Automatic Legal Writing Evaluation of LLMs
作者: Ramon Pires, Roseval Malaquias Junior, Rodrigo Nogueira
分类: cs.CL, cs.AI
发布日期: 2025-04-29
💡 一句话要点
提出oab-bench:用于自动评估LLM法律写作能力的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法律写作评估 大型语言模型 基准数据集 自动评分 法律人工智能
📋 核心要点
- 现有法律写作评估基准稀缺,缺乏公开、更新频繁且包含全面评估指南的数据集。
- 提出oab-bench基准,包含巴西律师资格考试的105个问题,并提供详细的评估指南和参考资料。
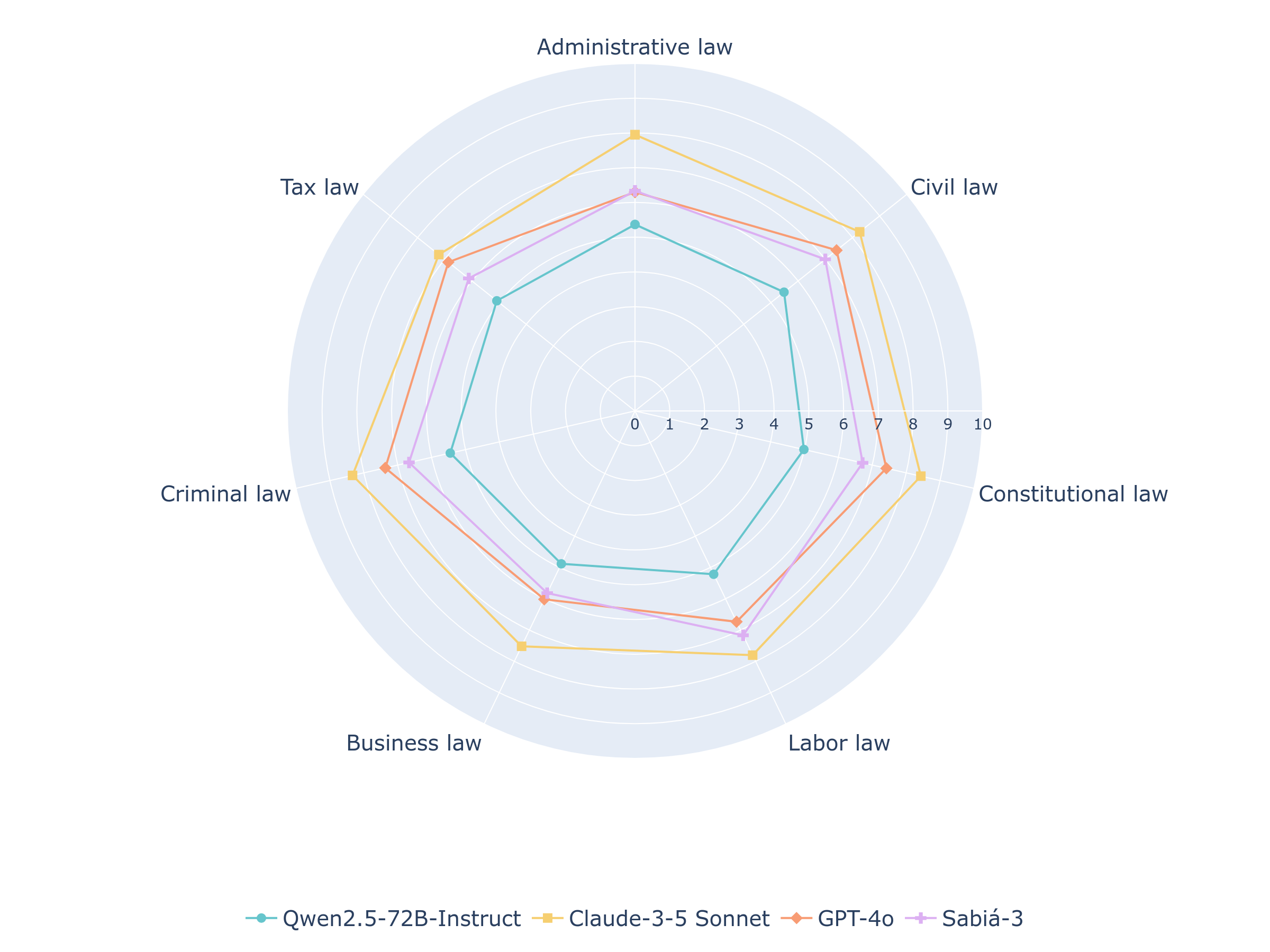
- 实验表明,Claude-3.5 Sonnet在oab-bench上表现最佳,OpenAI的o1模型与人类评分具有很强的相关性。
📝 摘要(中文)
由于评估开放式法律写作的复杂性,评估大型语言模型(LLM)法律写作能力的基准仍然稀缺。在特定领域评估语言模型时,关键挑战在于找到公开、频繁更新且包含全面评估指南的测试数据集。巴西律师资格考试满足这些要求。我们引入oab-bench,一个包含来自近期考试的七个法律领域共105个问题的基准。该基准包括人类考官使用的全面评估指南和参考资料,以确保评分一致性。我们评估了四个LLM在oab-bench上的表现,发现Claude-3.5 Sonnet取得了最佳结果,平均得分为7.93(满分10分),通过了所有21项考试。我们还研究了LLM是否可以作为可靠的自动评分员来评估法律写作。实验表明,像OpenAI的o1这样的前沿模型在评估已批准的考试时,与人类评分具有很强的相关性,表明它们有潜力成为可靠的自动评估器,尽管法律写作评估本质上是主观的。源代码和基准测试(包含问题、评估指南、模型生成的响应及其各自的自动评估)均已公开。
🔬 方法详解
问题定义:现有方法缺乏针对法律领域LLM写作能力的有效评估基准。评估法律写作的复杂性在于其主观性,以及缺乏公开、频繁更新且包含全面评估指南的数据集。这使得难以客观地衡量和比较不同LLM在法律写作方面的表现。
核心思路:论文的核心思路是利用巴西律师资格考试(OAB)作为评估LLM法律写作能力的基准。OAB考试具有公开性、定期更新以及包含详细评分标准的优点,可以为LLM的法律写作能力提供一个客观的评估平台。此外,论文还探索了利用LLM本身作为自动评分员的可能性。
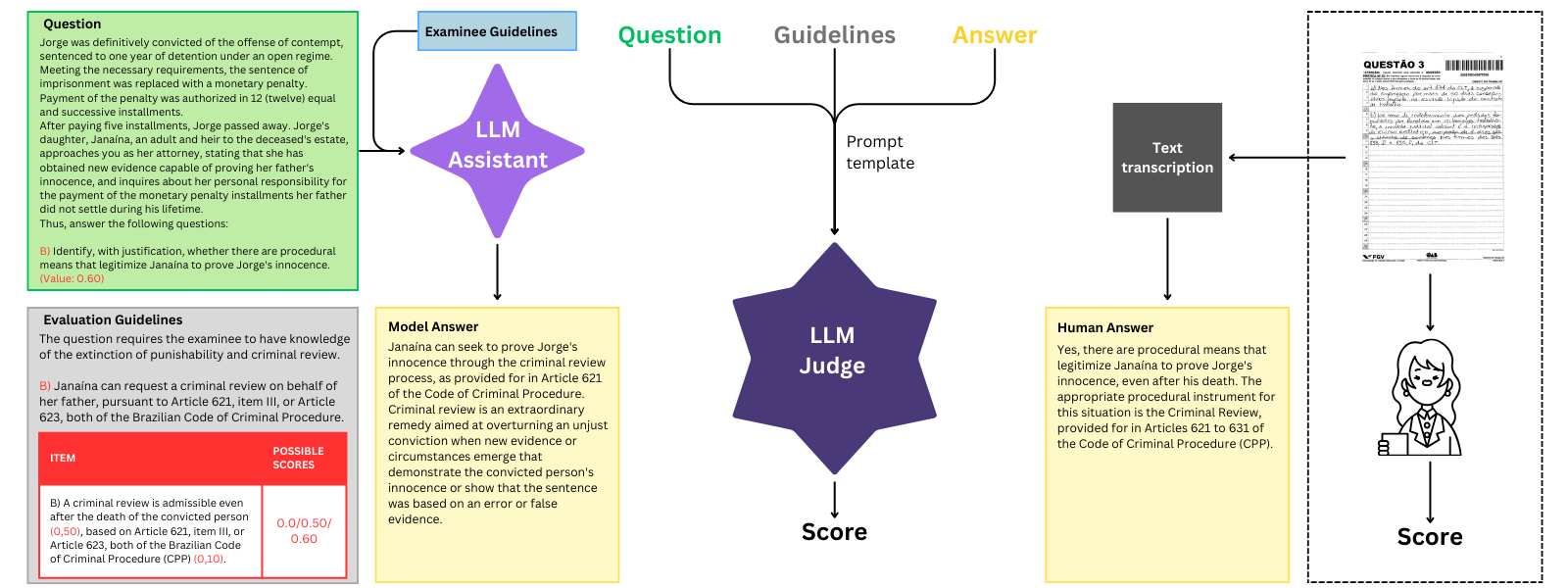
