FineScope : Precision Pruning for Domain-Specialized Large Language Models Using SAE-Guided Self-Data Cultivation
作者: Chaitali Bhattacharyya, Hyunsei Lee, Junyoung Lee, Shinhyoung Jang, Il hong Suh, Yeseong Kim
分类: cs.CL, cs.AI
发布日期: 2025-05-01 (更新: 2025-10-15)
💡 一句话要点
FineScope:利用SAE引导的自数据生成,实现领域专用大语言模型的精确剪枝
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 领域自适应 稀疏自编码器 自数据蒸馏
📋 核心要点
- 现有领域自适应LLM在特定数据集上精度下降,无法兼顾效率与性能。
- FineScope利用SAE提取领域特征,指导模型剪枝和自数据蒸馏,保留领域知识。
- 实验表明,FineScope优于现有LLM,且SAE生成的数据集能有效提升模型领域精度。
📝 摘要(中文)
训练大型语言模型(LLMs)需要大量的计算资源,因此开发更小、领域特定的LLMs,同时保持效率和强大的任务性能,变得越来越重要。中等规模的模型,如LLaMA,已成为领域特定适应的起点,但它们在专门的数据集上进行测试时,通常会遭受准确性下降的问题。我们介绍FineScope,一个从更大的预训练模型中导出紧凑、领域优化LLMs的框架。FineScope利用稀疏自编码器(SAE)框架,受到其产生可解释特征表示能力的启发,从大型数据集中提取领域特定的子集。我们应用具有领域特定约束的结构化剪枝,确保生成的剪枝模型保留目标领域的基本知识。为了进一步提高性能,这些剪枝模型进行自数据蒸馏,利用SAE策划的数据集来恢复在剪枝过程中丢失的关键领域特定信息。大量的实验和消融研究表明,FineScope实现了极具竞争力的性能,优于几个大规模最先进的LLMs在领域特定任务中。此外,我们的结果表明,FineScope使剪枝模型能够在用SAE策划的数据集进行微调时,重新获得其原始性能的很大一部分。此外,将这些数据集应用于微调预训练LLMs而不进行剪枝,也提高了它们在领域特定方面的准确性,突出了我们方法的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决领域特定的大型语言模型(LLM)的剪枝问题。现有方法在对LLM进行剪枝时,容易丢失领域相关的关键信息,导致模型在特定领域的性能显著下降。因此,如何在保证模型压缩率的同时,尽可能保留领域知识,是本文要解决的核心问题。
核心思路:论文的核心思路是利用稀疏自编码器(SAE)来提取领域相关的特征表示,并以此指导模型的剪枝和自数据蒸馏过程。SAE能够学习到数据中稀疏且具有代表性的特征,这些特征可以用于识别和保留对领域任务至关重要的神经元连接。通过这种方式,可以避免在剪枝过程中过度删除关键信息,从而提高剪枝后模型的性能。
技术框架:FineScope框架主要包含三个阶段:1) SAE特征提取:使用SAE对领域数据进行训练,提取领域相关的特征表示。2) 结构化剪枝:基于SAE提取的特征,对LLM进行结构化剪枝,保留对领域任务重要的神经元连接。3) 自数据蒸馏:利用SAE策划的数据集,对剪枝后的模型进行微调,恢复在剪枝过程中丢失的领域知识。
关键创新:论文的关键创新在于将SAE引入到LLM的剪枝过程中,利用SAE提取的领域特征来指导剪枝和自数据蒸馏。与传统的剪枝方法相比,FineScope能够更有效地保留领域知识,从而提高剪枝后模型的性能。此外,利用SAE策划数据集进行自数据蒸馏也是一个创新点,它可以帮助模型恢复在剪枝过程中丢失的信息。
关键设计:在SAE特征提取阶段,论文采用了稀疏性约束,鼓励SAE学习到稀疏且具有代表性的特征。在结构化剪枝阶段,论文设计了一种基于SAE特征的剪枝策略,优先删除对领域任务不重要的神经元连接。在自数据蒸馏阶段,论文使用SAE生成的数据集对剪枝后的模型进行微调,并采用知识蒸馏损失函数,鼓励剪枝后的模型学习原始模型的输出分布。
🖼️ 关键图片
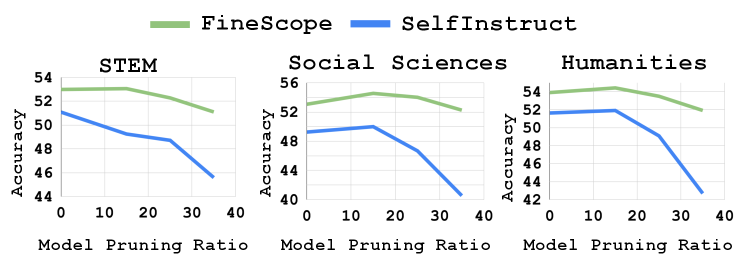
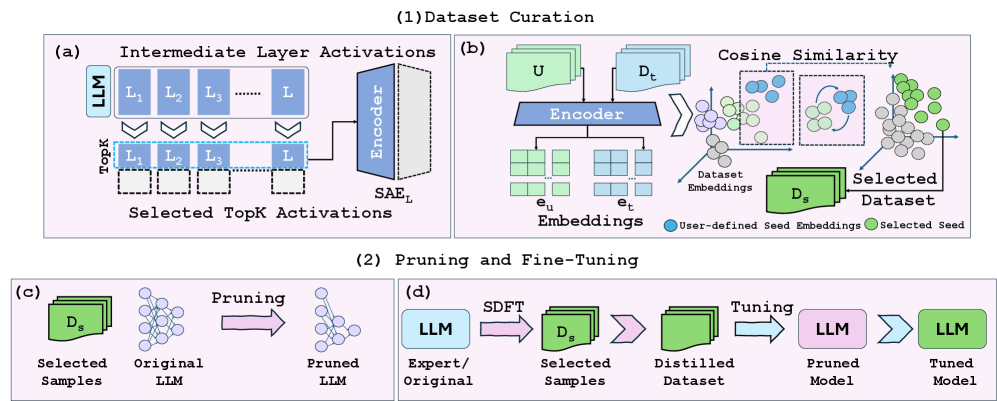
