Synthesize-on-Graph: Knowledgeable Synthetic Data Generation for Continue Pre-training of Large Language Models
作者: Shengjie Ma, Xuhui Jiang, Chengjin Xu, Cehao Yang, Liyu Zhang, Jian Guo
分类: cs.CL, cs.AI
发布日期: 2025-05-02 (更新: 2025-09-14)
💡 一句话要点
提出Synthetic-on-Graph框架,利用知识图谱生成合成数据,提升LLM在数据稀缺场景下的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据生成 知识图谱 大型语言模型 持续预训练 图游走 思维链 对比学习
📋 核心要点
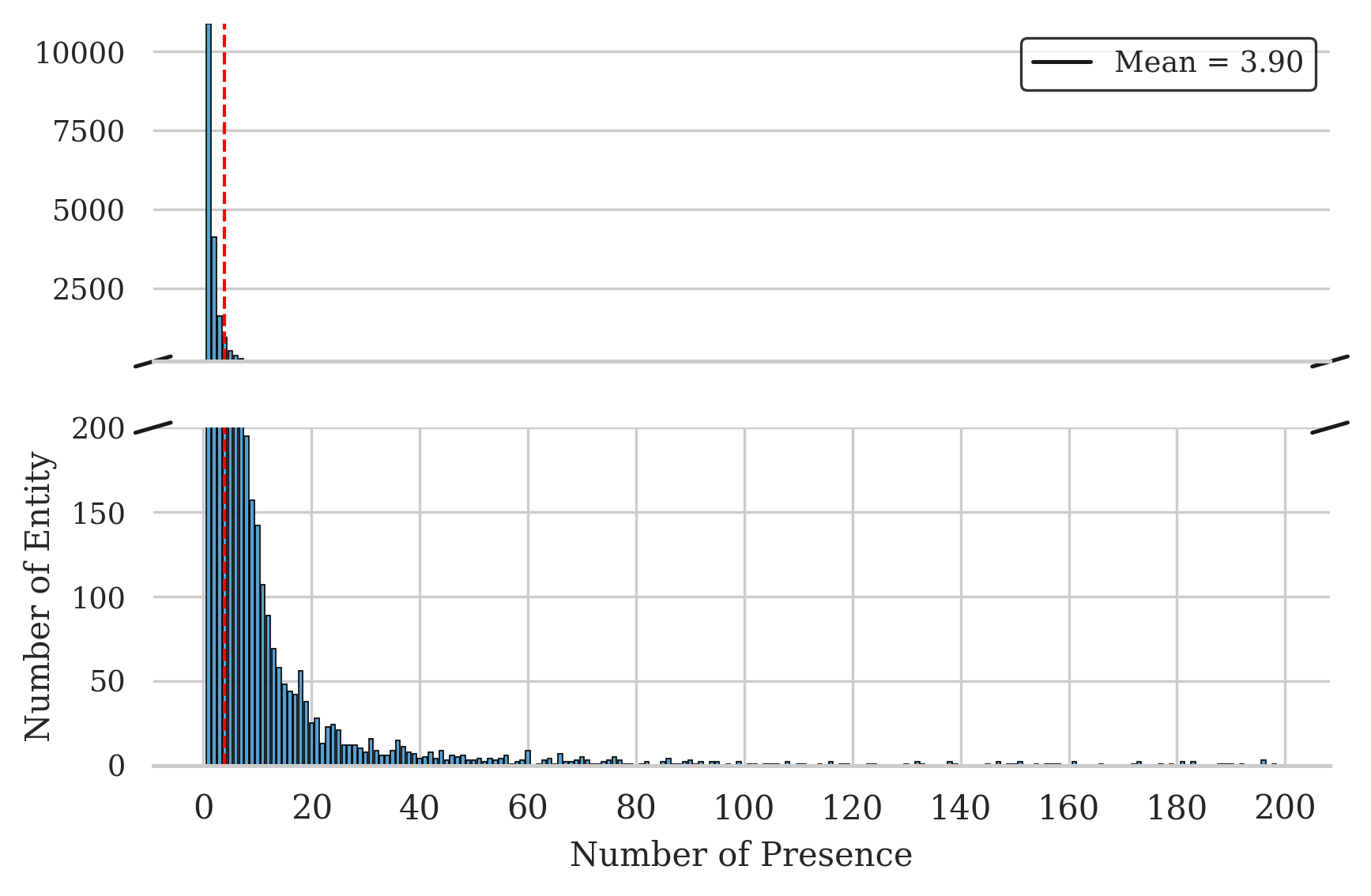
- 现有合成数据方法忽略文档间知识关联,导致内容多样性和深度不足,限制了LLM在特定领域和数据稀缺场景下的性能。
- Synthetic-on-Graph (SoG)框架通过构建知识图谱,利用图游走策略进行知识关联采样,从而增强合成数据的多样性和连贯性。
- 实验表明,SoG在多跳问答和领域特定问答任务上超越了SOTA方法,并在长文本阅读理解上表现出竞争力,验证了其泛化能力。
📝 摘要(中文)
大型语言模型(LLM)取得了显著的成功,但仍然存在数据效率低下的问题,尤其是在从数据有限的专业语料库中学习时。现有的合成数据生成方法侧重于文档内部的内容,忽略了文档间的知识关联,限制了内容的多样性和深度。我们提出了Synthetic-on-Graph (SoG),一个合成数据生成框架,它结合了跨文档的知识关联,以实现高效的语料库扩展。SoG通过从原始语料库中提取实体和概念来构建上下文图,表示跨文档的关联,并采用图游走策略进行知识相关的采样。这增强了合成数据的多样性和连贯性,使模型能够学习复杂的知识结构并处理罕见知识。为了进一步提高合成数据的质量,我们集成了两种互补策略,即思维链(CoT)和对比澄清(CC),以增强推理能力和区分能力。大量实验表明,SoG在多跳和领域特定问答方面超越了最先进(SOTA)的方法,同时在长文本阅读理解方面取得了具有竞争力的性能。这些结果突出了SoG卓越的泛化能力。我们的工作推进了合成数据生成的范式,并为LLM中的高效知识获取提供了实用的解决方案,特别是对于训练数据有限的下游任务和领域。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在数据稀缺或特定领域语料库上训练时,由于数据量不足和缺乏知识关联而导致的学习效率低下的问题。现有合成数据生成方法主要关注文档内部的内容,忽略了文档之间的知识关联,从而限制了合成数据的多样性和深度,无法有效提升模型在复杂知识推理和罕见知识处理方面的能力。
