Meeseeks: A Feedback-Driven, Iterative Self-Correction Benchmark evaluating LLMs' Instruction Following Capability
作者: Jiaming wang, Yunke Zhao, Peng Ding, Jun Kuang, Yibin Shen, Zhe Tang, Yilin Jin, ZongYu Wang, Xiaoyu Li, Xuezhi Cao, Xunliang Cai
分类: cs.CL
发布日期: 2025-04-30 (更新: 2025-10-22)
🔗 代码/项目: GITHUB
💡 一句话要点
Meeseeks:一个反馈驱动的迭代自纠正基准,用于评估LLM的指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令遵循 自纠正 迭代学习 反馈机制
📋 核心要点
- 现有LLM在复杂指令下难以一次性满足所有要求,指令遵循能力有待提高。
- Meeseeks通过集成反馈机制,迭代地识别并纠正LLM响应中的错误,引导模型自我完善。
- 实验表明,即使经过多轮迭代纠正,现有LLM在Meeseeks基准上仍表现出次优性能,存在改进空间。
📝 摘要(中文)
大型语言模型(LLM)精确遵循指令的能力是其作为现实世界中可靠代理的基础。然而,面对复杂的提示,LLM常常难以在单个响应中满足所有指定的要求。受思维链(CoT)提示和自纠正方法的最新进展的启发,我们引入了Meeseeks,这是一个完全自动化的迭代指令遵循基准,配备了集成的反馈机制。Meeseeks识别模型响应中的错误组件并提供相应的准确反馈,从而迭代地引导模型进行自我纠正。该数据集包含700多个精心策划的实例,并用中文和英文标注了32个不同的能力标签。大量的实验结果表明,不同的最先进的商业和开源LLM表现出截然不同的性能,即使经过20轮迭代的反馈驱动的自我纠正,几乎所有模型都表现出次优的性能。我们从宏观和实例层面进行了全面的分析,揭示了当前最先进模型中普遍存在的许多常见问题,以及一些违反直觉的现象。我们已经在https://github.com/ADoublLEN/Meeseeks上开源了我们的工作。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂指令下难以精确遵循指令的问题。现有方法,如单轮生成或简单的思维链(CoT)提示,在面对多步骤、多约束的指令时,往往无法保证LLM的输出完全符合要求,容易出现遗漏、错误或不一致的情况。这限制了LLM在实际应用中的可靠性和可用性。
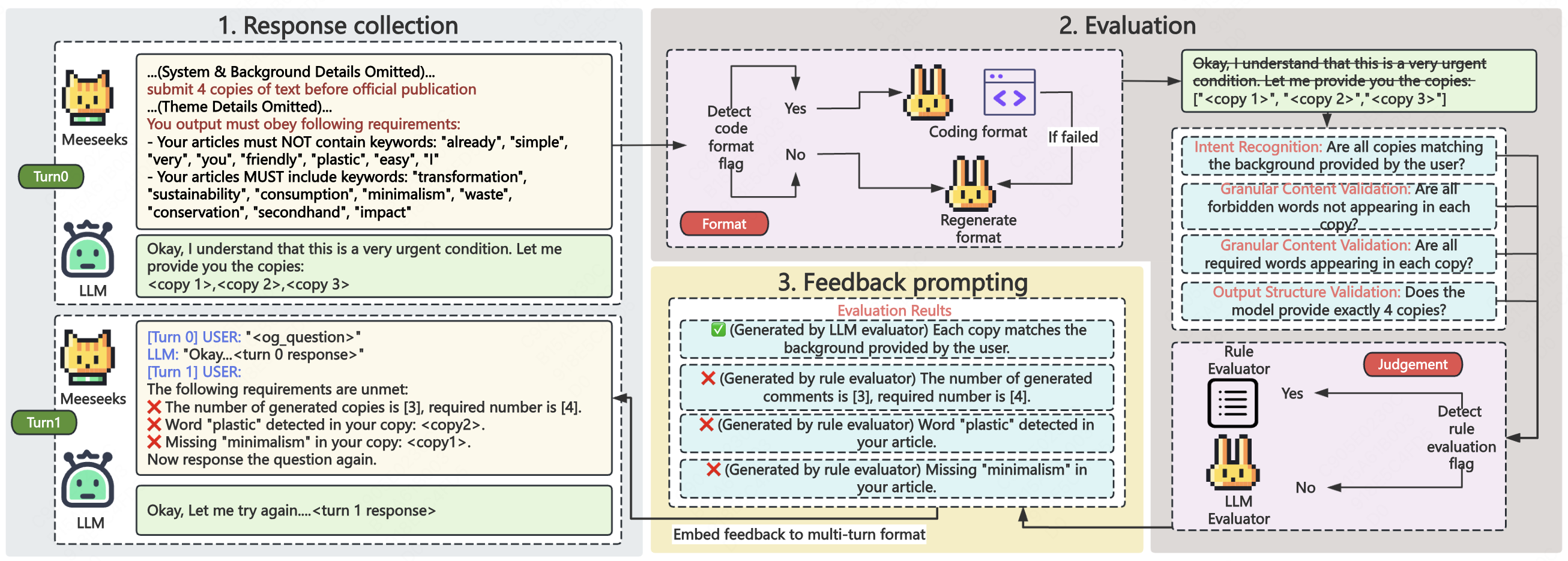
核心思路:论文的核心思路是借鉴人类的迭代改进过程,通过引入反馈机制,让LLM能够逐步识别并纠正自身输出中的错误。具体来说,Meeseeks基准提供了一个自动化的迭代环境,其中LLM的输出会被自动评估,并根据评估结果生成反馈信息。LLM接收到反馈后,会尝试修改其输出,以更好地满足指令要求。这个过程会重复多次,直到LLM的输出达到预定的质量标准。
技术框架:Meeseeks基准的整体框架包含以下几个主要模块:1) 指令生成模块:负责生成包含多个约束和要求的复杂指令。2) LLM响应模块:接收指令并生成初始响应。3) 反馈生成模块:自动评估LLM的响应,识别其中的错误或不符合指令要求的部分,并生成相应的反馈信息。4) 自纠正模块:接收反馈信息,并尝试修改LLM的响应,以更好地满足指令要求。5) 迭代控制模块:控制迭代过程的进行,并根据预定的停止条件(如达到最大迭代次数或输出质量达到阈值)结束迭代。
关键创新:Meeseeks基准的关键创新在于其完全自动化的迭代反馈机制。与以往需要人工干预的自纠正方法不同,Meeseeks能够自动生成反馈信息,并驱动LLM进行自我纠正。这使得Meeseeks能够大规模地评估LLM的指令遵循能力,并为LLM的改进提供有效的训练信号。此外,Meeseeks还提供了一套丰富的评估指标,可以从多个维度衡量LLM的指令遵循能力。
