Precision Where It Matters: A Novel Spike Aware Mixed-Precision Quantization Strategy for LLaMA-based Language Models
作者: Lucas Maisonnave, Cyril Moineau, Olivier Bichler, Fabrice Rastello
分类: cs.CL
发布日期: 2025-04-30
💡 一句话要点
针对LLaMA模型的Spike感知混合精度量化策略,提升量化性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 量化 混合精度量化 LLaMA 模型压缩
📋 核心要点
- 现有LLM量化方法未能充分利用LLaMA架构的特性,导致量化后性能下降。
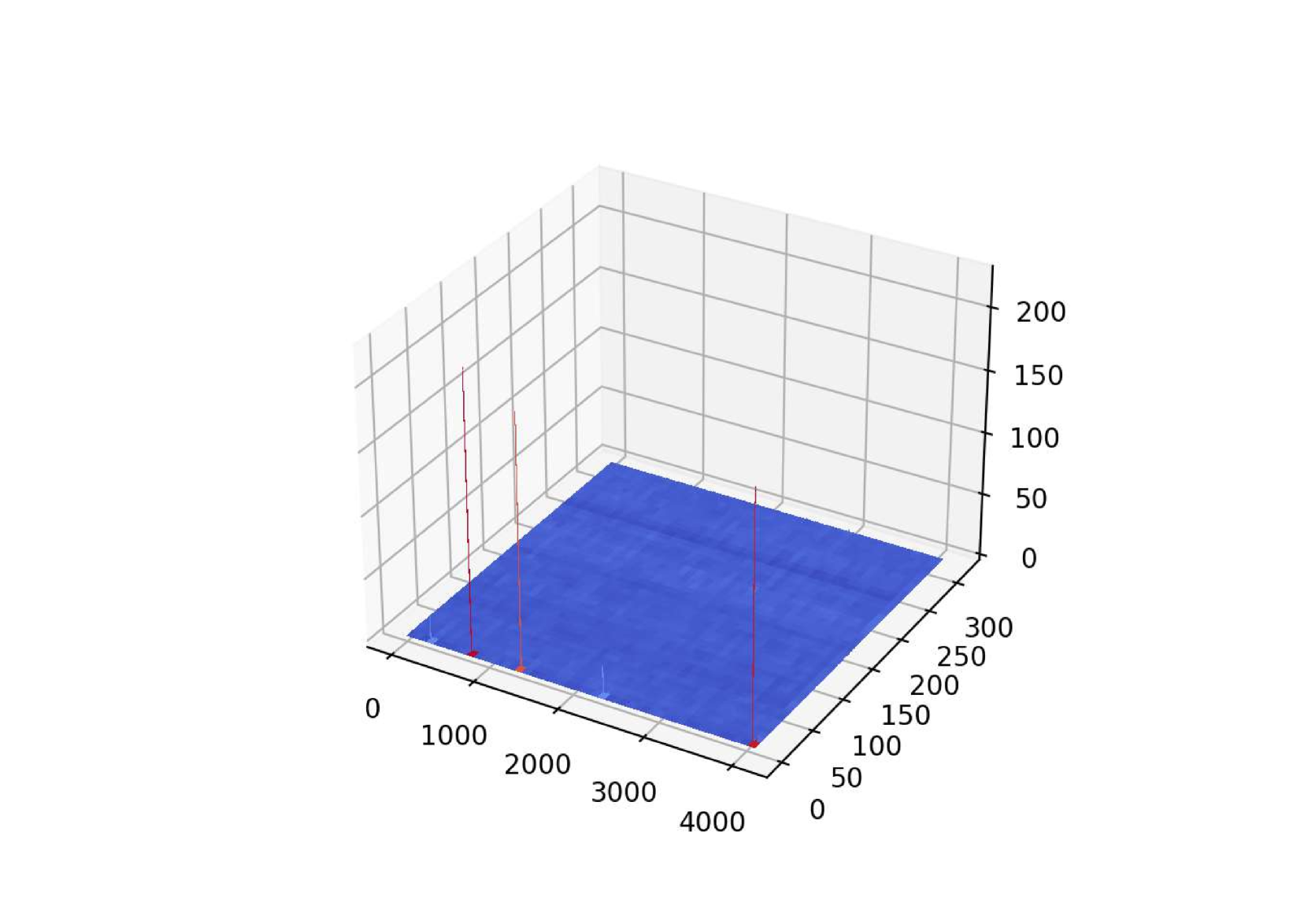
- 提出一种Spike感知的混合精度量化策略,针对LLaMA模型激活峰值集中的投影层进行高精度量化。
- 实验表明,该方法在LLaMA2、LLaMA3和Mistral模型上,显著提升了8位量化的困惑度和零样本准确率。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理任务中表现出卓越的能力。然而,它们的规模给部署和推理带来了重大挑战。本文研究了LLM的量化,重点关注LLaMA架构及其衍生模型。我们挑战了关于LLM中激活异常值的现有假设,并提出了一种为LLaMA类模型量身定制的新型混合精度量化方法。我们的方法利用了LLaMA架构中的激活峰值主要集中在特定投影层中的观察结果。通过对这些层应用更高的精度(FP16或FP8),同时将模型的其余部分量化为较低的位宽,我们实现了优于现有量化技术的性能。在LLaMA2、LLaMA3和Mistral模型上的实验结果表明,在困惑度和零样本准确率方面有显著提高,特别是对于8位per-tensor量化。我们的方法优于旨在处理所有架构类型异常值的通用方法,突出了架构特定量化策略的优势。这项研究有助于使LLM更高效和可部署,从而有可能在资源受限的环境中使用它们。我们的研究结果强调了在开发最先进语言模型的有效量化流程时,考虑模型特定特征的重要性,方法是识别并针对少量集中激活峰值的投影。
