MoxE: Mixture of xLSTM Experts with Entropy-Aware Routing for Efficient Language Modeling
作者: Abdoul Majid O. Thiombiano, Brahim Hnich, Ali Ben Mrad, Mohamed Wiem Mkaouer
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-01
💡 一句话要点
MoxE:结合xLSTM专家混合模型与熵感知路由,提升语言建模效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言建模 专家混合模型 xLSTM 熵感知路由 稀疏计算 可扩展架构 自然语言处理 深度学习
📋 核心要点
- 现有大型语言模型面临可扩展性和计算效率的挑战,限制了其在资源受限环境中的应用。
- MoxE通过结合xLSTM和MoE,利用xLSTM的记忆结构和MoE的稀疏性,降低计算开销并提升效率。
- 实验结果表明,MoxE在效率和有效性方面均优于现有方法,为可扩展LLM架构提供了新的思路。
📝 摘要(中文)
本文提出了一种名为MoxE的新型架构,它将扩展长短期记忆网络(xLSTM)与专家混合模型(MoE)框架结合,旨在解决大型语言模型(LLM)中的可扩展性和效率挑战。该方法有效利用了xLSTM的创新记忆结构,并通过MoE引入稀疏性,从而显著降低计算开销。该方法的核心是一种新颖的基于熵的路由机制,旨在将token动态路由到专门的专家,从而确保高效和平衡的资源利用。这种熵感知能力使架构能够有效地管理稀有和常见token,其中mLSTM块更适合处理稀有token。为了进一步提高泛化能力,我们引入了一套辅助损失,包括基于熵的损失和组平衡损失,从而确保了鲁棒的性能和高效的训练。理论分析和实证评估严格证明,与现有方法相比,MoxE实现了显著的效率提升和增强的有效性,标志着可扩展LLM架构的显著进步。
🔬 方法详解
问题定义:大型语言模型(LLM)在扩展到更大规模时,面临着巨大的计算和内存需求。传统的稠密模型计算成本高昂,难以部署在资源有限的场景中。现有MoE模型在token路由方面可能存在不平衡问题,导致部分专家过载,而其他专家利用不足。
核心思路:MoxE的核心思路是将xLSTM的记忆能力与MoE的稀疏计算相结合,利用xLSTM处理序列数据的优势,并通过MoE将计算分配给不同的专家,从而降低整体计算成本。通过引入熵感知路由机制,动态地将token分配给最合适的专家,平衡专家之间的负载。
