A Generative-AI-Driven Claim Retrieval System Capable of Detecting and Retrieving Claims from Social Media Platforms in Multiple Languages
作者: Ivan Vykopal, Martin Hyben, Robert Moro, Michal Gregor, Jakub Simko
分类: cs.CL
发布日期: 2025-04-29
💡 一句话要点
提出基于生成式AI的声明检索系统,用于多语言社交媒体平台的事实核查。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 声明检索 大型语言模型 自然语言处理 信息过滤
📋 核心要点
- 事实核查面临重复验证已核实声明的挑战,效率低下,影响对新信息的响应速度。
- 利用大型语言模型过滤不相关的事实核查,并生成简洁摘要和解释,辅助快速评估。
- 通过自动和人工评估验证了该方法,结果表明LLM能有效减少不相关信息,简化流程。
📝 摘要(中文)
在线虚假信息构成全球性挑战,对事实核查人员提出了巨大需求,他们必须高效地验证声明,以防止错误信息的传播。该过程中的一个主要问题是重复验证已经核实过的声明,这增加了工作量并延迟了对新出现的声明的响应。本研究提出了一种检索先前经过事实核查的声明的方法,评估它们与给定输入的相关性,并提供补充信息以支持事实核查人员。我们的方法采用大型语言模型(LLM)来过滤不相关的事实核查,并生成简洁的摘要和解释,使事实核查人员能够更快地评估某个声明是否已被验证。此外,我们通过自动和人工评估来评估我们的方法,其中人类与开发的工具交互以审查其有效性。我们的结果表明,LLM能够过滤掉许多不相关的事实核查,从而减少工作量并简化事实核查过程。
🔬 方法详解
问题定义:该论文旨在解决事实核查过程中重复验证已核实声明的问题。现有方法的痛点在于,面对海量信息,事实核查人员需要花费大量时间筛选和判断,效率低下,且容易遗漏已验证的信息。这导致资源浪费,并延缓了对新出现虚假信息的响应速度。
核心思路:论文的核心思路是利用大型语言模型(LLM)的语义理解和生成能力,构建一个声明检索系统。该系统能够根据输入的待核查声明,自动检索数据库中已有的事实核查记录,并评估其相关性。通过LLM的过滤和摘要功能,可以快速排除不相关的信息,并为事实核查人员提供简洁明了的参考。
技术框架:该系统的整体框架包含以下几个主要模块:1) 声明检索模块:负责从事实核查数据库中检索与输入声明相关的记录;2) 相关性评估模块:利用LLM对检索到的记录与输入声明进行语义相似度评估,过滤掉不相关的记录;3) 摘要生成模块:利用LLM对相关的事实核查记录进行摘要,生成简洁的解释和结论;4) 用户交互界面:提供友好的用户界面,方便事实核查人员输入声明并查看检索结果。
关键创新:该论文的关键创新在于将大型语言模型应用于事实核查领域的声明检索任务。与传统的基于关键词匹配或浅层语义分析的方法相比,LLM能够更准确地理解声明的语义,并识别出潜在的相关信息。此外,LLM的摘要生成能力可以帮助事实核查人员快速获取关键信息,提高工作效率。
