AURA: A Diagnostic Framework for Tracking User Satisfaction of Interactive Planning Agents
作者: Takyoung Kim, Janvijay Singh, Shuhaib Mehri, Emre Can Acikgoz, Sagnik Mukherjee, Nimet Beyza Bozdag, Sumuk Shashidhar, Gokhan Tur, Dilek Hakkani-Tür
分类: cs.CL, cs.AI
发布日期: 2025-05-02 (更新: 2025-12-05)
备注: NeurIPS 2025 MTI-LLM Workshop. Full version is under review
💡 一句话要点
AURA:用于追踪交互式规划Agent用户满意度的诊断框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 交互式规划Agent 用户满意度评估 诊断框架 大型语言模型 行为阶段分析
📋 核心要点
- 现有Agent评估侧重于任务完成度,忽略了用户与Agent交互过程中的满意度体验,导致评估结果与实际用户感受存在偏差。
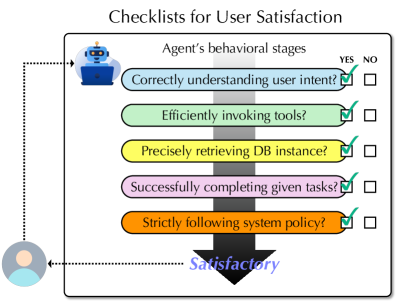
- AURA框架将交互式任务规划Agent的行为分解为多个阶段,并设计原子LLM评估标准,从而全面诊断Agent的优缺点。
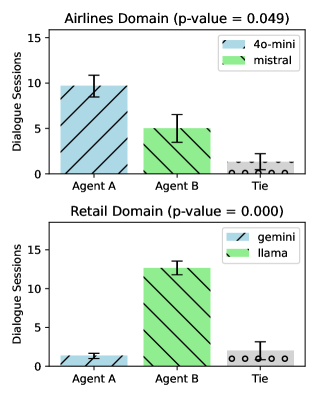
- 实验表明,Agent在不同行为阶段表现各异,用户满意度受最终结果和中间行为共同影响,揭示了提升用户体验的关键因素。
📝 摘要(中文)
大型语言模型(LLM)在指令遵循和上下文理解方面的能力日益增强,催生了Agent应用的时代。其中,任务规划Agent在涉及复杂内部流程(如上下文理解、工具管理和响应生成)的实际场景中尤为突出。然而,现有的基准主要基于任务完成情况来评估Agent的性能,以此作为整体有效性的代理。我们假设,仅仅提高任务完成率与最大化用户满意度并不一致,因为用户与整个Agent过程交互,而不仅仅是最终结果。为了解决这一差距,我们提出了AURA,一个Agent-User交互评估框架,它概念化了交互式任务规划Agent的行为阶段。AURA通过一套原子LLM评估标准,对Agent进行全面评估,使研究人员和从业人员能够诊断Agent决策流程中的具体优势和劣势。我们的分析表明,Agent在不同的行为阶段表现出色,用户满意度受结果和中间行为的影响。我们还强调了未来的方向,包括利用多个Agent的系统以及任务规划中用户模拟器的局限性。
🔬 方法详解
问题定义:现有任务规划Agent的评估主要依赖于任务完成度,而忽略了用户在与Agent交互过程中的体验。这种评估方式无法准确反映用户的真实满意度,因为用户不仅关注最终结果,也关注Agent在整个交互过程中的行为表现。因此,如何更全面、更准确地评估交互式任务规划Agent的用户满意度成为一个亟待解决的问题。
核心思路:AURA框架的核心思路是将Agent与用户的交互过程分解为多个行为阶段,并针对每个阶段设计相应的评估指标。通过对每个阶段的细致评估,可以更全面地了解Agent的优势和劣势,从而为改进Agent的设计和提升用户满意度提供指导。这种分解和评估的方法能够更准确地捕捉用户在交互过程中的感受,从而更有效地评估Agent的性能。
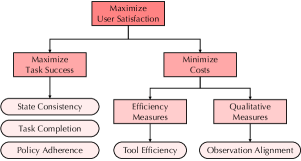
技术框架:AURA框架包含以下主要模块/阶段:1) 行为阶段划分:将Agent与用户的交互过程划分为多个具有明确定义的行为阶段,例如上下文理解、工具选择、响应生成等。2) 原子LLM评估标准设计:针对每个行为阶段,设计一套原子LLM评估标准,用于评估Agent在该阶段的表现。这些标准可以是基于LLM的自动评估指标,也可以是人工评估指标。3) 用户满意度评估:通过用户调查、用户行为分析等方式,收集用户对Agent的满意度数据。4) 诊断分析:将Agent在各个行为阶段的评估结果与用户满意度数据进行关联分析,从而诊断Agent的优势和劣势,并找出影响用户满意度的关键因素。
关键创新:AURA框架的关键创新在于其对交互式任务规划Agent的评估方式。与传统的只关注任务完成度的评估方式不同,AURA框架关注Agent在整个交互过程中的行为表现,并将其分解为多个行为阶段进行评估。这种细粒度的评估方式能够更全面、更准确地反映用户的真实满意度,从而为改进Agent的设计和提升用户体验提供更有效的指导。
关键设计:AURA框架的关键设计包括:1) 行为阶段的划分标准:如何合理地划分Agent与用户的交互过程,使其既能反映Agent的关键行为,又能方便评估。2) 原子LLM评估标准的选择:如何选择合适的LLM评估标准,使其能够准确地评估Agent在各个行为阶段的表现。3) 用户满意度数据的收集方法:如何设计用户调查问卷或用户行为分析方法,使其能够准确地收集用户对Agent的满意度数据。这些设计直接影响着AURA框架的评估效果和诊断结果。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了AURA框架的有效性,表明Agent在不同行为阶段表现各异,用户满意度受最终结果和中间行为共同影响。实验结果还揭示了影响用户满意度的关键因素,例如Agent的上下文理解能力、工具选择能力和响应生成能力。这些发现为改进交互式任务规划Agent的设计和提升用户体验提供了重要的指导。
🎯 应用场景
AURA框架可应用于各种交互式任务规划Agent的评估和改进,例如智能助手、对话机器人、自动化客服等。通过AURA框架,开发者可以更全面地了解Agent的优势和劣势,从而针对性地进行改进,提升用户满意度。此外,AURA框架还可以用于比较不同Agent的性能,为用户选择合适的Agent提供参考。
📄 摘要(原文)
The growing capabilities of large language models (LLMs) in instruction-following and context-understanding lead to the era of agents with numerous applications. Among these, task planning agents have become especially prominent in realistic scenarios involving complex internal pipelines, such as context understanding, tool management, and response generation. However, existing benchmarks predominantly evaluate agent performance based on task completion as a proxy for overall effectiveness. We hypothesize that merely improving task completion is misaligned with maximizing user satisfaction, as users interact with the entire agentic process and not only the end result. To address this gap, we propose AURA, an Agent-User inteRaction Assessment framework that conceptualizes the behavioral stages of interactive task planning agents. AURA offers a comprehensive assessment of agent through a set of atomic LLM evaluation criteria, allowing researchers and practitioners to diagnose specific strengths and weaknesses within the agent's decision-making pipeline. Our analyses show that agents excel in different behavioral stages, with user satisfaction shaped by both outcomes and intermediate behaviors. We also highlight future directions, including systems that leverage multiple agents and the limitations of user simulators in task planning.