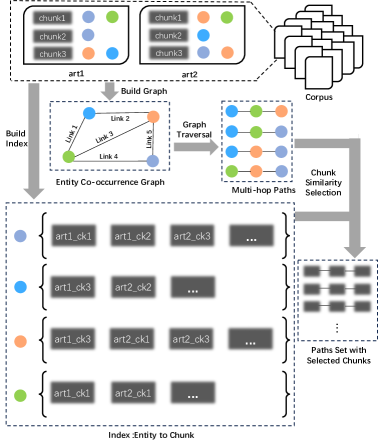
核心思路:论文的核心思路是利用知识图谱来建模文档之间的知识关联,并通过图游走策略生成与原始语料库知识相关的合成数据。通过引入跨文档的知识关联,可以显著提高合成数据的多样性和连贯性,从而使模型能够学习到更丰富的知识结构,并提升其在下游任务中的泛化能力。
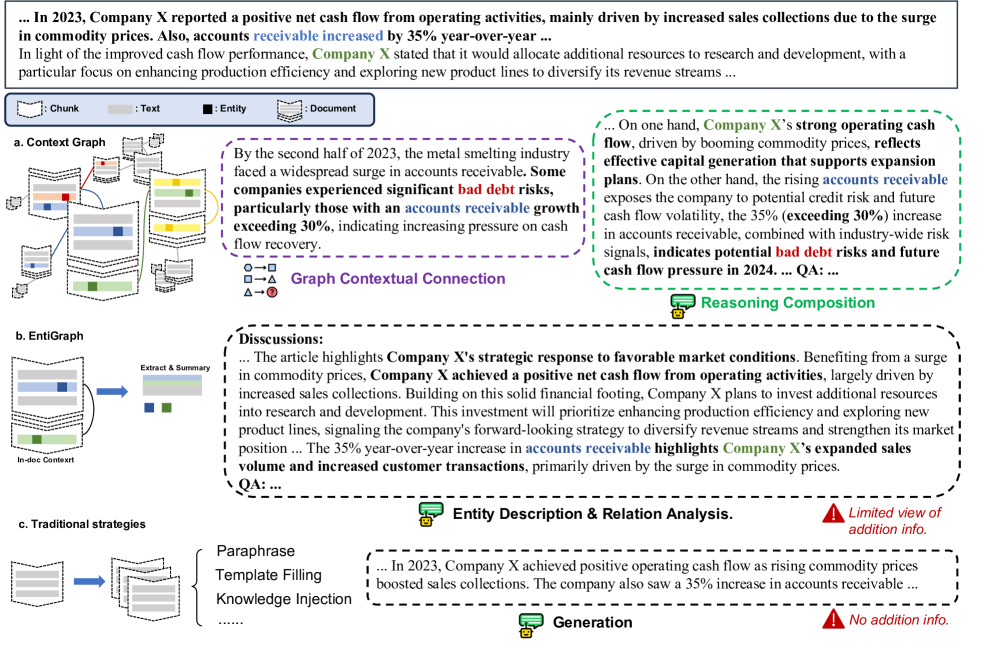
技术框架:SoG框架主要包含以下几个阶段:1) 上下文图构建:从原始语料库中提取实体和概念,并构建上下文图,其中节点表示实体和概念,边表示它们之间的关联关系。2) 知识关联采样:利用图游走策略在上下文图上进行采样,选择与目标知识相关的实体和概念。3) 合成数据生成:基于采样的实体和概念,使用LLM生成合成数据。4) 数据质量增强:集成Chain-of-Thought (CoT)和Contrastive Clarifying (CC)策略,进一步提高合成数据的推理能力和区分能力。
关键创新:SoG的关键创新在于引入了跨文档的知识关联,并将其融入到合成数据生成过程中。与现有方法相比,SoG能够生成更具多样性和连贯性的合成数据,从而使模型能够学习到更丰富的知识结构。此外,CoT和CC策略的集成进一步提高了合成数据的质量,增强了模型的推理能力和区分能力。
关键设计:在上下文图构建中,需要选择合适的实体和概念提取方法,以及定义实体和概念之间的关联关系。图游走策略的选择也会影响合成数据的质量和多样性。CoT策略通过引导LLM进行逐步推理来提高合成数据的推理能力。CC策略通过生成对比样本来增强模型的区分能力。具体的参数设置,例如图游走的步长、CoT和CC策略的参数等,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SoG在多跳问答和领域特定问答任务上显著超越了SOTA方法,例如在某些数据集上性能提升超过10%。同时,SoG在长文本阅读理解任务上也取得了具有竞争力的性能。这些结果充分验证了SoG的有效性和泛化能力。
🎯 应用场景
该研究成果可应用于各种需要利用LLM进行知识密集型任务的领域,例如:智能客服、金融分析、医疗诊断等。特别是在数据稀缺或领域知识专业性强的场景下,SoG能够有效提升LLM的性能,降低对大量标注数据的依赖,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable success but remain data-inefficient, especially when learning from small, specialized corpora with limited and proprietary data. Existing synthetic data generation methods for continue pre-training focus on intra-document content and overlook cross-document knowledge associations, limiting content diversity and depth. We propose Synthetic-on-Graph (SoG), a synthetic data generation framework that incorporates cross-document knowledge associations for efficient corpus expansion. SoG constructs a context graph by extracting entities and concepts from the original corpus, representing cross-document associations, and employing a graph walk strategy for knowledge-associated sampling. This enhances synthetic data diversity and coherence, enabling models to learn complex knowledge structures and handle rare knowledge. To further improve the quality of synthetic data, we integrate two complementary strategies, Chain-of-Thought (CoT) and Contrastive Clarifying (CC), to enhance both reasoning capability and discriminative power. Extensive experiments demonstrate that SoG surpasses state-of-the-art (SOTA) methods on multi-hop and domain-specific question answering, while achieving competitive performance on long-context reading comprehension. These results highlight the superior generalization ability of SoG. Our work advances the paradigm of synthetic data generation and offers practical solutions for efficient knowledge acquisition in LLMs, particularly for downstream tasks and domains with limited training data.