100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
作者: Chong Zhang, Yue Deng, Xiang Lin, Bin Wang, Dianwen Ng, Hai Ye, Xingxuan Li, Yao Xiao, Zhanfeng Mo, Qi Zhang, Lidong Bing
分类: cs.CL
发布日期: 2025-05-01 (更新: 2025-05-15)
💡 一句话要点
总结DeepSeek-R1复现研究,探索推理语言模型SFT与RLVR的优化方向
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理语言模型 DeepSeek-R1 复现研究 监督微调 强化学习 数据构建 模型训练 开源
📋 核心要点
- 现有推理语言模型缺乏完全开源的实现细节,限制了研究的深入和复现。
- 通过总结DeepSeek-R1的复现研究,探索监督微调(SFT)和强化学习(RLVR)的有效策略。
- 分析数据构建、方法设计和训练流程,总结关键发现,为未来研究提供参考。
📝 摘要(中文)
本文对近期推理语言模型(RLMs)的发展进行了综述,特别是DeepSeek-R1发布后,激发了研究界对语言模型显式推理范式的探索热情。由于DeepSeek未完全开源其模型(包括DeepSeek-R1-Zero、DeepSeek-R1和蒸馏的小模型)的实现细节,涌现了大量复现研究,旨在通过类似的训练流程和完全开源的数据资源来重现DeepSeek-R1的强大性能。这些工作研究了监督微调(SFT)和基于可验证奖励的强化学习(RLVR)的可行策略,侧重于数据准备和方法设计,产生了各种有价值的见解。本文总结了近期的复现研究,以启发未来的研究,主要关注SFT和RLVR这两个主要方向,介绍了当前复现研究的数据构建、方法设计和训练流程的细节。此外,总结了这些研究报告的实现细节和实验结果中的关键发现,以期启发未来的研究。还讨论了增强RLM的其他技术,强调了扩展这些模型应用范围的潜力,并讨论了开发中的挑战。通过本次调查,旨在帮助RLM的研究人员和开发人员及时了解最新进展,并寻求激发新思路,以进一步增强RLM。
🔬 方法详解
问题定义:现有推理语言模型,特别是DeepSeek系列,虽然表现出色,但其实现细节并未完全开源,这导致研究人员难以深入理解其成功的原因,也难以进行有效的复现和改进。现有方法缺乏透明度,阻碍了社区的共同进步。
核心思路:本文的核心思路是通过对已有的DeepSeek-R1复现研究进行系统性的总结和分析,提炼出在数据构建、模型训练和方法设计上的关键要素。通过分析这些复现研究的成功经验和失败教训,为未来的推理语言模型研究提供指导。
