On the generalization of language models from in-context learning and finetuning: a controlled study
作者: Andrew K. Lampinen, Arslan Chaudhry, Stephanie C. Y. Chan, Cody Wild, Diane Wan, Alex Ku, Jörg Bornschein, Razvan Pascanu, Murray Shanahan, James L. McClelland
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-01 (更新: 2025-11-10)
备注: FoRLM workshop, NeurIPS 2025
💡 一句话要点
研究表明上下文学习比微调在泛化方面更灵活,并提出加入推理轨迹以提升微调泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 微调 泛化能力 推理轨迹 语言模型
📋 核心要点
- 现有大型语言模型在微调后,对事实信息的泛化能力不足,例如关系反转和逻辑推导。
- 论文核心思想是对比上下文学习和微调的泛化能力差异,并提出通过添加上下文推理轨迹来提升微调的泛化能力。
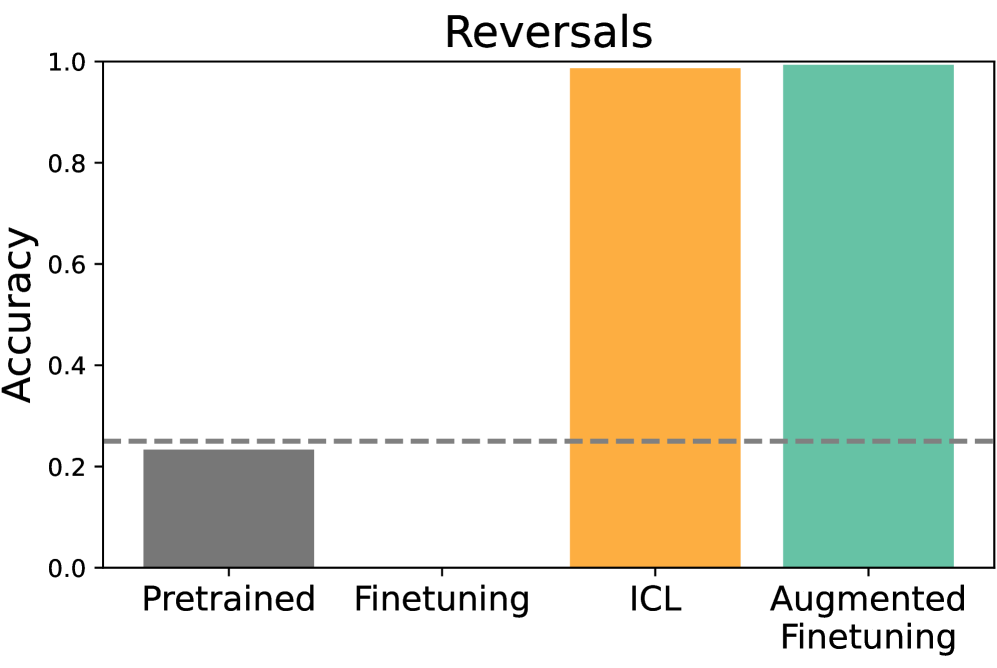
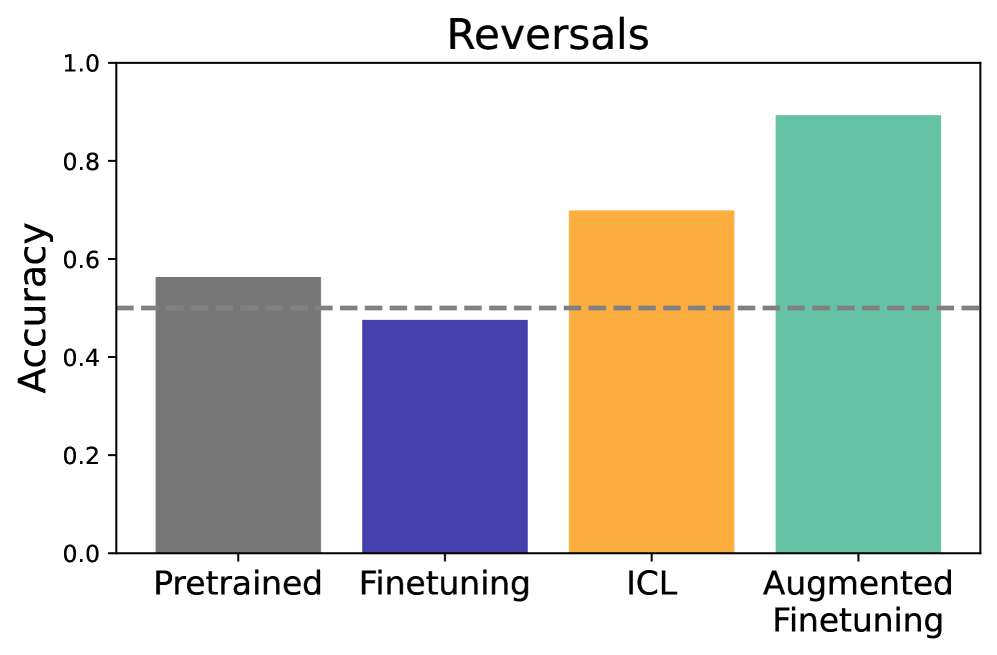
- 实验结果表明,在数据匹配的情况下,上下文学习在泛化方面优于微调,并且提出的方法能够有效提升微调的泛化性能。
📝 摘要(中文)
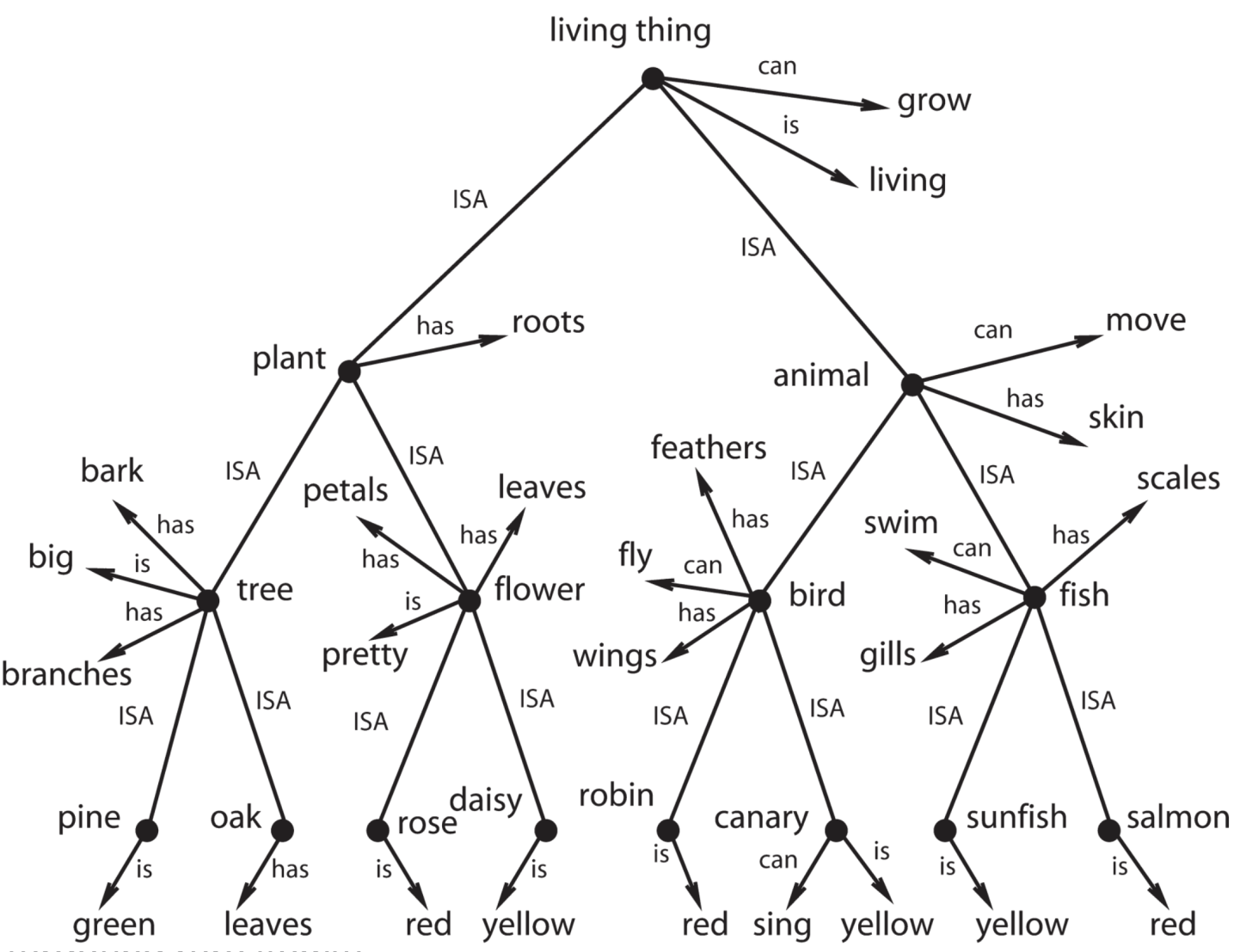
大型语言模型展现出令人兴奋的能力,但其微调后的泛化能力有时会出人意料地狭窄。例如,它们可能无法泛化到训练关系的反转,或者无法基于训练信息进行简单的逻辑推导。这种无法泛化事实信息的缺陷会严重阻碍模型的推理能力。另一方面,语言模型的上下文学习(ICL)表现出不同的归纳偏置和演绎推理能力。本文探讨了基于上下文学习和基于微调学习之间的泛化和演绎推理差异。为此,我们构建了几个新的数据集,以评估和提高模型从新数据中进行泛化的能力。这些数据集旨在通过将数据集中的知识与预训练中的知识隔离,来创建干净的泛化测试。我们将预训练的大型模型暴露于这些数据集中的受控信息子集——通过ICL或微调——并评估它们在需要各种类型泛化的测试集上的性能。总体而言,我们发现在数据匹配的设置中,ICL可以比微调更灵活地泛化几种类型的推论(尽管我们也发现了一些先前发现的限定,例如微调可以泛化到嵌入在更大的知识结构中的反转的情况)。我们基于这些发现提出了一种方法,以实现从微调中改进的泛化:将上下文推理轨迹添加到微调数据中。我们表明,这种方法可以改善我们数据集和其他基准的各种分割的泛化。我们的结果对理解语言模型中不同学习模式所提供的泛化以及实际提高其性能具有重要意义。
🔬 方法详解
问题定义:大型语言模型在微调后,难以泛化到训练数据中未明确包含的新情况,例如关系反转或简单的逻辑推理。现有的微调方法无法有效利用预训练知识,并且容易过拟合训练数据,导致泛化能力下降。
