Fine-Tuning LLMs for Low-Resource Dialect Translation: The Case of Lebanese
作者: Silvana Yakhni, Ali Chehab
分类: cs.CL, cs.AI
发布日期: 2025-04-30
💡 一句话要点
针对低资源黎巴嫩方言翻译,提出基于文化数据微调LLM的方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源翻译 黎巴嫩方言 大型语言模型 微调 对比学习 文化真实性 机器翻译
📋 核心要点
- 现有机器翻译方法在低资源方言上表现不佳,缺乏文化背景理解是主要挑战。
- 论文提出利用包含文化信息的黎巴嫩方言数据集,通过对比学习等方法微调LLM。
- 实验表明,在文化相关数据上微调的模型性能显著提升,优于大数据集训练的模型。
📝 摘要(中文)
本文研究了大型语言模型(LLM)在翻译低资源黎巴嫩方言方面的有效性,重点关注文化相关的真实数据与更大的翻译数据集的影响。我们比较了三种微调方法:基础微调、对比微调和语法提示微调,使用开源Aya23模型。实验表明,在较小但具有文化意识的黎巴嫩数据集(LW)上微调的模型始终优于在较大的非母语数据上训练的模型。通过对比微调与对比提示相结合,获得了最佳结果,这表明将翻译模型暴露于“坏”例子是有益的。此外,为了确保真实的评估,我们引入了LebEval,这是一个源自黎巴嫩本土内容的新基准,并将其与现有的FLoRes基准进行比较。我们的发现挑战了“更多数据更好”的范式,并强调了文化真实性在方言翻译中的关键作用。我们将数据集和代码在Github上公开。
🔬 方法详解
问题定义:论文旨在解决低资源黎巴嫩方言的机器翻译问题。现有方法,特别是依赖大规模通用数据集训练的模型,在处理方言时往往表现不佳,因为它们缺乏对特定文化背景和语言细微差别的理解。简单地增加数据量并不能有效解决这个问题,因为这些数据可能并不包含目标方言的独特特征。
核心思路:论文的核心思路是,对于低资源方言翻译,文化相关的真实数据比单纯的数据量更重要。通过在包含丰富文化信息的黎巴嫩方言数据集上微调大型语言模型,可以使其更好地理解和生成地道的黎巴嫩方言文本。此外,论文还探索了对比学习的方法,通过引入“坏”例子来提高模型的鲁棒性和区分能力。
