CSE-SFP: Enabling Unsupervised Sentence Representation Learning via a Single Forward Pass
作者: Bowen Zhang, Zixin Song, Chunping Li
分类: cs.CL
发布日期: 2025-05-01
备注: Accepted by SIGIR 2025 (Full)
💡 一句话要点
提出CSE-SFP,通过单次前向传播实现生成式PLM的无监督句子表示学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 句子表示学习 无监督学习 对比学习 生成式模型 预训练语言模型 单次前向传播 文本嵌入
📋 核心要点
- 现有无监督句子表示方法在生成式PLM上的应用受限于计算成本和模型规模,缺乏高效的解决方案。
- CSE-SFP利用生成模型的结构特性,通过单次前向传播实现对比学习,降低计算复杂度。
- 实验表明,CSE-SFP在提升嵌入质量的同时,显著降低了训练时间和内存消耗,并提出了新的评估指标。
📝 摘要(中文)
句子表示是信息检索和计算语言学中的一项基础任务,对文本聚类、内容分析、问答系统和网络搜索等实际应用具有深远影响。预训练语言模型(PLM)的最新进展推动了该领域的显著进步,特别是通过以BERT等判别式PLM为中心的无监督嵌入推导方法。然而,由于时间和计算资源的限制,很少有研究尝试将无监督句子表示与生成式PLM相结合,而生成式PLM通常具有更大的参数规模。鉴于学术界和工业界的先进模型主要基于生成式架构,迫切需要一种为仅解码器PLM量身定制的高效无监督文本表示框架。为了解决这个问题,我们提出了一种创新方法CSE-SFP,它利用了生成模型的结构特征。与现有策略相比,CSE-SFP仅需要单次前向传播即可执行有效的无监督对比学习。严格的实验表明,CSE-SFP不仅产生更高质量的嵌入,而且显著减少了训练时间和内存消耗。此外,我们引入了两个比率指标,共同评估对齐性和均匀性,从而为评估编码模型的语义空间属性提供了一种更稳健的方法。
🔬 方法详解
问题定义:论文旨在解决生成式预训练语言模型(PLM)在无监督句子表示学习中效率低下的问题。现有方法通常需要多次前向传播或复杂的训练策略,导致计算成本高昂,难以应用于参数规模庞大的生成式模型。这些模型在学术界和工业界应用广泛,因此高效的无监督表示学习方法至关重要。
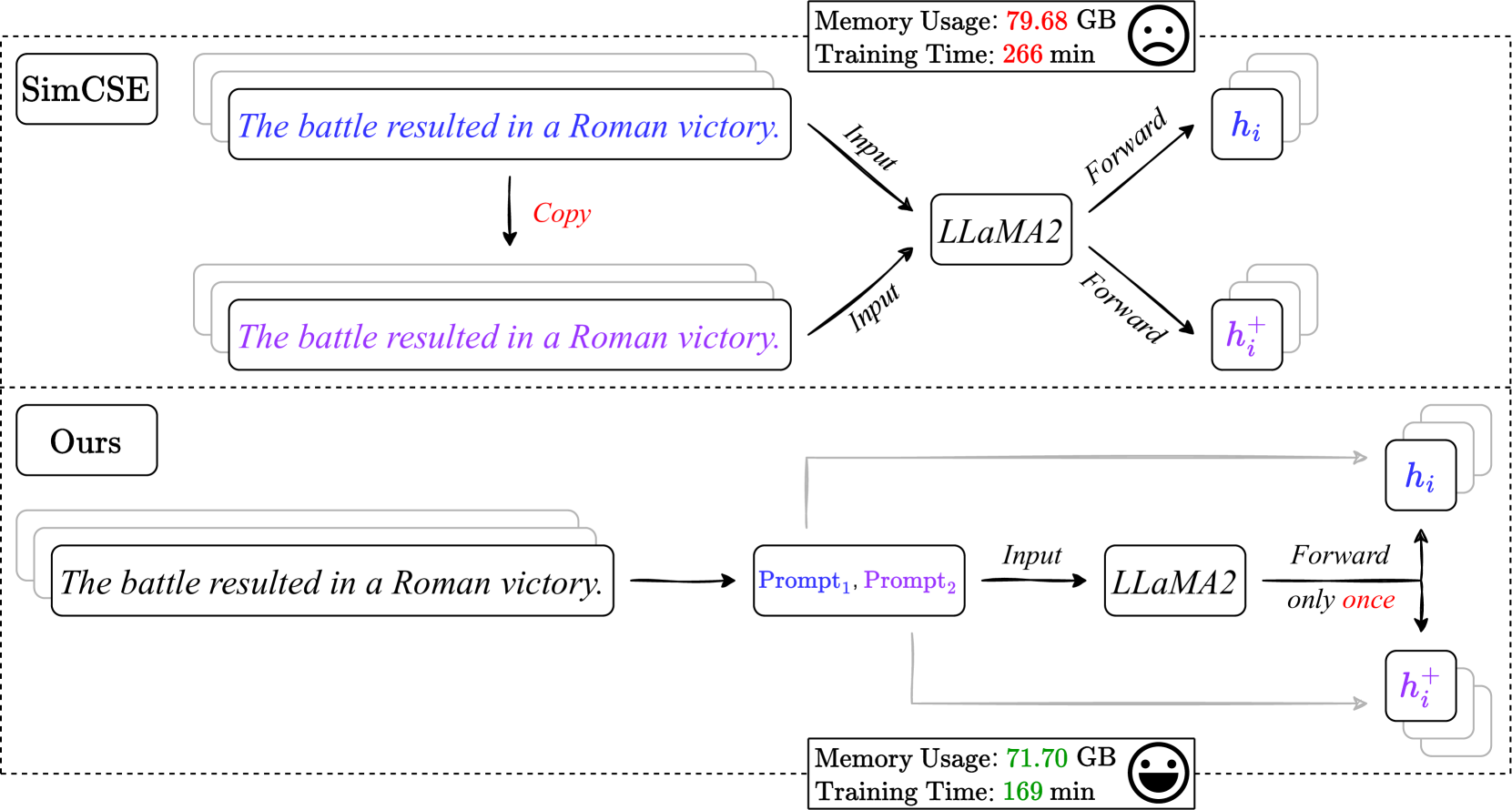
核心思路:CSE-SFP的核心思路是利用生成式模型的自回归特性,通过单次前向传播提取句子表示,并构建对比学习任务。通过精心设计的对比损失,模型能够学习到具有良好对齐性和均匀性的句子嵌入空间。这种方法避免了传统对比学习中多次前向传播的需求,显著降低了计算复杂度。
技术框架:CSE-SFP的技术框架主要包含以下几个阶段:1) 输入句子经过生成式PLM的单次前向传播;2) 从模型输出中提取句子表示,例如使用特定层的输出或对多层输出进行聚合;3) 构建对比学习任务,例如使用InfoNCE损失,将原始句子与其增强版本进行对比;4) 使用优化器更新模型参数,最小化对比损失。
关键创新:CSE-SFP最重要的技术创新点在于其单次前向传播的对比学习框架。与现有方法相比,它避免了多次前向传播,显著降低了计算成本,使得在大型生成式PLM上进行无监督句子表示学习成为可能。此外,论文还提出了新的评估指标,用于更全面地评估句子嵌入的质量。
关键设计:CSE-SFP的关键设计包括:1) 如何从生成式PLM的输出中提取有效的句子表示;2) 如何构建合适的对比学习任务,例如选择合适的增强方法和对比样本;3) 如何设计损失函数,以鼓励句子嵌入具有良好的对齐性和均匀性。论文还可能涉及一些超参数的调整,例如对比学习的温度参数。
🖼️ 关键图片

📊 实验亮点
CSE-SFP在多个句子表示学习基准测试中取得了显著的性能提升,尤其是在计算效率方面表现突出。实验结果表明,CSE-SFP在保证嵌入质量的同时,能够显著减少训练时间和内存消耗,使其成为生成式PLM无监督句子表示学习的有效解决方案。论文还提出了新的评估指标,为句子嵌入的质量评估提供了更全面的视角。