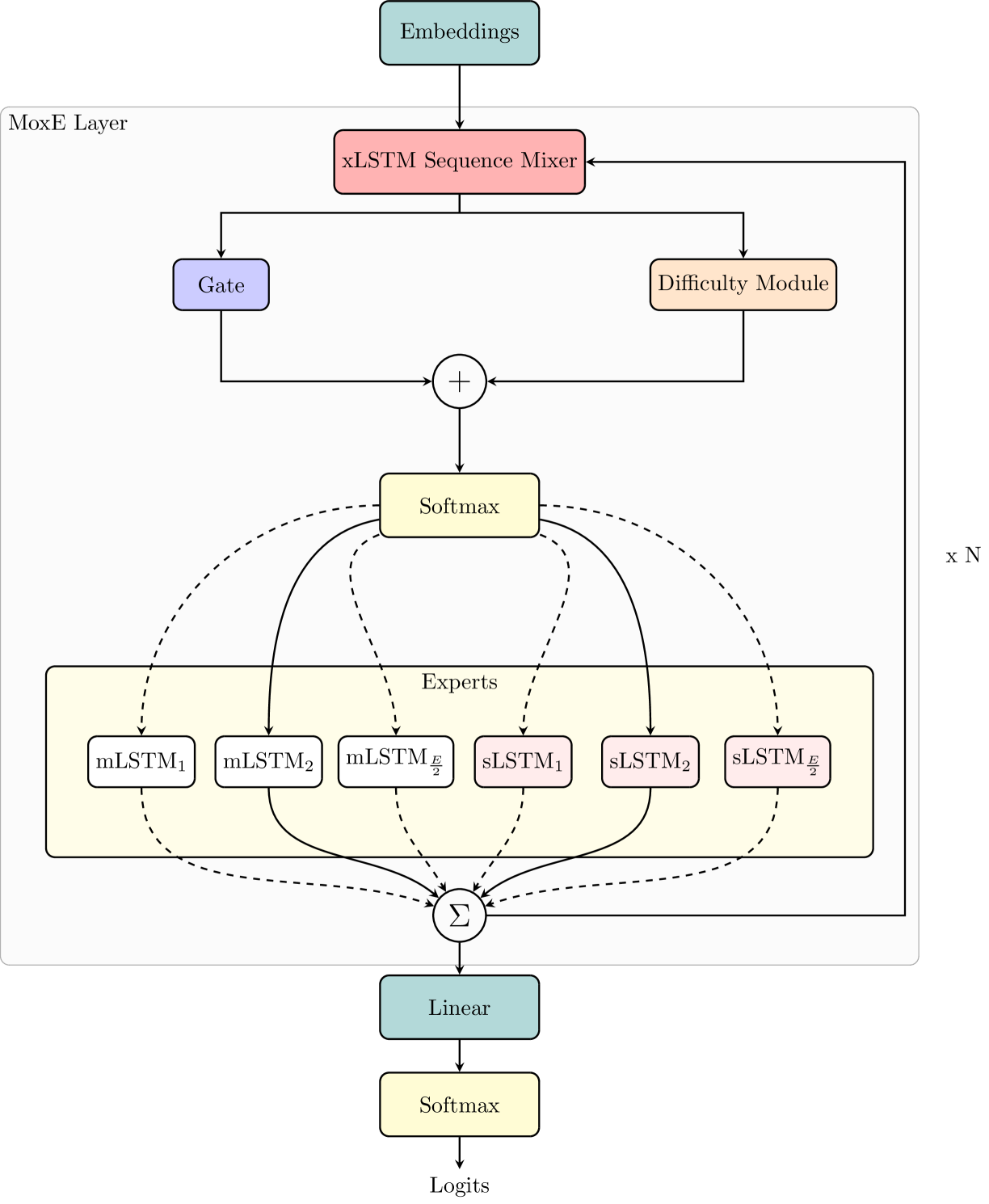
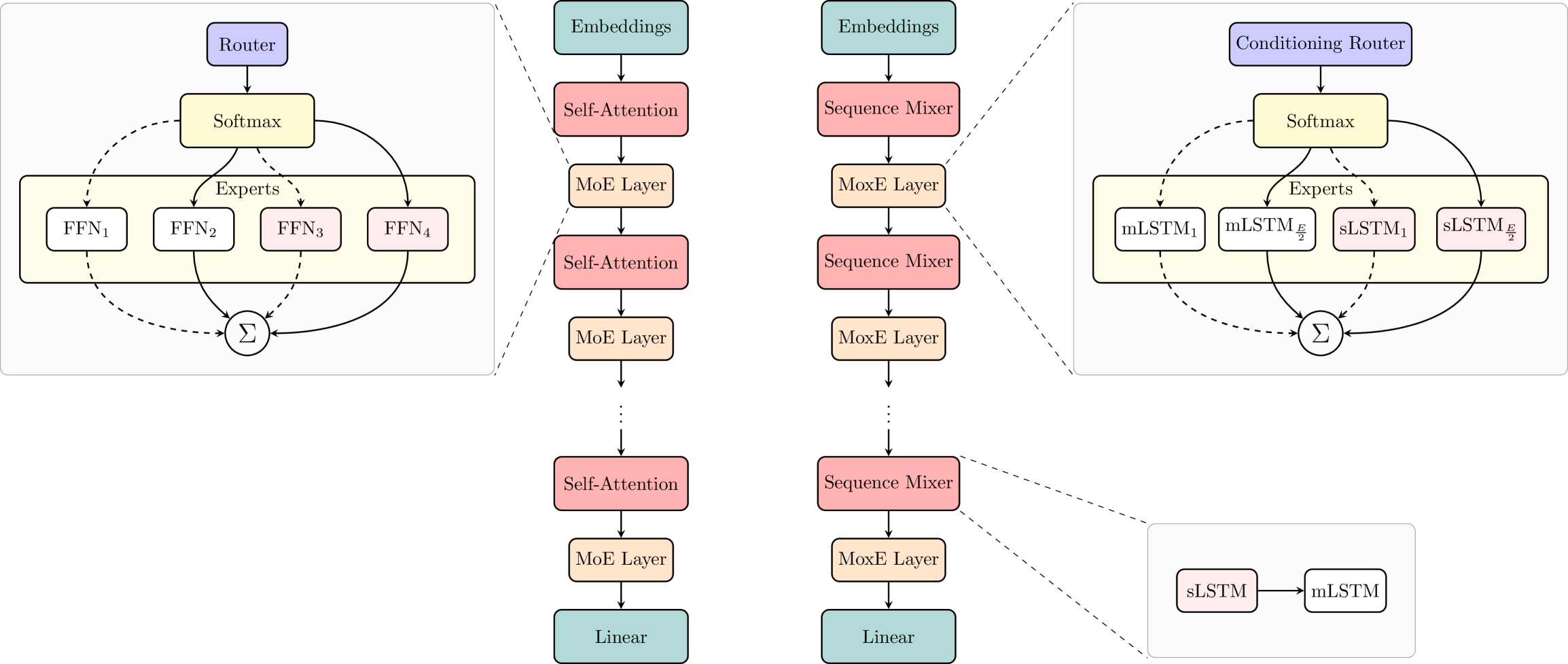
技术框架:MoxE架构主要包含以下几个模块:1) xLSTM层:使用xLSTM作为基础模型,处理输入序列。2) 专家混合(MoE)层:包含多个专家(例如,前馈网络或xLSTM块),每个专家负责处理特定类型的token。3) 路由网络:根据输入token的特征,决定将token路由到哪个专家。MoxE的关键在于其熵感知路由机制,该机制根据token的熵值动态调整路由策略。
关键创新:MoxE的关键创新在于其熵感知路由机制。传统的MoE路由机制通常基于简单的相似度或概率分布,而MoxE则考虑了token的熵值。高熵token(例如,罕见词或信息量大的词)被路由到更专业的专家(例如,mLSTM块),而低熵token则被路由到更通用的专家。这种动态路由策略能够更好地利用专家资源,提高模型的整体性能。
关键设计:MoxE的关键设计包括:1) 熵计算:使用交叉熵或类似方法计算token的熵值。2) 路由策略:根据熵值设定阈值,将token路由到不同的专家。3) 辅助损失:引入熵平衡损失和组平衡损失,以确保专家之间的负载平衡,并防止出现某些专家过载而其他专家利用不足的情况。这些损失函数可以与主损失函数联合优化,从而提高模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
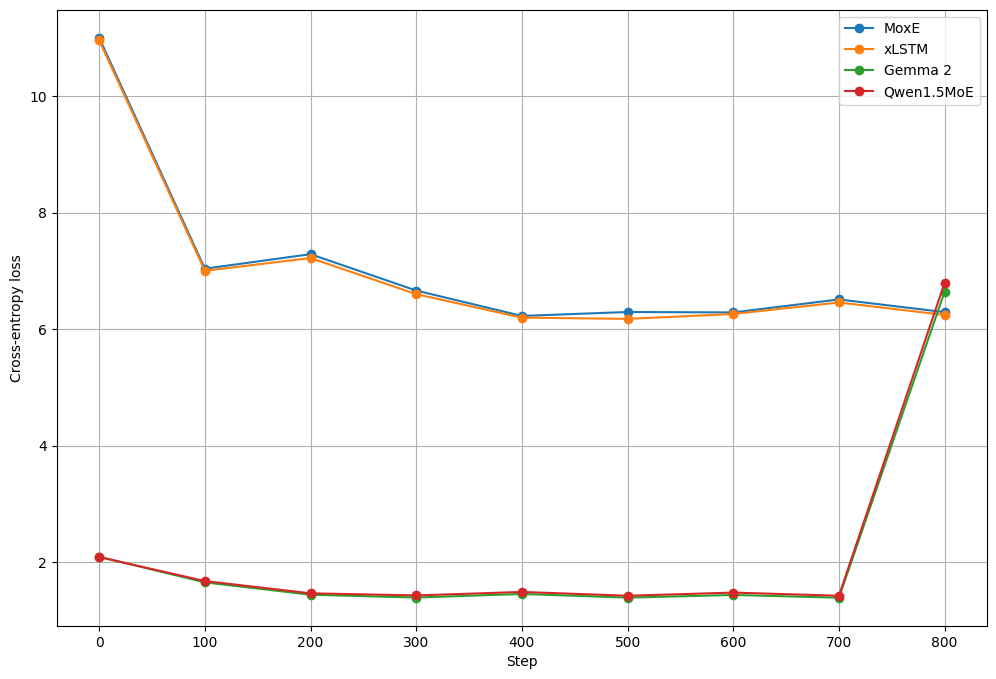
论文通过实验验证了MoxE的有效性。实验结果表明,与传统的稠密模型和MoE模型相比,MoxE在保持甚至提高性能的同时,显著降低了计算成本。具体的性能数据和提升幅度在论文中进行了详细的展示,证明了MoxE在可扩展LLM架构方面的优势。
🎯 应用场景
MoxE架构具有广泛的应用前景,尤其是在资源受限的场景中。例如,它可以用于移动设备上的自然语言处理、边缘计算环境中的智能助手、以及低功耗服务器上的大规模语言模型部署。通过降低计算成本和提高效率,MoxE可以使LLM在更多场景中得到应用。
📄 摘要(原文)
This paper introduces MoxE, a novel architecture that synergistically combines the Extended Long Short-Term Memory (xLSTM) with the Mixture of Experts (MoE) framework to address critical scalability and efficiency challenges in large language models (LLMs). The proposed method effectively leverages xLSTM's innovative memory structures while strategically introducing sparsity through MoE to substantially reduce computational overhead. At the heart of our approach is a novel entropy-based routing mechanism, designed to dynamically route tokens to specialized experts, thereby ensuring efficient and balanced resource utilization. This entropy awareness enables the architecture to effectively manage both rare and common tokens, with mLSTM blocks being favored to handle rare tokens. To further enhance generalization, we introduce a suite of auxiliary losses, including entropy-based and group-wise balancing losses, ensuring robust performance and efficient training. Theoretical analysis and empirical evaluations rigorously demonstrate that MoxE achieves significant efficiency gains and enhanced effectiveness compared to existing approaches, marking a notable advancement in scalable LLM architectures.