WenyanGPT: A Large Language Model for Classical Chinese Tasks
作者: Xinyu Yao, Mengdi Wang, Bo Chen, Xiaobing Zhao
分类: cs.CL
发布日期: 2025-04-29
💡 一句话要点
WenyanGPT:面向古文任务的大语言模型,性能显著超越现有模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 古文处理 大语言模型 LLaMA3 指令微调 预训练 WenyanBENCH 自然语言处理
📋 核心要点
- 现有自然语言处理模型主要针对现代汉语优化,在古文处理方面表现不足,无法有效支持古籍研究。
- 通过在LLaMA3-8B-Chinese上持续预训练和指令微调,构建了WenyanGPT,专门处理古文任务。
- WenyanGPT在WenyanBENCH上显著优于现有先进大语言模型,证明了其在古文处理方面的优越性。
📝 摘要(中文)
本文提出了一个针对古文语言处理的全面解决方案。通过在LLaMA3-8B-Chinese模型上进行持续预训练和指令微调,构建了一个专门为古文任务设计的大语言模型WenyanGPT。此外,还开发了一个评估基准数据集WenyanBENCH。在WenyanBENCH上的实验结果表明,WenyanGPT在各种古文任务中显著优于当前先进的大语言模型。该模型训练数据、指令微调数据和评估基准数据集均已公开,以促进古文处理领域的进一步研究和发展。
🔬 方法详解
问题定义:论文旨在解决现有NLP模型在古文处理任务上的性能不足问题。现有模型主要针对现代汉语进行优化,无法有效处理古文的特殊语法、词汇和文化背景,导致在古文理解、翻译、生成等任务中表现不佳。
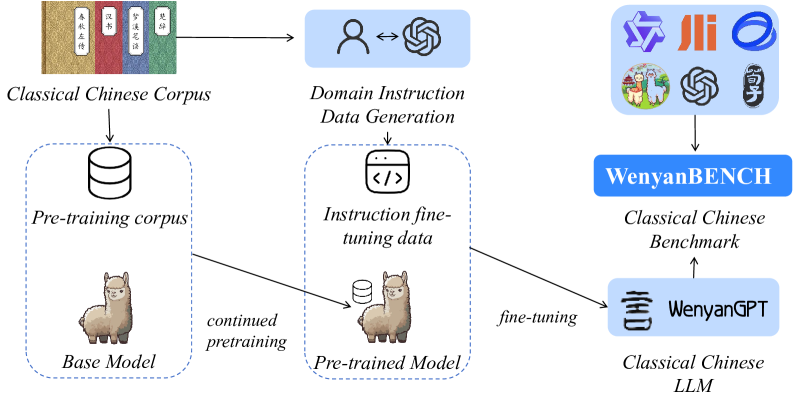
核心思路:论文的核心思路是利用大规模预训练语言模型(LLM)的强大能力,通过在LLaMA3-8B-Chinese模型上进行持续预训练和指令微调,使其适应古文的特点。这种方法旨在让模型学习到古文的语言规律和文化知识,从而提高其在古文任务上的性能。
技术框架:WenyanGPT的构建主要包含两个阶段:1) 持续预训练:在LLaMA3-8B-Chinese模型的基础上,使用大规模古文语料进行持续预训练,使模型进一步学习古文的语言特征。2) 指令微调:使用精心构建的古文指令数据集对模型进行微调,使其能够更好地理解和执行各种古文任务。同时,论文还构建了WenyanBENCH评估基准,用于全面评估模型在不同古文任务上的性能。
关键创新:该论文的关键创新在于针对古文处理任务,提出了一个基于LLM的定制化解决方案。通过持续预训练和指令微调,使模型能够更好地适应古文的特点,从而显著提高其在古文任务上的性能。此外,WenyanBENCH的构建也为古文处理领域的研究提供了一个重要的评估基准。
关键设计:论文中关于持续预训练和指令微调的具体数据规模、训练策略、损失函数等技术细节未知。但可以推测,指令微调阶段会设计针对古文特点的指令,例如古文翻译、古文理解、古文生成等。损失函数可能采用交叉熵损失,并根据古文任务的特点进行调整。
🖼️ 关键图片


📊 实验亮点
WenyanGPT在WenyanBENCH评估基准上取得了显著的性能提升,超越了当前先进的大语言模型。具体的性能数据和提升幅度在论文中未明确给出,但摘要强调了“显著优于”,表明WenyanGPT在古文处理能力上取得了重要突破。
🎯 应用场景
WenyanGPT可应用于古籍数字化、古文翻译、古文校对、古文创作等领域。它能够帮助研究人员更高效地分析和理解古文文献,促进中华优秀传统文化的传承和发展。未来,该模型有望成为古文研究和教育的重要工具。
📄 摘要(原文)
Classical Chinese, as the core carrier of Chinese culture, plays a crucial role in the inheritance and study of ancient literature. However, existing natural language processing models primarily optimize for Modern Chinese, resulting in inadequate performance on Classical Chinese. This paper presents a comprehensive solution for Classical Chinese language processing. By continuing pre-training and instruction fine-tuning on the LLaMA3-8B-Chinese model, we construct a large language model, WenyanGPT, which is specifically designed for Classical Chinese tasks. Additionally, we develop an evaluation benchmark dataset, WenyanBENCH. Experimental results on WenyanBENCH demonstrate that WenyanGPT significantly outperforms current advanced LLMs in various Classical Chinese tasks. We make the model's training data, instruction fine-tuning data\footnote, and evaluation benchmark dataset publicly available to promote further research and development in the field of Classical Chinese processing.