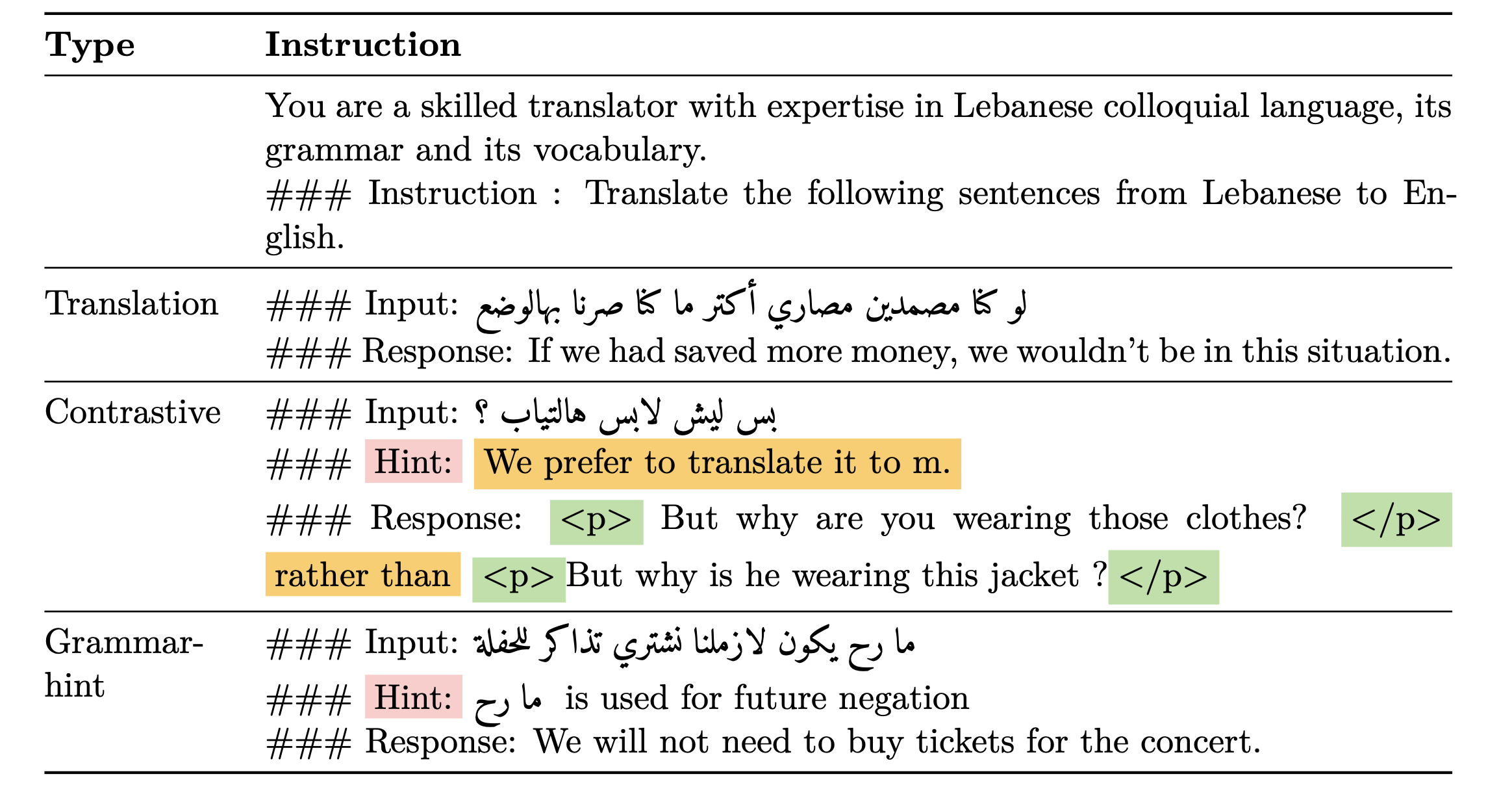
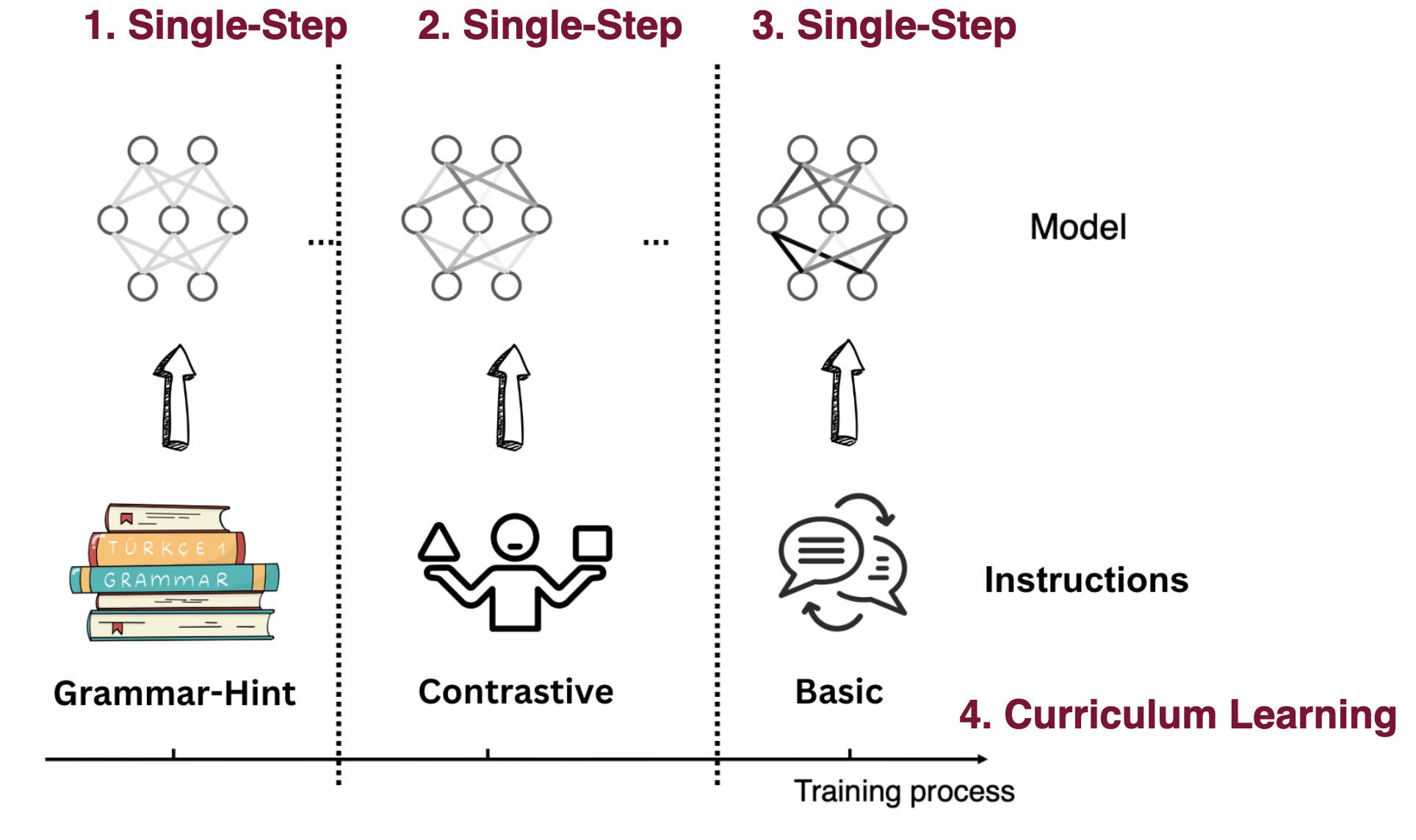
技术框架:整体框架包括数据收集与处理、模型微调和评估三个主要阶段。首先,收集包含文化信息的黎巴嫩方言数据集。然后,使用Aya23等开源LLM作为基础模型,采用三种微调策略:基础微调、对比微调和语法提示微调。对比微调通过引入负样本(例如,错误的翻译或不地道的表达)来训练模型区分好坏翻译。语法提示微调则通过提供显式的语法规则来引导模型学习。最后,使用LebEval(论文提出的新基准)和FLoRes等基准数据集对模型进行评估。
关键创新:论文的关键创新在于强调了文化真实性在低资源方言翻译中的重要性,并提出了相应的微调策略。与以往侧重于数据规模的方法不同,论文关注于数据的质量和相关性。此外,对比微调策略的引入,通过让模型学习区分好坏翻译,进一步提高了模型的性能。LebEval基准的提出也为评估黎巴嫩方言翻译模型的性能提供了更可靠的依据。
关键设计:对比微调的关键设计在于负样本的生成。论文中负样本的生成方式未知,但其质量直接影响对比学习的效果。此外,损失函数的选择也至关重要,需要能够有效地引导模型区分正负样本。Aya23模型的具体参数设置和微调超参数(如学习率、batch size等)也需要仔细调整,以获得最佳性能。LebEval基准的设计需要保证其包含足够多的黎巴嫩本土内容,并且能够覆盖各种语言现象。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在黎巴嫩方言数据集上进行对比微调的模型性能最佳,显著优于在更大规模的非母语数据集上训练的模型。具体而言,对比微调结合对比提示的方法在LebEval基准上取得了最佳效果,证明了文化真实数据和对比学习的有效性。该研究挑战了“更多数据更好”的传统观点,强调了数据质量和文化相关性的重要性。
🎯 应用场景
该研究成果可应用于低资源语言的机器翻译、跨文化交流、社交媒体内容理解等领域。通过提升低资源方言的翻译质量,可以促进不同文化背景人群之间的沟通和理解,保护和传承濒危语言,并为相关领域的自然语言处理应用提供更好的支持。未来,该方法可以推广到其他低资源语言和方言的翻译任务中。
📄 摘要(原文)
This paper examines the effectiveness of Large Language Models (LLMs) in translating the low-resource Lebanese dialect, focusing on the impact of culturally authentic data versus larger translated datasets. We compare three fine-tuning approaches: Basic, contrastive, and grammar-hint tuning, using open-source Aya23 models. Experiments reveal that models fine-tuned on a smaller but culturally aware Lebanese dataset (LW) consistently outperform those trained on larger, non-native data. The best results were achieved through contrastive fine-tuning paired with contrastive prompting, which indicates the benefits of exposing translation models to bad examples. In addition, to ensure authentic evaluation, we introduce LebEval, a new benchmark derived from native Lebanese content, and compare it to the existing FLoRes benchmark. Our findings challenge the "More Data is Better" paradigm and emphasize the crucial role of cultural authenticity in dialectal translation. We made our datasets and code available on Github.