WebThinker: Empowering Large Reasoning Models with Deep Research Capability
作者: Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yongkang Wu, Ji-Rong Wen, Yutao Zhu, Zhicheng Dou
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-04-30 (更新: 2025-10-13)
备注: Accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
WebThinker:赋予大型推理模型深度网络研究能力,提升复杂知识密集型任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型推理模型 网络搜索 知识密集型任务 报告生成 强化学习 深度网络探索 自主研究 直接偏好优化
📋 核心要点
- 现有大型推理模型依赖静态知识,在知识密集型任务和综合网络信息的研究报告生成方面存在局限性。
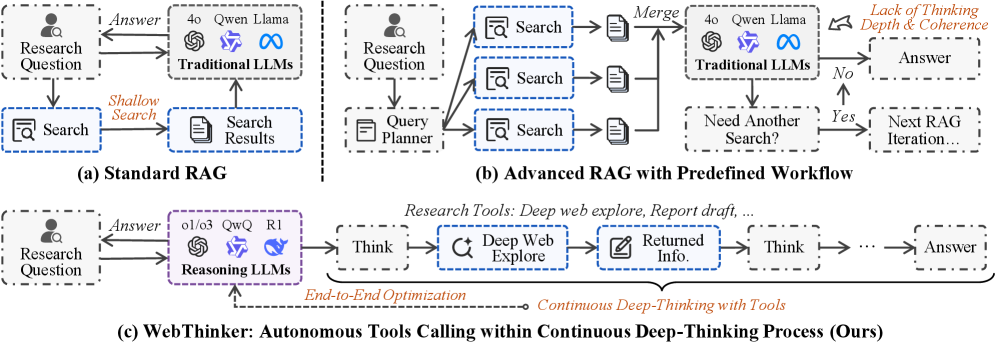
- WebThinker通过深度网络探索模块和自主思考-搜索-起草策略,赋予模型自主网络搜索、导航和报告撰写能力。
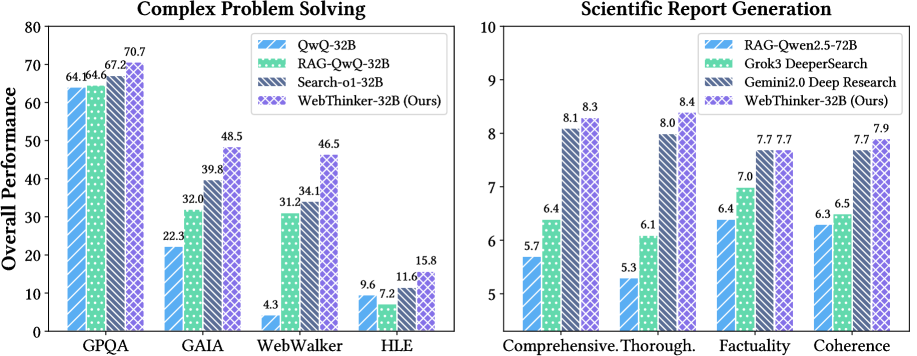
- 实验表明,WebThinker在复杂推理和科学报告生成任务上显著优于现有方法,提升了模型在复杂场景中的可靠性和适用性。
📝 摘要(中文)
大型推理模型(LRMs),如OpenAI-o1和DeepSeek-R1,展现了令人印象深刻的长程推理能力。然而,它们对静态内部知识的依赖限制了其在复杂、知识密集型任务中的表现,并阻碍了其生成需要综合各种网络信息的全面研究报告的能力。为了解决这个问题,我们提出了WebThinker,一个深度研究代理,它使LRMs能够在推理过程中自主地搜索网络、在网页之间导航并起草报告。WebThinker集成了一个深度网络探索模块,使LRMs能够在遇到知识缺口时动态地搜索、导航和提取网络信息。它还采用了一种自主的思考-搜索-起草策略,允许模型实时地无缝地交错进行推理、信息收集和报告撰写。为了进一步提高研究工具的利用率,我们通过迭代在线直接偏好优化(DPO)引入了一种基于RL的训练策略。在复杂推理基准(GPQA、GAIA、WebWalkerQA、HLE)和科学报告生成任务(Glaive)上的大量实验表明,WebThinker显著优于现有方法和强大的专有系统。我们的方法提高了LRM在复杂场景中的可靠性和适用性,为更强大和通用的深度研究系统铺平了道路。
🔬 方法详解
问题定义:现有的大型推理模型(LRMs)在处理需要大量外部知识的复杂任务时,受限于其内部静态知识库。它们无法像人类研究者一样,主动搜索、筛选和整合网络信息,导致在知识密集型任务和需要综合网络信息的报告生成任务中表现不佳。现有方法缺乏自主探索和利用网络信息的能力,难以满足复杂研究需求。
核心思路:WebThinker的核心思路是赋予LRMs自主进行网络研究的能力,使其能够像人类研究者一样,在推理过程中动态地搜索、导航和提取网络信息。通过将推理、搜索和写作过程有机结合,WebThinker能够实时地解决知识缺口,并生成高质量的研究报告。这种设计旨在弥合LRMs内部知识与外部世界之间的差距,提升其在复杂任务中的表现。
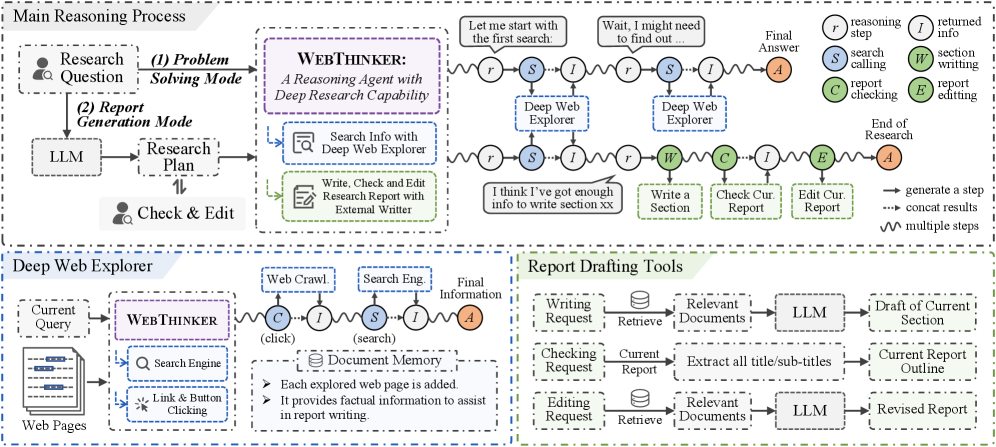
技术框架:WebThinker主要包含两个核心模块:深度网络探索模块(Deep Web Explorer)和自主思考-搜索-起草策略(Autonomous Think-Search-and-Draft)。深度网络探索模块负责动态地搜索、导航和提取网页信息,解决LRMs在推理过程中遇到的知识缺口。自主思考-搜索-起草策略则允许模型在推理、信息收集和报告撰写之间无缝切换,实现实时的问题解决和报告生成。此外,该框架还采用了基于强化学习的训练策略,通过迭代在线直接偏好优化(DPO)来提升研究工具的利用率。
关键创新:WebThinker的关键创新在于其将深度网络探索能力与大型推理模型相结合,赋予模型自主进行网络研究的能力。与传统的依赖静态知识库的方法不同,WebThinker能够动态地获取和整合外部信息,从而更好地解决复杂、知识密集型任务。此外,自主思考-搜索-起草策略也使得模型能够更加高效地进行研究和报告撰写。
