Position: Enough of Scaling LLMs! Lets Focus on Downscaling
作者: Yash Goel, Ayan Sengupta, Tanmoy Chakraborty
分类: cs.CL
发布日期: 2025-05-02 (更新: 2025-05-25)
💡 一句话要点
突破LLM规模瓶颈:提出一种关注模型小型化的新范式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型小型化 神经缩放定律 资源效率 可持续AI
📋 核心要点
- 现有LLM过度依赖模型和数据规模扩展,导致计算成本高昂、环境影响显著,且部署受限。
- 论文提出一种LLM小型化框架,旨在降低资源需求的同时,维持甚至提升模型性能。
- 该研究倡导一种更可持续、高效和可访问的LLM开发方法,以应对传统缩放范式的局限性。
📝 摘要(中文)
本文挑战了当前大型语言模型(LLM)开发中对神经缩放定律的过度关注,并提倡将范式转变为模型小型化。虽然缩放定律为通过增加模型和数据集大小来提高性能提供了关键见解,但我们强调了这种方法的重大局限性,尤其是在计算效率、环境影响和部署约束方面。为了应对这些挑战,我们提出了一个用于LLM小型化的整体框架,该框架旨在在大幅降低资源需求的同时保持性能。本文概述了摆脱传统缩放范式的实用策略,倡导一种更可持续、高效和可访问的LLM开发方法。
🔬 方法详解
问题定义:当前大型语言模型(LLM)的研究主要集中在通过扩大模型规模和数据集来提升性能,即遵循神经缩放定律。然而,这种方法带来了诸多问题,包括计算资源消耗巨大、环境影响严重以及部署难度增加。现有的LLM模型往往难以在资源受限的设备上运行,阻碍了其广泛应用。
核心思路:本文的核心思路是转变LLM的研究方向,从追求更大的模型规模转向关注模型小型化。通过设计更高效的模型结构、采用更有效的训练方法以及进行模型压缩等手段,在保证甚至提升模型性能的同时,大幅降低模型的大小和计算复杂度。这样可以降低计算成本、减少环境影响,并使LLM更容易部署在各种设备上。
技术框架:论文提出了一个整体的LLM小型化框架,但具体的技术框架细节未知。根据摘要推断,该框架可能包含以下几个主要模块:1) 模型结构优化:设计更紧凑、更高效的模型结构,例如使用更少的参数或采用更先进的注意力机制。2) 训练方法改进:采用更有效的训练策略,例如知识蒸馏、量化训练或剪枝等,以在较小的模型上获得更好的性能。3) 模型压缩技术:应用各种模型压缩技术,例如权重剪枝、量化或知识蒸馏等,以进一步减小模型的大小。
关键创新:该论文的关键创新在于其研究方向的转变,即从关注模型规模扩展转向关注模型小型化。这种转变有望解决当前LLM发展面临的诸多问题,并推动LLM在更广泛的领域得到应用。此外,该论文提出的整体小型化框架也可能包含一些新的技术创新,但具体细节未知。