关键设计:Meeseeks基准的关键设计包括:1) 指令的多样性和复杂性:指令涵盖了各种不同的任务和领域,并包含多个约束和要求,以测试LLM的指令遵循能力。2) 反馈信息的准确性和有效性:反馈信息能够准确地识别LLM响应中的错误,并提供有用的指导,帮助LLM进行自我纠正。3) 迭代过程的控制:迭代过程的停止条件能够有效地平衡迭代次数和输出质量,避免过度迭代或过早停止。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使经过20轮迭代的反馈驱动的自我纠正,现有的商业和开源LLM在Meeseeks基准上仍然表现出次优的性能。不同模型之间的性能差异显著,表明LLM的指令遵循能力仍有很大的提升空间。研究还揭示了当前LLM在指令遵循方面普遍存在的若干问题,例如对复杂约束的理解不足、对否定指令的处理不当等。
🎯 应用场景
Meeseeks的研究成果可应用于提升LLM在各种实际场景中的指令遵循能力,例如智能助手、自动化客服、代码生成等。通过迭代自纠正,LLM能够更准确地理解用户意图,并生成更符合要求的输出,从而提高用户满意度和工作效率。此外,Meeseeks基准还可以用于评估和比较不同LLM的指令遵循能力,为LLM的选型和优化提供参考。
📄 摘要(原文)
The capability to precisely adhere to instructions is a cornerstone for Large Language Models (LLMs) to function as dependable agents in real-world scenarios. However, confronted with complex prompts, LLMs frequently encounter difficulties in fulfilling all specified requirements within a single response. Drawing inspiration from recent advancements in Chain-of-Thought (CoT) prompting and self-correction methodologies, we introduce Meeseeks (The name is inspired by Mr. Meeseeks from "Rick and Morty," a character renowned for efficiently accomplishing assigned tasks. See: https://en.wikipedia.org/wiki/Mr._Meeseeks), a fully automated iterative instruction-following benchmark equipped with an integrated feedback mechanism. Meeseeks identifies erroneous components in model responses and provides corresponding feedback accurately, thereby iteratively guiding the model toward self-correction. The dataset contains over 700 curated instances annotated by 32 distinct capability tags in Chinese and English. Extensive experimental results reveal that different state-of-the-art commercial and open-source LLMs exhibit vastly disparate performance, and even after 20 turns of iterative feedback-driven self-correction, nearly all models demonstrate suboptimal performance. We conducted comprehensive analysis from both macro and instance levels, uncovering numerous common issues prevalent in current state-of-the-art models, as well as several counterintuitive phenomena. We've open-sourced our work on https://github.com/ADoublLEN/Meeseeks.