核心思路:论文的核心思路是对比上下文学习(ICL)和微调(Fine-tuning)两种学习方式的泛化能力差异,并发现ICL在某些情况下具有更强的泛化能力。基于此,论文提出将ICL的推理过程融入到微调数据中,从而引导模型学习到更通用的推理模式。
技术框架:论文构建了多个新的数据集,用于评估模型在不同泛化场景下的表现。研究流程包括:1) 使用ICL或微调训练模型;2) 在特定类型的泛化测试集上评估模型性能;3) 分析ICL和微调的泛化能力差异;4) 提出将上下文推理轨迹添加到微调数据中的方法;5) 验证该方法在提升泛化能力方面的有效性。
关键创新:论文的关键创新在于发现了ICL在某些泛化场景下优于微调,并提出了将ICL的推理过程融入到微调数据中以提升泛化能力的方法。这种方法有效地结合了ICL和微调的优点,从而提高了模型的泛化性能。
关键设计:论文的关键设计包括:1) 精心设计的数据集,用于评估模型在不同泛化场景下的表现;2) 将ICL的推理过程表示为推理轨迹,并将其添加到微调数据中;3) 使用标准的语言模型训练方法进行微调,并评估模型在泛化测试集上的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在数据匹配的设置中,ICL在多种类型的推理泛化方面优于微调。更重要的是,将上下文推理轨迹添加到微调数据中,能够显著提升模型在各种数据集分割上的泛化能力,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于提升语言模型在知识密集型任务中的推理能力,例如问答系统、知识图谱推理、常识推理等。通过提高模型的泛化能力,可以使其更好地适应新的场景和数据,从而提高实际应用效果。此外,该研究也为未来研究语言模型的学习机制和泛化能力提供了新的思路。
📄 摘要(原文)
Large language models exhibit exciting capabilities, yet can show surprisingly narrow generalization from finetuning. E.g. they can fail to generalize to simple reversals of relations they are trained on, or fail to make simple logical deductions based on trained information. These failures to generalize factual information from fine-tuning can significantly hinder the reasoning capabilities of these models. On the other hand, language models' in-context learning (ICL) shows different inductive biases and deductive reasoning capabilities. Here, we explore these differences in generalization and deductive reasoning between in-context- and fine-tuning-based learning. To do so, we constructed several novel datasets to evaluate and improve models' abilities to make generalizations over factual information from novel data. These datasets are designed to create clean tests of generalization, by isolating the knowledge in the dataset from that in pretraining. We expose pretrained large models to controlled subsets of the information in these datasets -- either through ICL or fine-tuning -- and evaluate their performance on test sets that require various types of generalization. We find overall that in data-matched settings, ICL can generalize several types of inferences more flexibly than fine-tuning (though we also find some qualifications of prior findings, such as cases when fine-tuning can generalize to reversals embedded in a larger structure of knowledge). We build on these findings to propose a method to enable improved generalization from fine-tuning: adding in-context reasoning traces to finetuning data. We show that this method improves generalization across various splits of our datasets and other benchmarks. Our results have implications for understanding the generalization afforded by different modes of learning in language models, and practically improving their performance.