🎯 应用场景
CSE-SFP可广泛应用于各种自然语言处理任务,如文本聚类、语义搜索、文本相似度计算、问答系统等。该方法尤其适用于需要处理大规模文本数据且计算资源有限的场景。未来,CSE-SFP可以进一步扩展到跨语言场景,并与其他无监督学习技术相结合,提升模型性能。
📄 摘要(原文)
As a fundamental task in Information Retrieval and Computational Linguistics, sentence representation has profound implications for a wide range of practical applications such as text clustering, content analysis, question-answering systems, and web search. Recent advances in pre-trained language models (PLMs) have driven remarkable progress in this field, particularly through unsupervised embedding derivation methods centered on discriminative PLMs like BERT. However, due to time and computational constraints, few efforts have attempted to integrate unsupervised sentence representation with generative PLMs, which typically possess much larger parameter sizes. Given that state-of-the-art models in both academia and industry are predominantly based on generative architectures, there is a pressing need for an efficient unsupervised text representation framework tailored to decoder-only PLMs. To address this concern, we propose CSE-SFP, an innovative method that exploits the structural characteristics of generative models. Compared to existing strategies, CSE-SFP requires only a single forward pass to perform effective unsupervised contrastive learning. Rigorous experimentation demonstrates that CSE-SFP not only produces higher-quality embeddings but also significantly reduces both training time and memory consumption. Furthermore, we introduce two ratio metrics that jointly assess alignment and uniformity, thereby providing a more robust means for evaluating the semantic spatial properties of encoding models.