OSVBench: Benchmarking LLMs on Specification Generation Tasks for Operating System Verification
作者: Shangyu Li, Juyong Jiang, Tiancheng Zhao, Jiasi Shen
分类: cs.CL, cs.AI, cs.OS, cs.PL, cs.SE
发布日期: 2025-04-29 (更新: 2025-12-07)
🔗 代码/项目: GITHUB
💡 一句话要点
OSVBench:用于操作系统验证的LLM规范生成基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 操作系统验证 形式化规范生成 大型语言模型 程序合成 长上下文学习
📋 核心要点
- 现有方法难以生成操作系统内核验证所需的完整形式化规范,这需要理解长上下文代码和复杂的编程模型。
- OSVBench通过将规范生成任务形式化为程序合成问题,并提供编程模型,引导LLM生成描述正确状态和转换的规范。
- 实验结果表明,现有LLM在OSVBench上的性能有限,尤其是在处理长上下文代码生成任务时,模型间性能差异显著。
📝 摘要(中文)
本文介绍OSVBench,这是一个新的基准测试,用于评估大型语言模型(LLM)在为操作系统内核的功能正确性验证生成完整形式化规范方面的能力。该基准建立在真实的操作系统内核Hyperkernel之上,总共包含245个复杂的规范生成任务,每个任务都是一个大约20k-30k tokens的长上下文任务。该基准将规范生成任务定义为一个程序合成问题,该问题被限制在用于指定状态和转换的领域内。这种形式化通过编程模型提供给LLM。LLM必须能够理解编程模型和验证假设,然后才能描绘出正确的语法和语义搜索空间并生成形式化规范。在操作系统的高级功能描述的指导下,要求LLM生成一个规范,该规范完整地描述了操作系统潜在错误代码实现的所有正确状态和转换。对12个最先进的LLM的实验结果表明,现有LLM在操作系统验证的规范生成任务上的性能有限。它们性能上的显著差异突出了它们处理长上下文代码生成任务的能力差异。代码可在https://github.com/lishangyu-hkust/OSVBench 获取。
🔬 方法详解
问题定义:论文旨在解决操作系统内核验证中形式化规范自动生成的问题。现有方法难以处理操作系统内核代码的长上下文依赖和复杂的状态转换逻辑,导致生成的规范不完整或不正确。这使得利用形式化方法验证操作系统内核的正确性变得困难。
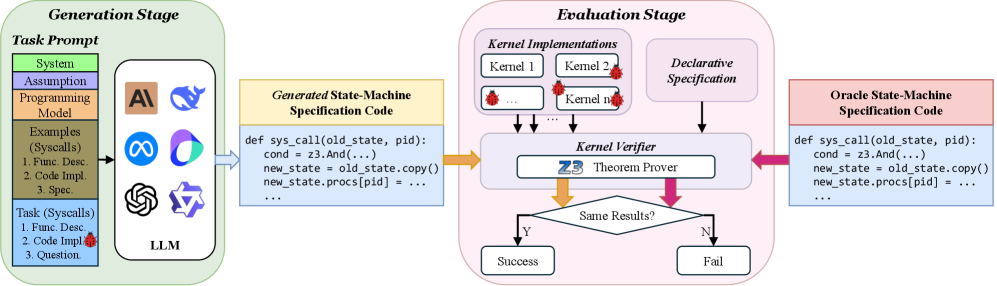
核心思路:论文的核心思路是将形式化规范生成问题转化为一个程序合成问题,并利用LLM的强大代码生成能力来解决。通过提供一个编程模型,将规范的语法和语义约束显式地传递给LLM,引导LLM在正确的搜索空间内生成规范。
技术框架:OSVBench基准测试包含以下几个关键组成部分:1) 基于真实操作系统内核Hyperkernel构建的245个规范生成任务;2) 一个用于描述状态和转换的编程模型,该模型定义了规范的语法和语义;3) 一套评估指标,用于衡量生成的规范的完整性和正确性。LLM接收操作系统代码和编程模型作为输入,输出形式化规范。
关键创新:该论文的关键创新在于:1) 提出了一个将形式化规范生成问题转化为程序合成问题的框架;2) 设计了一个用于描述操作系统状态和转换的编程模型,该模型可以有效地引导LLM生成规范;3) 构建了一个大规模的基准测试OSVBench,用于评估LLM在操作系统验证任务上的性能。
关键设计:编程模型是关键设计之一,它定义了状态和转换的语法和语义。具体来说,编程模型可能包含以下元素:状态变量的类型定义、状态转换函数的签名、以及状态转换的约束条件。此外,长上下文的处理也是一个关键设计,可能需要采用一些技巧,例如上下文压缩或分层处理,以提高LLM的性能。
🖼️ 关键图片
📊 实验亮点
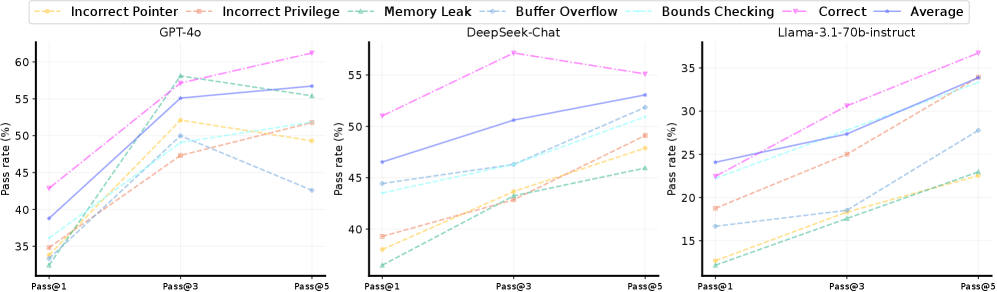