关键设计:论文中可能涉及的关键设计包括:1) LLM的选择和微调:选择合适的LLM模型,并使用事实核查领域的数据进行微调,以提高其在该领域的性能;2) 相似度评估策略:设计有效的相似度评估方法,例如使用余弦相似度或基于Transformer的语义匹配模型;3) 摘要生成策略:采用合适的摘要生成算法,例如抽取式摘要或生成式摘要,并控制摘要的长度和信息量。
🖼️ 关键图片


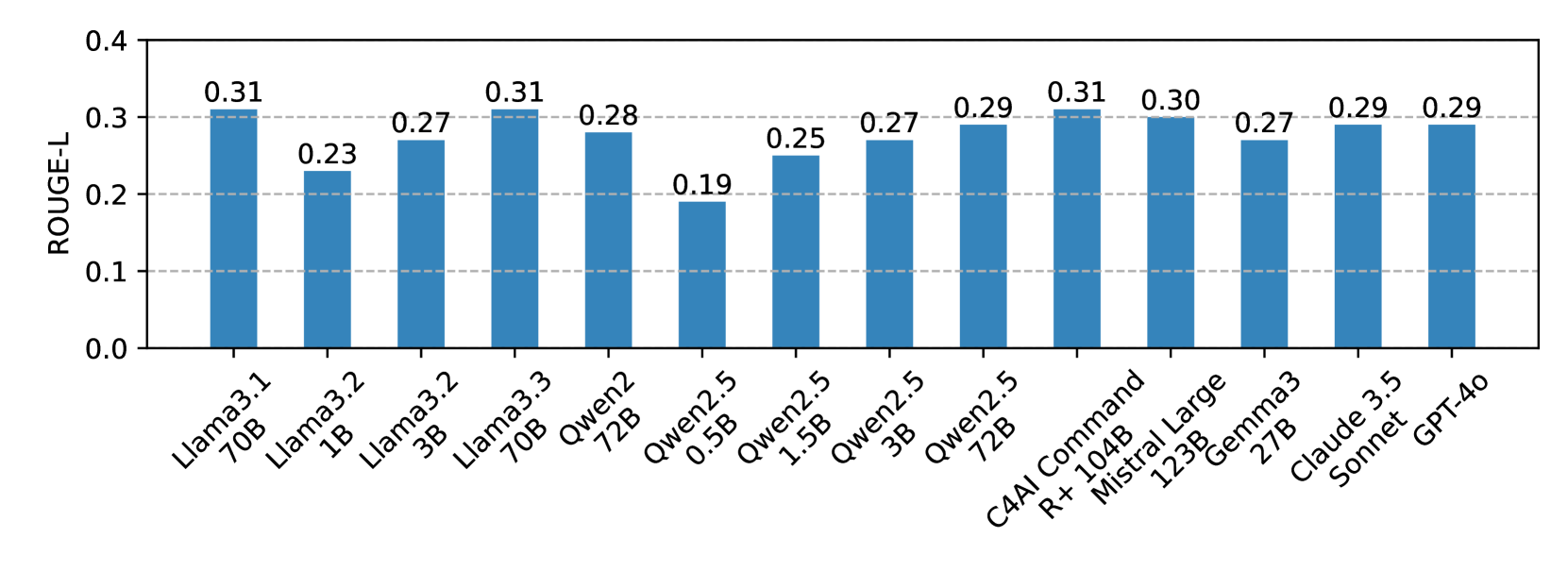
📊 实验亮点
论文通过自动和人工评估验证了该方法的有效性。实验结果表明,LLM能够有效过滤掉大量不相关的事实核查记录,显著减少了事实核查人员的工作量。具体的性能数据(例如,相关性评估的准确率、摘要的质量评估指标等)在原文中应有更详细的描述。
🎯 应用场景
该研究成果可应用于各类社交媒体平台、新闻机构和事实核查组织,帮助快速识别和验证虚假信息,减少重复劳动,提高事实核查效率。未来,该系统可扩展到更多语言和领域,并与其他反欺诈技术相结合,构建更完善的网络安全体系。
📄 摘要(原文)
Online disinformation poses a global challenge, placing significant demands on fact-checkers who must verify claims efficiently to prevent the spread of false information. A major issue in this process is the redundant verification of already fact-checked claims, which increases workload and delays responses to newly emerging claims. This research introduces an approach that retrieves previously fact-checked claims, evaluates their relevance to a given input, and provides supplementary information to support fact-checkers. Our method employs large language models (LLMs) to filter irrelevant fact-checks and generate concise summaries and explanations, enabling fact-checkers to faster assess whether a claim has been verified before. In addition, we evaluate our approach through both automatic and human assessments, where humans interact with the developed tool to review its effectiveness. Our results demonstrate that LLMs are able to filter out many irrelevant fact-checks and, therefore, reduce effort and streamline the fact-checking process.