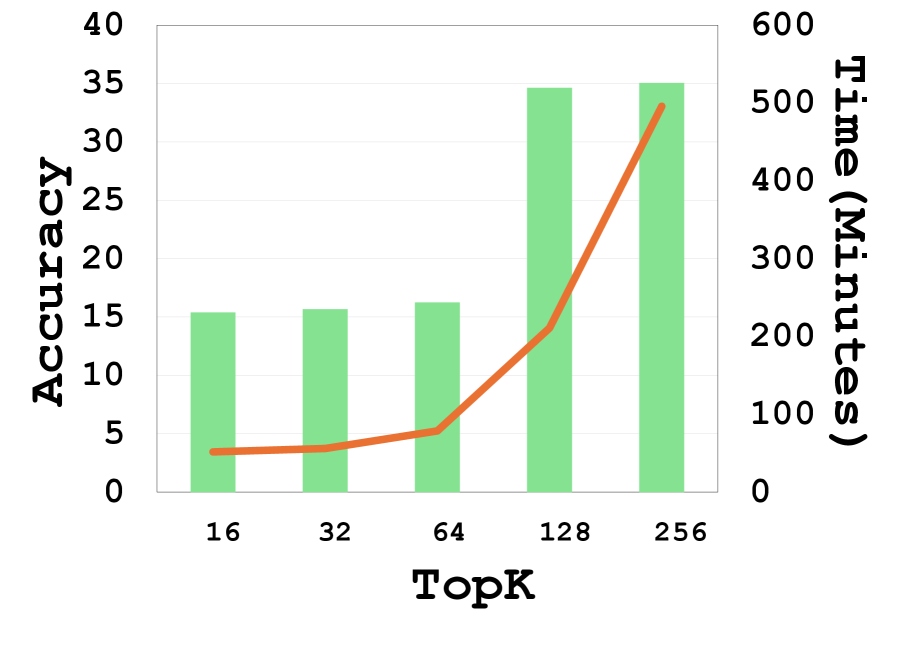
📊 实验亮点
实验结果表明,FineScope在多个领域特定任务上取得了显著的性能提升,超过了多个大型LLM。例如,在医疗领域的MedQA数据集上,FineScope的性能优于GPT-3.5。此外,实验还表明,利用SAE策划的数据集进行微调,可以显著提高剪枝后模型的性能,使其能够恢复到接近原始模型的水平。
🎯 应用场景
FineScope可应用于各种领域特定的大型语言模型压缩场景,例如医疗、金融、法律等。通过该方法,可以在资源受限的环境下部署高性能的领域专用LLM,例如移动设备、嵌入式系统等。此外,FineScope还可以用于知识蒸馏,将大型LLM的知识迁移到小型模型中,从而提高小型模型的性能。
📄 摘要(原文)
Training large language models (LLMs) from scratch requires significant computational resources, driving interest in developing smaller, domain-specific LLMs that maintain both efficiency and strong task performance. Medium-sized models such as LLaMA, llama} have served as starting points for domain-specific adaptation, but they often suffer from accuracy degradation when tested on specialized datasets. We introduce FineScope, a framework for deriving compact, domain-optimized LLMs from larger pretrained models. FineScope leverages the Sparse Autoencoder (SAE) framework, inspired by its ability to produce interpretable feature representations, to extract domain-specific subsets from large datasets. We apply structured pruning with domain-specific constraints, ensuring that the resulting pruned models retain essential knowledge for the target domain. To further enhance performance, these pruned models undergo self-data distillation, leveraging SAE-curated datasets to restore key domain-specific information lost during pruning. Extensive experiments and ablation studies demonstrate that FineScope achieves highly competitive performance, outperforming several large-scale state-of-the-art LLMs in domain-specific tasks. Additionally, our results show that FineScope enables pruned models to regain a substantial portion of their original performance when fine-tuned with SAE-curated datasets. Furthermore, applying these datasets to fine-tune pretrained LLMs without pruning also improves their domain-specific accuracy, highlighting the robustness of our approach.