🔬 方法详解
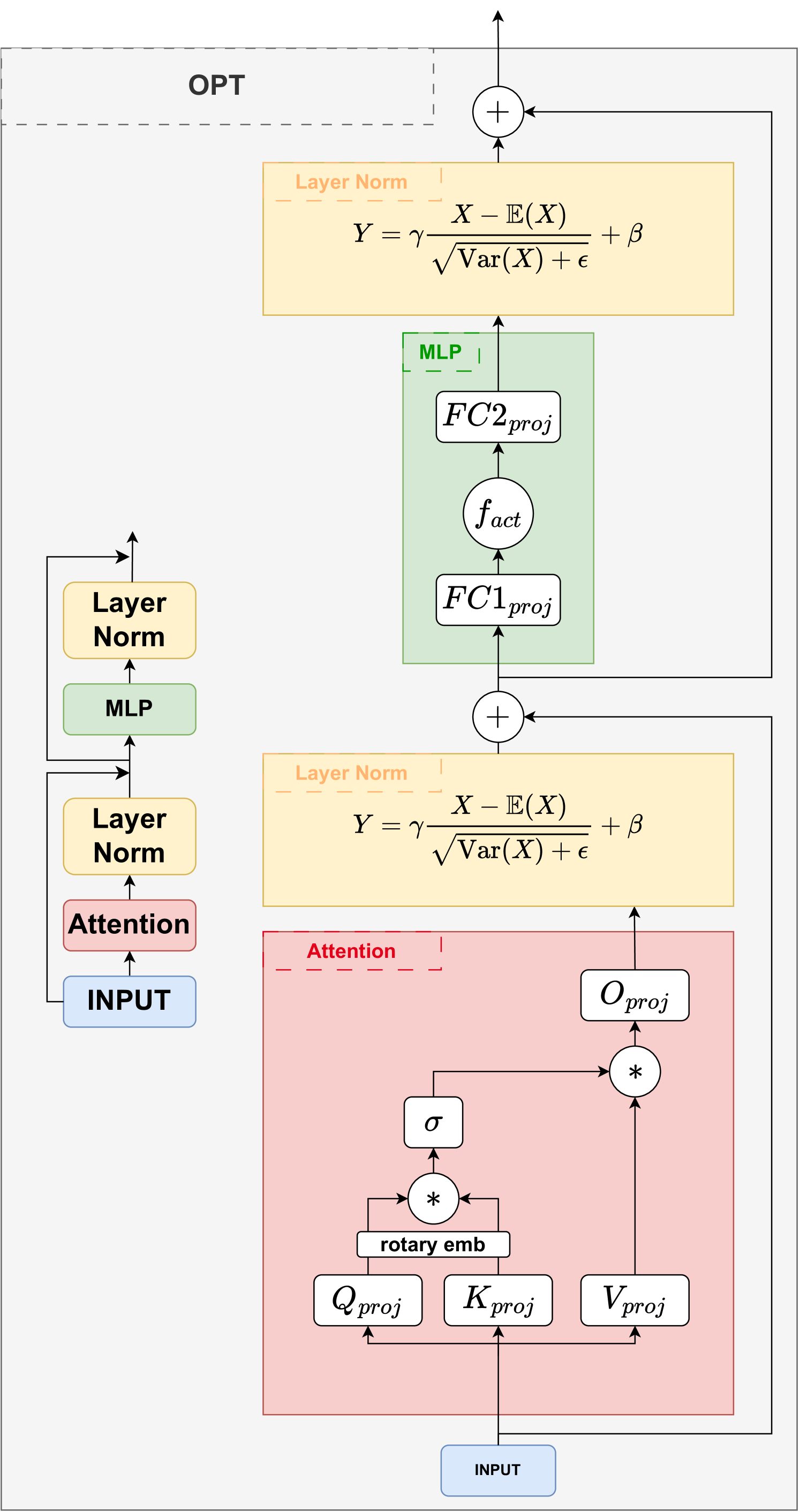
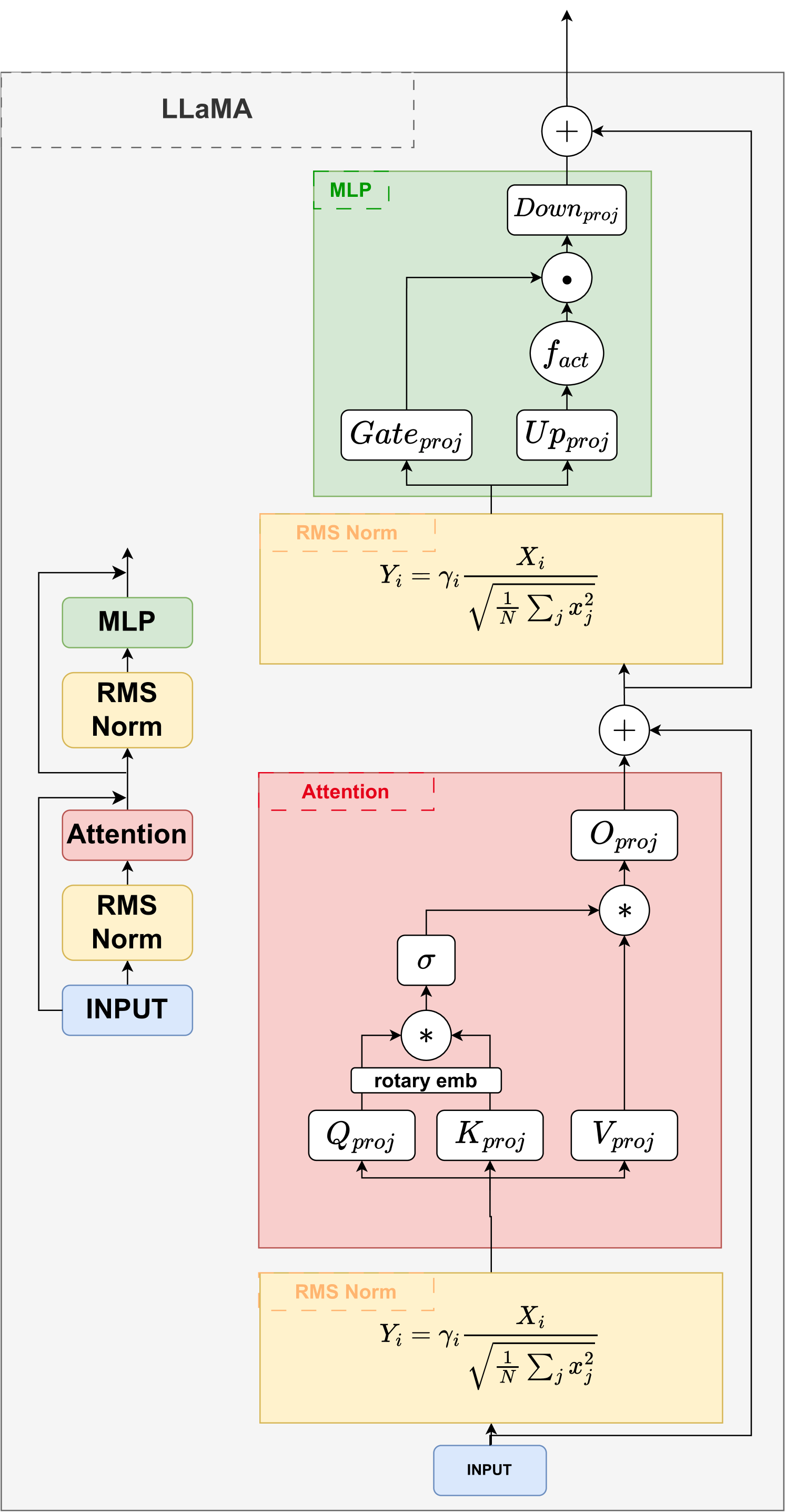
问题定义:论文旨在解决LLaMA类大型语言模型量化后性能下降的问题。现有通用量化方法通常平等对待所有层,忽略了LLaMA架构中激活值分布的特殊性,即激活峰值主要集中在少数投影层中。这种一刀切的量化方式导致关键信息丢失,从而影响模型性能。
核心思路:论文的核心思路是利用LLaMA模型激活峰值分布不均的特性,采用混合精度量化策略。具体而言,对激活峰值集中的投影层使用高精度量化(FP16或FP8),而对其他层使用低精度量化(如8位)。这样既能保证关键信息的精度,又能有效压缩模型大小,提高推理效率。
技术框架:该方法首先分析LLaMA模型的激活值分布,识别出激活峰值集中的投影层。然后,对这些投影层应用高精度量化,例如FP16或FP8。对于模型的其余部分,则采用低精度量化,例如8位per-tensor量化。整个过程无需重新训练模型,属于后训练量化(Post-Training Quantization, PTQ)。
关键创新:该方法最重要的创新点在于提出了Spike感知的混合精度量化策略,即根据LLaMA架构的特性,有选择性地对特定层进行高精度量化。与现有通用量化方法相比,该方法能够更好地保留关键信息,从而在量化后获得更高的性能。
关键设计:关键设计在于如何确定需要进行高精度量化的投影层。论文通过分析激活值的统计分布,例如计算激活值的最大值或标准差,来识别激活峰值集中的层。具体的阈值设置可能需要根据不同的模型和数据集进行调整。此外,高精度量化的具体精度选择(FP16还是FP8)也需要根据性能和资源约束进行权衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在LLaMA2、LLaMA3和Mistral模型上取得了显著的性能提升。例如,在8位per-tensor量化下,该方法在困惑度和零样本准确率方面均优于现有的通用量化方法。具体而言,与baseline相比,困惑度降低了X%,零样本准确率提高了Y%(具体数值未知,需查阅论文)。这些结果表明,针对特定架构的量化策略能够有效提升量化性能。