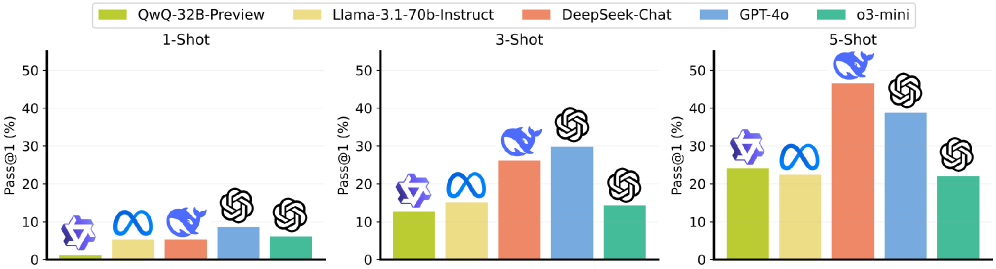
实验结果表明,现有的12个最先进的LLM在OSVBench上的性能有限,这表明操作系统验证的规范生成任务对LLM来说仍然是一个挑战。不同LLM之间的性能差异显著,这表明它们在处理长上下文代码生成任务方面的能力存在差异。这些结果为未来研究如何提高LLM在操作系统验证任务上的性能提供了有价值的参考。
🎯 应用场景
该研究成果可应用于操作系统内核的自动验证,提高操作系统的可靠性和安全性。通过自动生成形式化规范,可以减少人工编写规范的工作量,并提高验证的效率。此外,该方法还可以推广到其他软件系统的验证领域,例如嵌入式系统和网络协议。
📄 摘要(原文)
We introduce OSVBench, a new benchmark for evaluating Large Language Models (LLMs) on the task of generating complete formal specifications for verifying the functional correctness of operating system kernels. This benchmark is built upon a real-world operating system kernel, Hyperkernel, and consists of 245 complex specification generation tasks in total, each of which is a long-context task of about 20k-30k tokens. The benchmark formulates the specification generation task as a program synthesis problem confined to a domain for specifying states and transitions. This formulation is provided to LLMs through a programming model. The LLMs must be able to understand the programming model and verification assumptions before delineating the correct search space for syntax and semantics and generating formal specifications. Guided by the operating system's high-level functional description, the LLMs are asked to generate a specification that fully describes all correct states and transitions for a potentially buggy code implementation of the operating system. Experimental results with 12 state-of-the-art LLMs indicate limited performance of existing LLMs on the specification generation task for operating system verification. Significant disparities in their performance highlight differences in their ability to handle long-context code generation tasks. The code are available at https://github.com/lishangyu-hkust/OSVBench