Learning to Plan Before Answering: Self-Teaching LLMs to Learn Abstract Plans for Problem Solving
作者: Jin Zhang, Flood Sung, Zhilin Yang, Yang Gao, Chongjie Zhang
分类: cs.CL, cs.AI
发布日期: 2025-04-28
💡 一句话要点
提出LEPA:通过自训练LLM学习抽象计划以解决问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自训练 抽象计划 问题解决 自然语言推理
📋 核心要点
- 现有LLM自训练方法缺乏对抽象元知识的捕捉,导致泛化能力受限。
- LEPA算法训练LLM在解决问题前先制定计划,作为抽象元知识指导问题求解。
- 实验表明,LEPA在多个自然语言推理基准测试中显著优于传统算法。
📝 摘要(中文)
本文提出了一种新的自训练算法,名为LEarning to Plan before Answering (LEPA),用于提升大型语言模型(LLM)的后训练效果。现有方法仅生成逐步的问题解决方案,未能捕捉到在类似问题中进行泛化所需的抽象元知识。LEPA借鉴认知科学,训练LLM在处理具体问题之前,先制定预期的计划,作为解决问题的抽象元知识。该方法不仅概述了解的生成路径,还能使LLM免受无关细节的干扰。在数据生成过程中,LEPA首先根据问题制定一个预期计划,然后生成与计划和问题相符的解决方案。LEPA通过自我反思来改进计划,旨在获得有助于产生正确解决方案的计划。在模型优化过程中,LLM被训练来预测改进后的计划和相应的解决方案。LEPA通过高效地提取和利用预期计划,在各种具有挑战性的自然语言推理基准测试中表现出优于传统算法的性能。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)自训练方法主要集中在生成逐步的问题解决方案,而忽略了抽象元知识的提取和利用。这种方法导致模型在面对相似问题时,难以进行有效的泛化。痛点在于模型缺乏高层次的规划能力,容易受到无关细节的干扰,从而影响问题解决的效率和准确性。
核心思路:LEPA的核心思路是让LLM在解决问题之前,先学习制定一个抽象的计划。这个计划可以看作是解决问题的“元知识”,它指导着LLM的推理过程,使其能够更好地应对复杂的问题。通过引入计划这一概念,LEPA旨在提高LLM的泛化能力和问题解决效率。
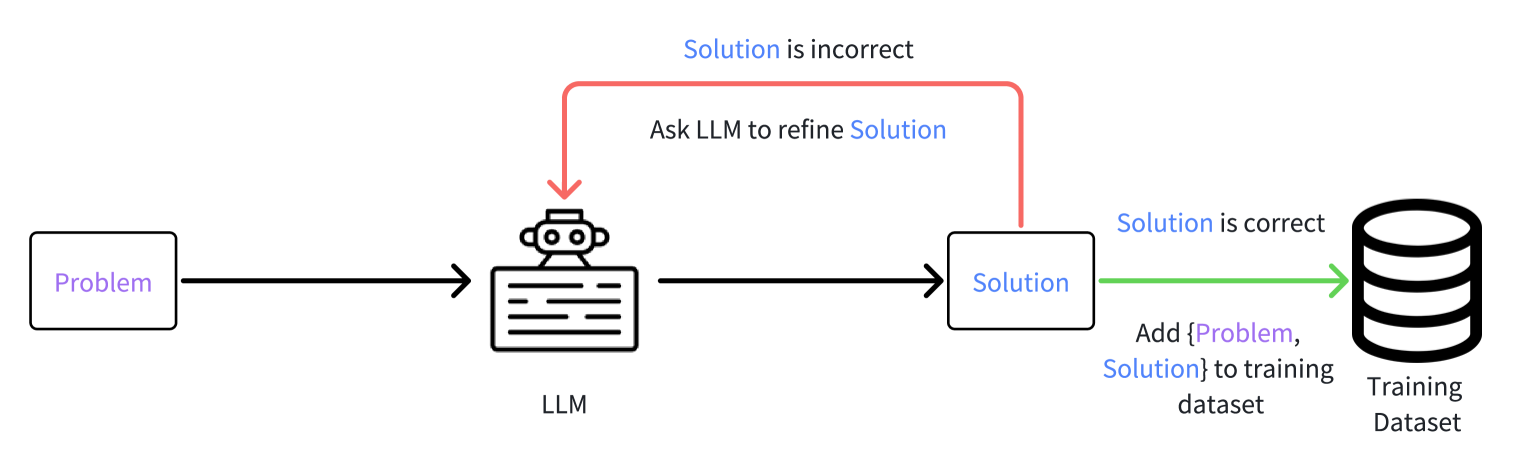
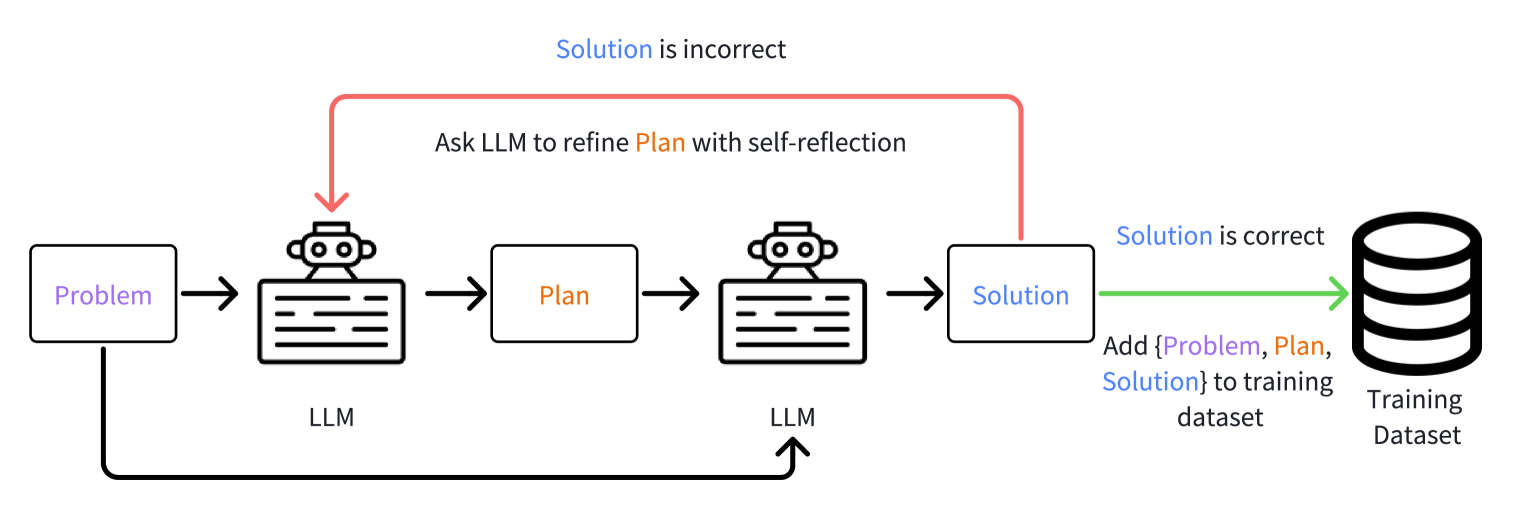
技术框架:LEPA的整体框架包含两个主要阶段:数据生成和模型优化。在数据生成阶段,LEPA首先根据给定的问题生成一个初步的预期计划。然后,基于该计划和问题,生成相应的解决方案。接着,LEPA通过自我反思机制来改进计划,使其更有效。在模型优化阶段,LLM被训练来同时预测改进后的计划和相应的解决方案。
关键创新:LEPA最重要的创新点在于引入了“计划”这一概念,并将其作为LLM解决问题的指导。与传统的自训练方法相比,LEPA不仅学习问题的解决方案,还学习解决问题的策略。这种策略性的学习方式使得LLM能够更好地泛化到新的问题上。
关键设计:LEPA的关键设计包括:1) 计划生成模块,负责根据问题生成初步的预期计划;2) 解决方案生成模块,负责基于计划和问题生成相应的解决方案;3) 自我反思模块,负责评估计划的有效性并进行改进;4) 损失函数,用于训练LLM同时预测计划和解决方案。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
LEPA在多个具有挑战性的自然语言推理基准测试中表现出显著的优越性。具体性能数据和对比基线在摘要中未提及,属于未知信息。但总体而言,LEPA通过学习抽象计划,有效提升了LLM的问题解决能力。