技术框架:该研究主要包含两个部分:1) 构建oab-bench基准数据集,包括从OAB考试中提取的105个问题,涵盖七个法律领域,并提供详细的评估指南和参考资料。2) 评估多个LLM在oab-bench上的表现,并分析LLM作为自动评分员的可靠性。评估过程包括使用LLM生成对问题的回答,然后使用人工评分和自动评分两种方式进行评估,并比较两种评分方式的相关性。
关键创新:论文的关键创新在于提出了oab-bench基准,这是一个专门用于评估LLM法律写作能力的新数据集。与现有通用型基准相比,oab-bench更具领域针对性,能够更准确地反映LLM在法律领域的写作能力。此外,论文还探索了利用LLM进行自动评分的可能性,为法律写作评估提供了一种新的思路。
关键设计:oab-bench基准的关键设计在于其问题的选择和评估指南的制定。问题来源于真实的OAB考试,涵盖了多个法律领域,具有很高的代表性。评估指南则由专业的法律人士制定,确保评分的客观性和一致性。在评估LLM作为自动评分员的可靠性时,论文采用了Spearman相关系数来衡量自动评分与人工评分之间的相关性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Claude-3.5 Sonnet在oab-bench上取得了最佳表现,平均得分为7.93(满分10分),通过了所有21项考试。此外,OpenAI的o1模型在评估已批准的考试时,与人类评分具有很强的相关性,表明其有潜力作为可靠的自动评估器。这些结果验证了oab-bench基准的有效性,并为LLM在法律领域的应用提供了有价值的参考。
🎯 应用场景
该研究成果可应用于法律人工智能领域,例如自动法律文书生成、法律咨询、法律教育等。oab-bench基准可以帮助研究人员更好地评估和改进LLM在法律领域的应用。此外,利用LLM进行自动评分可以提高法律写作评估的效率和一致性,降低人工成本,并为法律教育提供个性化反馈。
📄 摘要(原文)
Despite the recent advances in Large Language Models, benchmarks for evaluating legal writing remain scarce due to the inherent complexity of assessing open-ended responses in this domain. One of the key challenges in evaluating language models on domain-specific tasks is finding test datasets that are public, frequently updated, and contain comprehensive evaluation guidelines. The Brazilian Bar Examination meets these requirements. We introduce oab-bench, a benchmark comprising 105 questions across seven areas of law from recent editions of the exam. The benchmark includes comprehensive evaluation guidelines and reference materials used by human examiners to ensure consistent grading. We evaluate the performance of four LLMs on oab-bench, finding that Claude-3.5 Sonnet achieves the best results with an average score of 7.93 out of 10, passing all 21 exams. We also investigated whether LLMs can serve as reliable automated judges for evaluating legal writing. Our experiments show that frontier models like OpenAI's o1 achieve a strong correlation with human scores when evaluating approved exams, suggesting their potential as reliable automated evaluators despite the inherently subjective nature of legal writing assessment. The source code and the benchmark -- containing questions, evaluation guidelines, model-generated responses, and their respective automated evaluations -- are publicly available.