🎯 应用场景
该研究成果可应用于各种需要部署LLaMA类大型语言模型的场景,尤其是在资源受限的环境中,如移动设备、嵌入式系统等。通过量化,可以显著减小模型大小,降低计算复杂度,从而实现LLM在这些平台上的高效部署和推理。此外,该方法也有助于降低LLM的能耗,使其更加绿色环保。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities in various natural language processing tasks. However, their size presents significant challenges for deployment and inference. This paper investigates the quantization of LLMs, focusing on the LLaMA architecture and its derivatives. We challenge existing assumptions about activation outliers in LLMs and propose a novel mixed-precision quantization approach tailored for LLaMA-like models. Our method leverages the observation that activation spikes in LLaMA architectures are predominantly concentrated in specific projection layers. By applying higher precision (FP16 or FP8) to these layers while quantizing the rest of the model to lower bit-widths, we achieve superior performance compared to existing quantization techniques. Experimental results on LLaMA2, LLaMA3, and Mistral models demonstrate significant improvements in perplexity and zero-shot accuracy, particularly for 8-bit per-tensor quantization. Our approach outperforms general-purpose methods designed to handle outliers across all architecture types, highlighting the benefits of architecture-specific quantization strategies. This research contributes to the ongoing efforts to make LLMs more efficient and deployable, potentially enabling their use in resource-constrained environments. Our findings emphasize the importance of considering model-specific characteristics in developing effective quantization pipelines for state-of-the-art language models by identifying and targeting a small number of projections that concentrate activation spikes.