技术框架:本文主要关注两个方向:监督微调(SFT)和基于可验证奖励的强化学习(RLVR)。对于每个方向,文章都详细介绍了数据构建的方法,包括数据的来源、清洗、标注和增强等。同时,文章也分析了不同的模型结构、训练策略和优化算法对模型性能的影响。整体框架围绕着复现研究展开,旨在提炼出通用的、可复用的技术方案。
关键创新:本文的创新之处在于对现有复现研究的系统性总结和分析。不同于以往的研究,本文不是提出一种新的模型或算法,而是通过对现有工作的梳理,提炼出关键的技术要素和设计原则。这种方法可以帮助研究人员更快地了解领域内的最新进展,并避免重复造轮子。
关键设计:文章详细分析了数据构建过程中的关键设计,例如如何选择高质量的训练数据、如何进行数据增强以提高模型的泛化能力。在模型训练方面,文章讨论了不同的损失函数、优化算法和正则化方法对模型性能的影响。此外,文章还分析了不同的模型结构和超参数设置对模型性能的影响。
🖼️ 关键图片
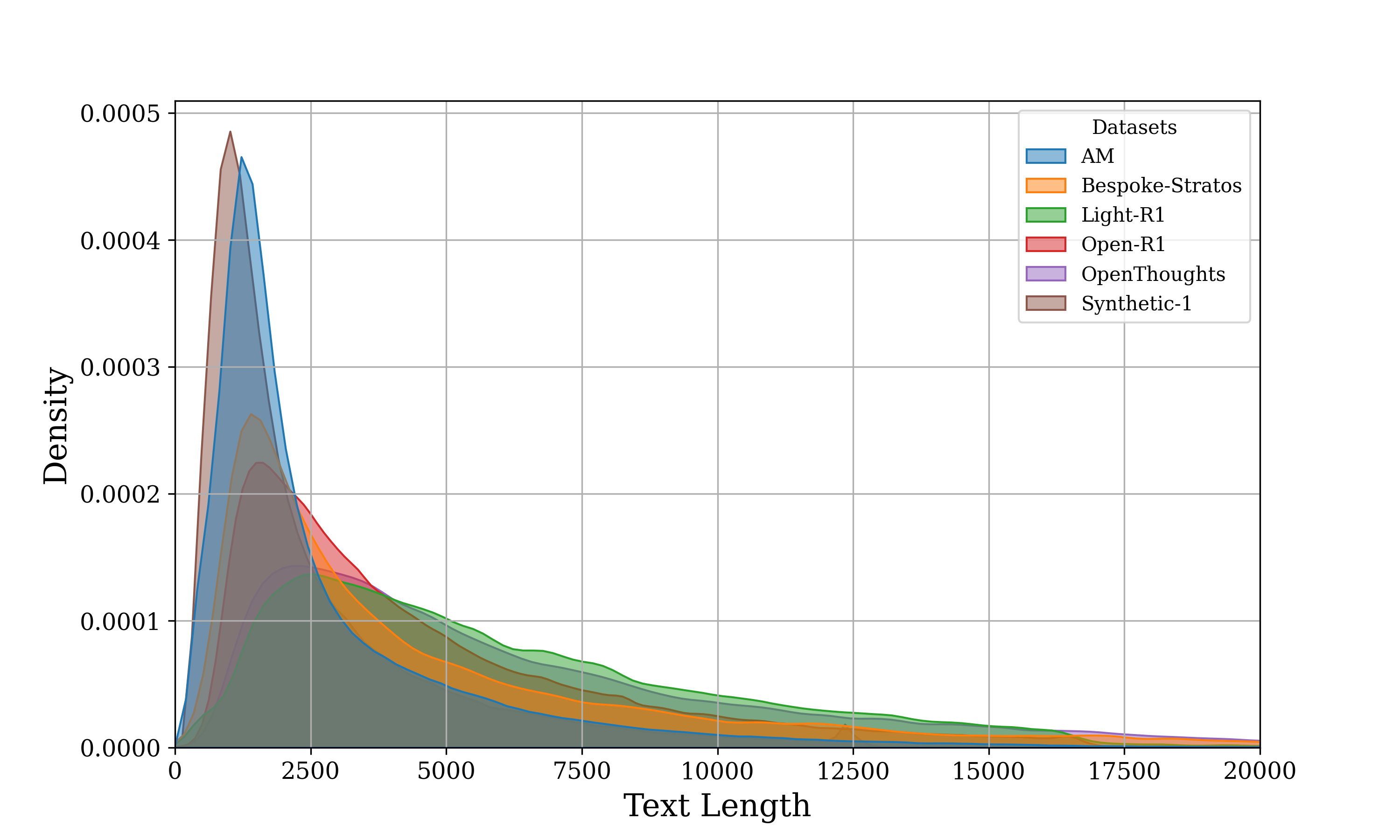
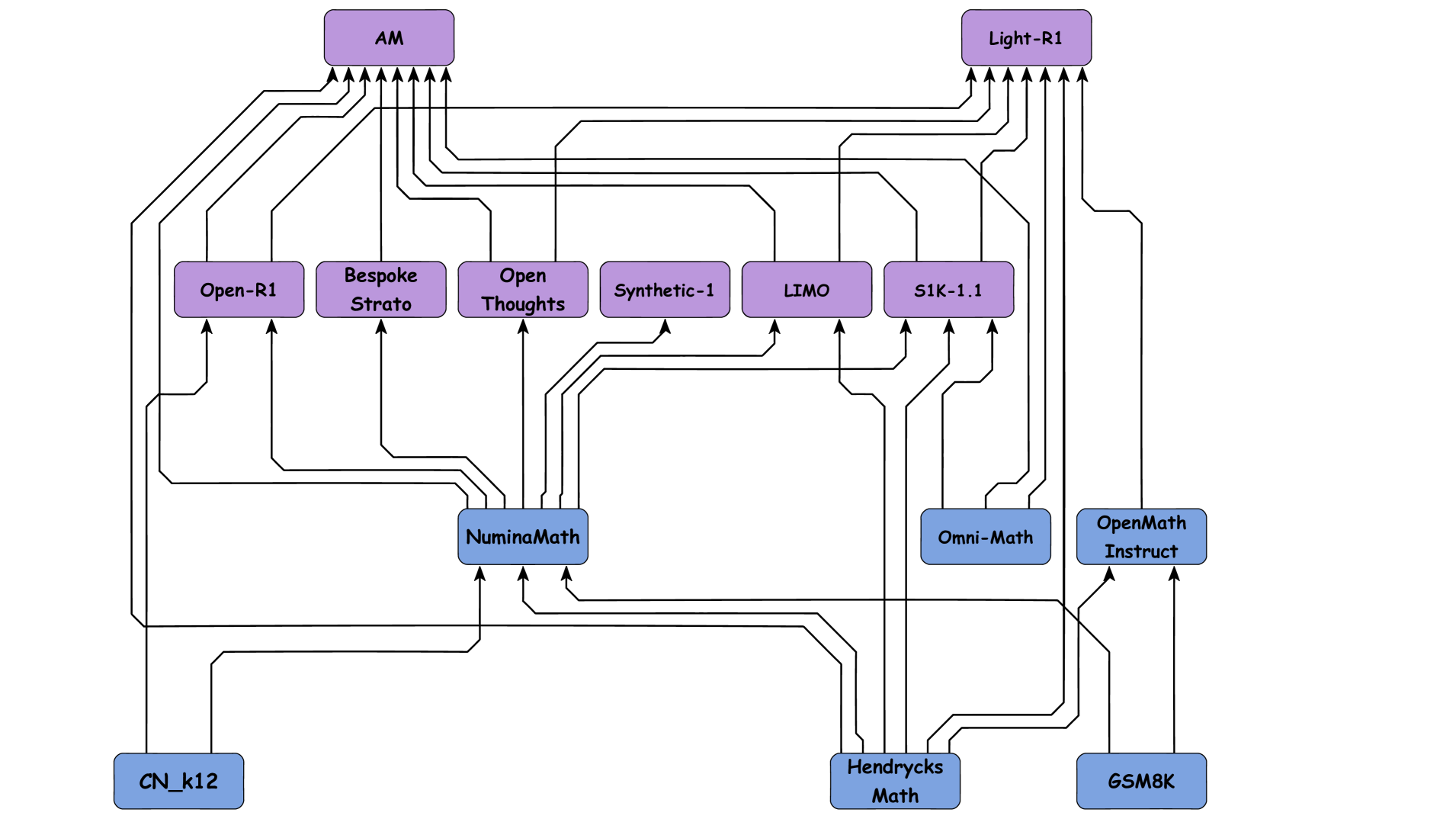
📊 实验亮点
本文总结了多个DeepSeek-R1的复现研究,这些研究在开源数据和资源的基础上,通过监督微调(SFT)和基于可验证奖励的强化学习(RLVR)等方法,取得了与DeepSeek-R1相近甚至更优的性能。这些复现研究验证了通过合理的训练流程和数据准备,即使没有完全相同的模型结构和参数,也能达到高性能。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的自然语言处理任务,如问答系统、文本摘要、机器翻译等。通过开源的复现研究,可以促进推理语言模型的发展,降低开发成本,加速技术落地。未来,更强大的推理语言模型将在教育、医疗、金融等领域发挥重要作用。
📄 摘要(原文)
The recent development of reasoning language models (RLMs) represents a novel evolution in large language models. In particular, the recent release of DeepSeek-R1 has generated widespread social impact and sparked enthusiasm in the research community for exploring the explicit reasoning paradigm of language models. However, the implementation details of the released models have not been fully open-sourced by DeepSeek, including DeepSeek-R1-Zero, DeepSeek-R1, and the distilled small models. As a result, many replication studies have emerged aiming to reproduce the strong performance achieved by DeepSeek-R1, reaching comparable performance through similar training procedures and fully open-source data resources. These works have investigated feasible strategies for supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR), focusing on data preparation and method design, yielding various valuable insights. In this report, we provide a summary of recent replication studies to inspire future research. We primarily focus on SFT and RLVR as two main directions, introducing the details for data construction, method design and training procedure of current replication studies. Moreover, we conclude key findings from the implementation details and experimental results reported by these studies, anticipating to inspire future research. We also discuss additional techniques of enhancing RLMs, highlighting the potential of expanding the application scope of these models, and discussing the challenges in development. By this survey, we aim to help researchers and developers of RLMs stay updated with the latest advancements, and seek to inspire new ideas to further enhance RLMs.