🎯 应用场景
LEPA具有广泛的应用前景,可用于提升LLM在自然语言推理、问答系统、代码生成等领域的性能。通过学习抽象计划,LLM可以更好地理解问题的本质,从而生成更准确、更可靠的答案。此外,LEPA还可以应用于教育领域,帮助学生学习问题解决的策略和方法。
📄 摘要(原文)
In the field of large language model (LLM) post-training, the effectiveness of utilizing synthetic data generated by the LLM itself has been well-presented. However, a key question remains unaddressed: what essential information should such self-generated data encapsulate? Existing approaches only produce step-by-step problem solutions, and fail to capture the abstract meta-knowledge necessary for generalization across similar problems. Drawing insights from cognitive science, where humans employ high-level abstraction to simplify complex problems before delving into specifics, we introduce a novel self-training algorithm: LEarning to Plan before Answering (LEPA). LEPA trains the LLM to formulate anticipatory plans, which serve as abstract meta-knowledge for problem-solving, before engaging with the intricacies of problems. This approach not only outlines the solution generation path but also shields the LLM from the distraction of irrelevant details. During data generation, LEPA first crafts an anticipatory plan based on the problem, and then generates a solution that aligns with both the plan and the problem. LEPA refines the plan through self-reflection, aiming to acquire plans that are instrumental in yielding correct solutions. During model optimization, the LLM is trained to predict both the refined plans and the corresponding solutions. By efficiently extracting and utilizing the anticipatory plans, LEPA demonstrates remarkable superiority over conventional algorithms on various challenging natural language reasoning benchmarks.