On the Failure of Latent State Persistence in Large Language Models
作者: Jen-tse Huang, Kaiser Sun, Wenxuan Wang, Mark Dredze
分类: cs.CL, cs.AI
发布日期: 2025-04-30 (更新: 2026-01-15)
备注: 8 pages, 6 figures, 9 tables
💡 一句话要点
揭示大语言模型在维持潜在状态持久性方面的不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 潜在状态持久性 推理能力 工作记忆 认知模型
📋 核心要点
- 现有大型语言模型在复杂推理中,维持和操纵内部表征的能力不足,缺乏类似人类工作记忆的持久性。
- 论文通过设计数字猜测、是非问答和数学心灵主义等实验,量化评估了LLM在维持潜在状态持久性(LSP)方面的差距。
- 实验结果表明,LLM在处理需要长期记忆的任务时,存在概念漂移、变量绑定失败等问题,表明其更像反应式求解器。
📝 摘要(中文)
大型语言模型(LLM)在推理方面表现出色,但它们是否能维持持久的潜在状态仍有待研究。维持和操纵未表达的内部表征(类似于人类的工作记忆)是复杂推理的基石。本文通过三个新颖的实验,形式化并量化了“潜在状态持久性”(LSP)差距。首先,我们利用一个数字猜测游戏,表明LLM在独立查询中未能将概率质量分配给一个单一的隐藏选择,违反了一个基本的概率原则。其次,我们使用一个是非游戏来表明,随着问题数量的增加,LLM会遭受“概念漂移”,由于缺乏LSP,导致不可避免的自我矛盾。最后,受到数学心灵主义的启发,我们要求模型跟踪隐藏变量的转换,揭示了当初始状态没有明确出现在上下文中时,变量绑定和状态演化方面的失败。总的来说,这些发现表明LLM的功能更像是反应式的后验求解器,而不是具有LSP的主动规划器。我们的工作提供了一个评估内部表征保真度的框架,并强调了自回归Transformer和类人认知之间的一个根本架构差异。
🔬 方法详解
问题定义:现有的大型语言模型在推理任务中表现出色,但它们是否能够像人类一样维持和操纵内部的、未表达的潜在状态(latent state)仍然是一个未被充分探索的问题。人类的认知能力很大程度上依赖于工作记忆,即能够记住并处理先前的信息,以便进行后续的推理和决策。现有方法缺乏对LLM潜在状态持久性的有效评估和量化。
核心思路:论文的核心思路是通过设计一系列实验来显式地考察LLM在维持和更新潜在状态方面的能力。这些实验模拟了需要长期记忆和状态追踪的认知任务,通过观察LLM在这些任务中的表现来推断其潜在状态的持久性。核心在于将LLM视为一个黑盒,通过输入和输出之间的关系来推断其内部状态的变化。
技术框架:论文设计了三个实验来评估LLM的潜在状态持久性: 1. 数字猜测游戏:评估LLM是否能在多次独立查询中记住一个隐藏的数字。 2. 是非游戏:评估LLM在回答一系列是非问题时是否会产生自我矛盾,从而反映概念漂移。 3. 数学心灵主义:评估LLM是否能跟踪隐藏变量的变换,并在没有明确上下文的情况下进行变量绑定和状态演化。
关键创新:论文的关键创新在于提出了一个评估LLM潜在状态持久性的框架,并设计了三个新颖的实验来量化这种能力。与以往关注LLM在特定任务上的性能不同,该研究侧重于考察LLM的内部表征机制,揭示了其在维持长期记忆和状态追踪方面的局限性。这种评估框架为理解LLM的认知能力提供了新的视角。
关键设计:在数字猜测游戏中,模型需要猜测一个隐藏的数字,并根据反馈调整其猜测。关键在于观察模型在多次猜测中是否能将概率质量集中在正确的数字上。在是非游戏中,模型需要回答一系列相关的是非问题,关键在于检测模型是否会产生自我矛盾。在数学心灵主义游戏中,模型需要跟踪隐藏变量的变换,关键在于评估模型是否能在没有明确上下文的情况下正确地进行变量绑定和状态演化。具体的参数设置和损失函数未知。
🖼️ 关键图片
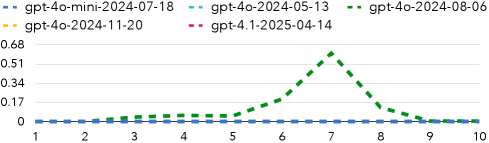
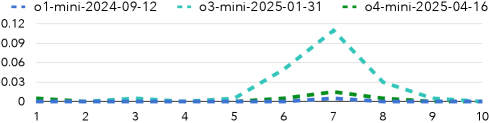
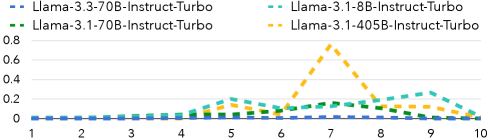
📊 实验亮点
实验结果表明,LLM在数字猜测游戏中未能将概率质量分配给正确的隐藏数字,在是非游戏中出现了概念漂移导致的自我矛盾,在数学心灵主义游戏中无法正确跟踪隐藏变量的变换。这些结果表明,LLM在维持潜在状态持久性方面存在显著不足,其行为更接近于反应式求解器,而非具有长期记忆的主动规划器。具体的性能数据未知。
🎯 应用场景
该研究成果可应用于改进LLM的推理能力,尤其是在需要长期记忆和状态追踪的任务中,例如对话系统、智能助手和游戏AI。通过了解LLM在潜在状态持久性方面的局限性,可以设计更有效的模型架构和训练方法,使其更接近人类的认知能力。未来的研究可以探索如何将外部记忆模块或注意力机制融入LLM,以增强其长期记忆能力。
📄 摘要(原文)
While Large Language Models (LLMs) excel in reasoning, whether they can sustain persistent latent states remains under-explored. The capacity to maintain and manipulate unexpressed, internal representations-analogous to human working memory-is a cornerstone of complex reasoning. In this paper, we formalize and quantify the "Latent State Persistence" (LSP) gap through three novel experiments. First, we utilize a Number Guessing Game, demonstrating that across independent queries, LLMs fail to allocate probability mass to a singular hidden choice, violating a fundamental probabilistic principle. Second, we employ a Yes-No Game to show that as the number of questions increases, LLMs suffer from "concept drift," leading to inevitable self-contradictions due to the lack of LSP. Finally, inspired by Mathematical Mentalism, we task models with tracking transformations on hidden variables, revealing a failure in variable binding and state evolution when the initial state is not explicitly present in the context. Collectively, these findings suggest that LLMs function as reactive post-hoc solvers rather than proactive planners with LSP. Our work provides a framework for evaluating the fidelity of internal representations and highlights a fundamental architectural divergence between autoregressive transformers and human-like cognition.