、语义和平台风格上尽可能接近真实数据。
技术框架:该方法包含以下主要阶段:1) 数据准备:收集真实的多平台社交媒体数据集作为参考。2) 主题提取:从真实数据集中提取主题,作为生成合成数据的依据。3) 提示设计:设计基于主题的多平台提示,引导LLM生成特定主题和平台风格的帖子。4) 数据生成:使用不同的LLM(例如,GPT-3)生成合成数据。5) 数据评估:使用词汇和语义指标评估合成数据的质量,并与真实数据进行比较。
关键创新:该方法的核心创新在于利用LLM生成多平台社交媒体数据,并提出了一种基于主题的提示方法,以确保生成的数据在词汇和语义上与真实数据相关。此外,论文还提出了针对多平台社交媒体数据集的新的保真度指标。
关键设计:关键设计包括:1) 主题提示:提示的设计需要包含主题信息、平台信息(例如,Twitter、Facebook、Instagram)以及期望的帖子风格。2) LLM选择:选择合适的LLM对于生成高质量的数据至关重要。论文评估了多种LLM的性能。3) 后处理:根据评估结果,可能需要对生成的数据进行后处理,例如,过滤掉不相关的帖子或调整帖子的风格。
🖼️ 关键图片
📊 实验亮点
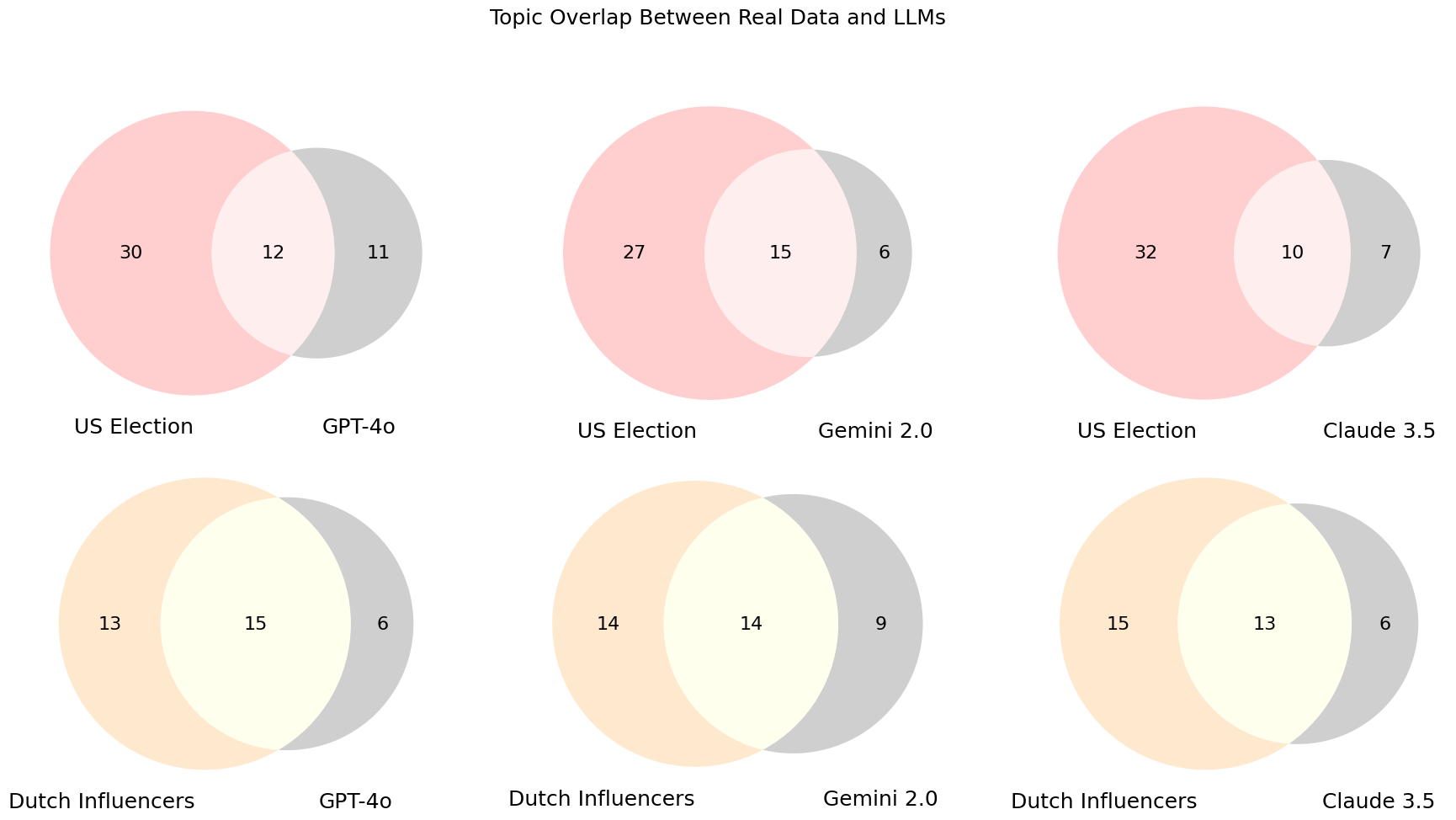
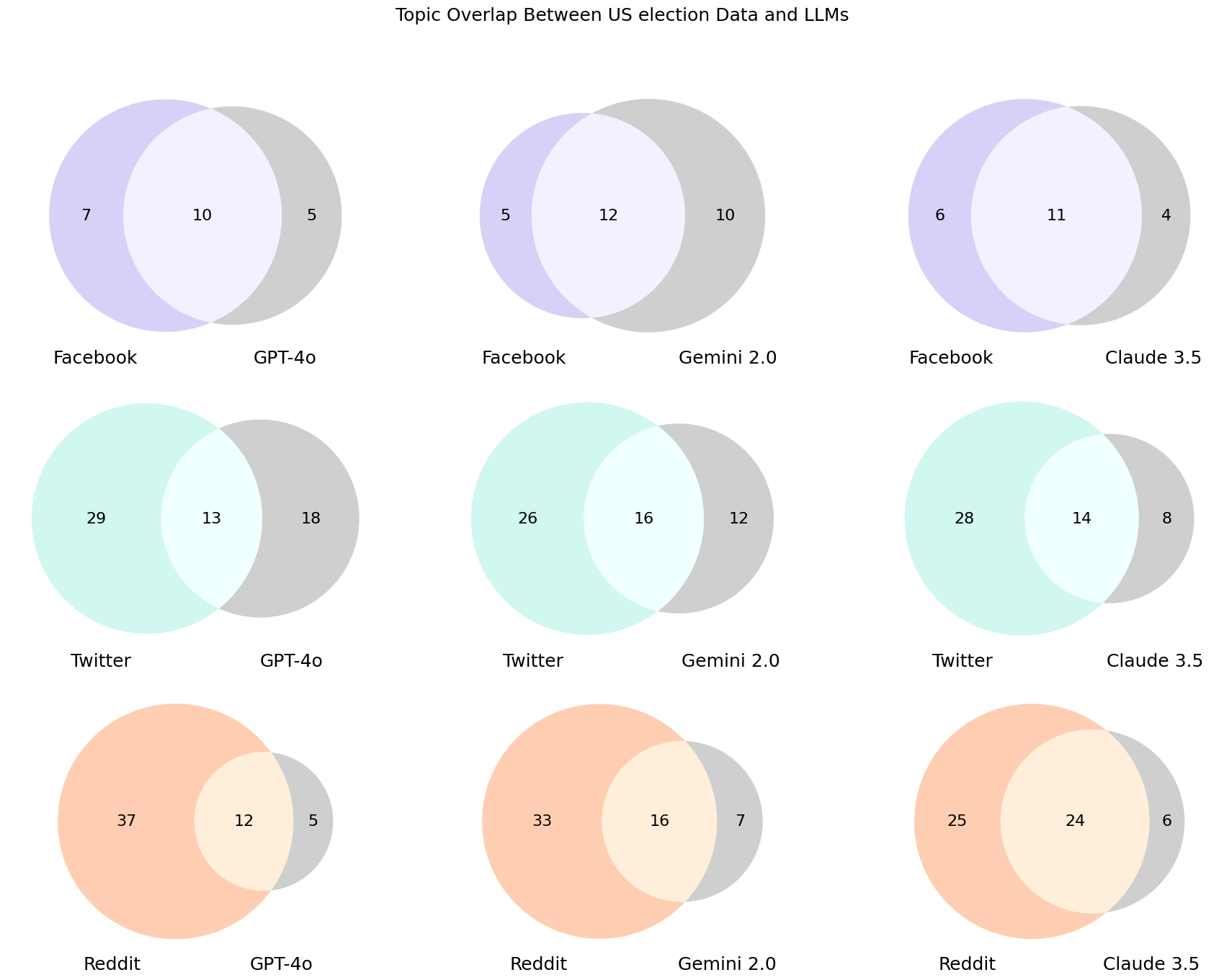
实验结果表明,使用大型语言模型生成合成多平台社交媒体数据是可行的。不同的语言模型在保真度方面表现不同,例如,某些模型在生成特定平台的帖子时表现更好。实验还表明,可能需要后处理方法来提高合成数据的质量。论文提出了新的保真度指标,用于评估合成数据的质量。
🎯 应用场景
该研究成果可应用于生成用于训练和评估社交媒体分析算法的合成数据集,例如,虚假信息检测、情感分析、影响力分析等。这有助于解决数据稀缺问题,降低研究成本,并促进相关领域的发展。此外,该方法还可以用于生成特定主题或平台的社交媒体数据,以满足不同的研究需求。
📄 摘要(原文)
Social media datasets are essential for research on a variety of topics, such as disinformation, influence operations, hate speech detection, or influencer marketing practices. However, access to social media datasets is often constrained due to costs and platform restrictions. Acquiring datasets that span multiple platforms, which is crucial for understanding the digital ecosystem, is particularly challenging. This paper explores the potential of large language models to create lexically and semantically relevant social media datasets across multiple platforms, aiming to match the quality of real data. We propose multi-platform topic-based prompting and employ various language models to generate synthetic data from two real datasets, each consisting of posts from three different social media platforms. We assess the lexical and semantic properties of the synthetic data and compare them with those of the real data. Our empirical findings show that using large language models to generate synthetic multi-platform social media data is promising, different language models perform differently in terms of fidelity, and a post-processing approach might be needed for generating high-fidelity synthetic datasets for research. In addition to the empirical evaluation of three state of the art large language models, our contributions include new fidelity metrics specific to multi-platform social media datasets.