关键设计:在深度网络探索模块中,需要设计合适的搜索策略和信息提取方法,以确保能够高效地找到相关信息并提取关键内容。在自主思考-搜索-起草策略中,需要设计合适的控制机制,以平衡推理、搜索和写作之间的关系,避免模型陷入无意义的搜索或写作。此外,基于RL的训练策略也需要精心设计奖励函数,以引导模型学习如何更好地利用研究工具。
🖼️ 关键图片
📊 实验亮点
实验结果表明,WebThinker在GPQA、GAIA、WebWalkerQA和HLE等复杂推理基准测试中显著优于现有方法。在科学报告生成任务(Glaive)中,WebThinker也取得了显著的性能提升,超越了现有的强大专有系统。这些结果证明了WebThinker在复杂知识密集型任务中的有效性和优越性。
🎯 应用场景
WebThinker具有广泛的应用前景,可用于自动化科学研究、市场调研、竞争情报分析等领域。它可以帮助研究人员更高效地获取和整合信息,生成高质量的研究报告。此外,WebThinker还可以应用于智能客服、虚拟助手等场景,提供更准确、更全面的知识服务。未来,WebThinker有望成为一种重要的知识生产工具,推动各行各业的智能化发展。
📄 摘要(原文)
Large reasoning models (LRMs), such as OpenAI-o1 and DeepSeek-R1, demonstrate impressive long-horizon reasoning capabilities. However, their reliance on static internal knowledge limits their performance on complex, knowledge-intensive tasks and hinders their ability to produce comprehensive research reports requiring synthesis of diverse web information. To address this, we propose WebThinker, a deep research agent that empowers LRMs to autonomously search the web, navigate among web pages, and draft reports during the reasoning process. WebThinker integrates a Deep Web Explorer module, enabling LRMs to dynamically search, navigate, and extract information from the web when encountering knowledge gaps. It also employs an Autonomous Think-Search-and-Draft strategy, allowing the model to seamlessly interleave reasoning, information gathering, and report writing in real time. To further enhance research tool utilization, we introduce an RL-based training strategy via iterative online Direct Preference Optimization (DPO). Extensive experiments on complex reasoning benchmarks (GPQA, GAIA, WebWalkerQA, HLE) and scientific report generation tasks (Glaive) demonstrate that WebThinker significantly outperforms existing methods and strong proprietary systems. Our approach enhances LRM reliability and applicability in complex scenarios, paving the way for more capable and versatile deep research systems. The code is available at https://github.com/RUC-NLPIR/WebThinker.