关键设计:由于论文摘要中没有提供关于关键参数设置、损失函数、网络结构等技术细节,因此这部分内容未知。未来的研究可能会涉及设计新的损失函数来鼓励模型学习更紧凑的表示,或者探索新的网络结构来提高模型的效率。
🖼️ 关键图片

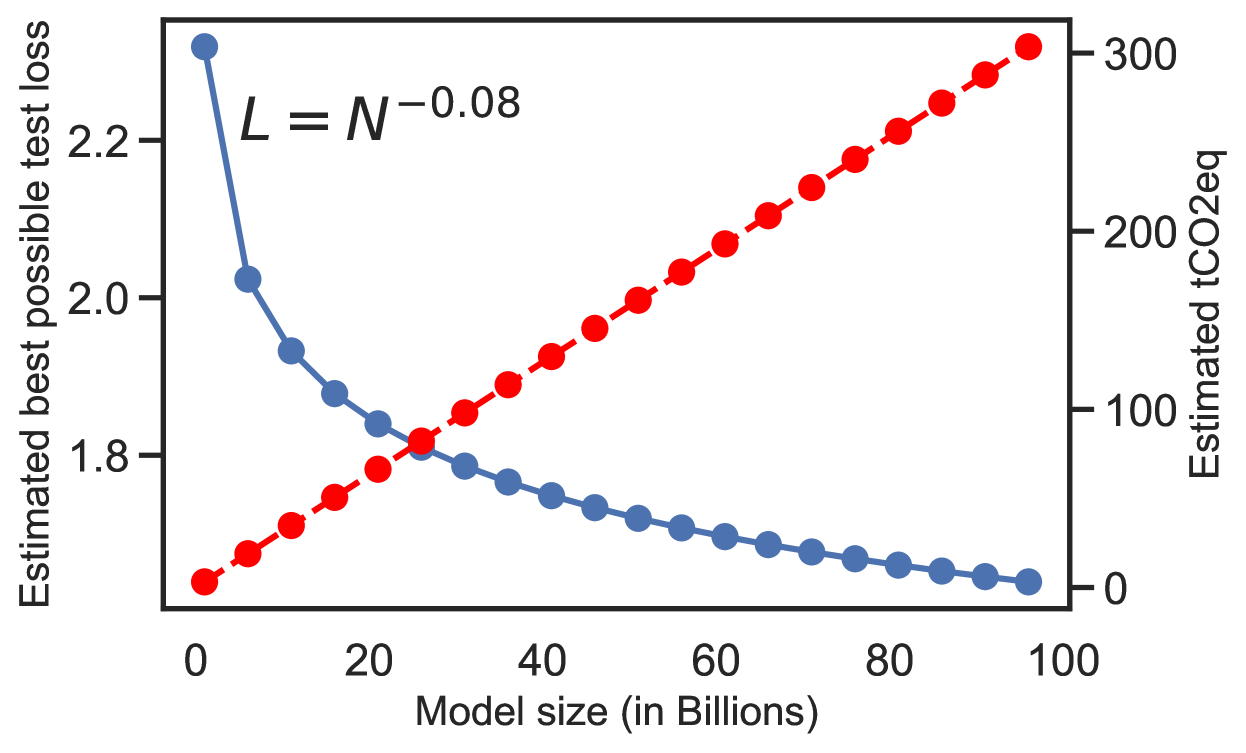
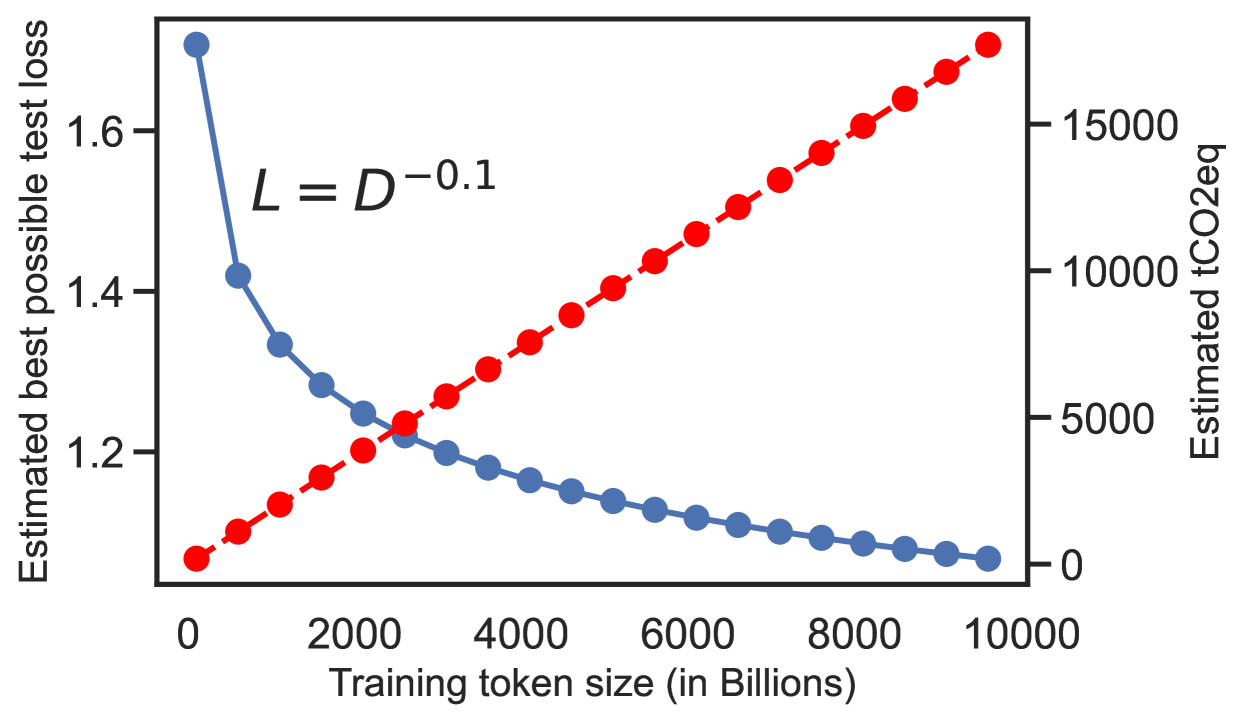
📊 实验亮点
由于论文摘要中没有提供具体的实验结果,因此无法总结实验亮点。未来的研究可能会展示小型化后的LLM在各种任务上的性能表现,并与现有的大型模型进行对比,以证明小型化方法的有效性。同时,研究还可以评估小型化后的LLM在计算资源消耗、环境影响和部署难度等方面的改善情况。
🎯 应用场景
该研究成果可广泛应用于资源受限的场景,如移动设备、嵌入式系统和边缘计算等。小型化后的LLM可以更容易地部署在这些设备上,从而实现智能助手、机器翻译、文本摘要等功能。此外,该研究还有助于降低LLM的训练和部署成本,使其更易于被学术界和工业界所采用,加速人工智能技术的普及。
📄 摘要(原文)
We challenge the dominant focus on neural scaling laws and advocate for a paradigm shift toward downscaling in the development of large language models (LLMs). While scaling laws have provided critical insights into performance improvements through increasing model and dataset size, we emphasize the significant limitations of this approach, particularly in terms of computational inefficiency, environmental impact, and deployment constraints. To address these challenges, we propose a holistic framework for downscaling LLMs that seeks to maintain performance while drastically reducing resource demands. This paper outlines practical strategies for transitioning away from traditional scaling paradigms, advocating for a more sustainable, efficient, and accessible approach to LLM development.