AutoJudge: Judge Decoding Without Manual Annotation
作者: Roman Garipov, Fedor Velikonivtsev, Ivan Ermakov, Ruslan Svirschevski, Vage Egiazarian, Max Ryabinin
分类: cs.CL, cs.LG
发布日期: 2025-04-28 (更新: 2025-11-20)
备注: Accepted at NeurIPS 2025
💡 一句话要点
AutoJudge:无需人工标注的LLM推断加速方法,提升解码效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大型语言模型 LLM推理加速 有损压缩 半贪婪搜索
📋 核心要点
- 现有LLM推断方法计算成本高昂,逐token匹配输出分布限制了加速潜力。
- AutoJudge通过识别并跳过对下游任务影响小的token,实现有损推测解码,从而加速LLM推断。
- 实验表明,AutoJudge在数学推理和编程任务上实现了显著加速,精度损失可控,无需人工标注。
📝 摘要(中文)
本文提出AutoJudge,一种通过任务特定的有损推测解码加速大型语言模型(LLM)推断的方法。它不逐token匹配原始模型的输出分布,而是识别哪些生成的token会影响响应的下游质量,从而放宽了分布匹配的保证,使得“不重要”的token可以更快地生成。该方法依赖于半贪婪搜索算法来测试目标模型和草稿模型之间的哪些不匹配应该被纠正以保持质量,以及哪些可以被跳过。然后,我们训练一个基于现有LLM嵌入的轻量级分类器,在推理时预测哪些不匹配的token可以被安全地接受,而不会损害最终答案的质量。我们在数学推理和编程基准上,使用多个草稿/目标模型对评估了AutoJudge的有效性,以较小的精度损失为代价实现了显著的加速。值得注意的是,在GSM8k上,使用Llama 3.1 70B目标模型,我们的方法实现了高达约2倍于推测解码的速度提升,而精度损失不超过1%。当应用于LiveCodeBench基准时,AutoJudge自动检测编程特定的重要token,在Pass@1下降2%的情况下,每个推测周期接受≥25个token。我们的方法不需要人工标注,并且易于与现代LLM推理框架集成。
🔬 方法详解
问题定义:大型语言模型(LLM)的推理速度是部署的关键瓶颈。传统的推测解码旨在加速LLM推理,但仍然需要逐token匹配原始模型的输出分布,这限制了其加速潜力。现有方法难以区分token的重要性,无法在保证质量的前提下跳过不重要的token,从而实现更大幅度的加速。
核心思路:AutoJudge的核心思想是识别并接受那些对最终输出质量影响不大的token,从而实现有损推测解码。它通过训练一个轻量级分类器来预测哪些token可以安全地跳过,从而在保证任务性能的前提下,显著提升推理速度。这种方法避免了对所有token进行精确匹配的需要,从而实现了更高效的推理。
技术框架:AutoJudge的整体框架包括以下几个主要阶段:1) 半贪婪搜索:使用半贪婪搜索算法来确定哪些token的不匹配可以被接受,哪些需要被纠正。2) 分类器训练:训练一个轻量级分类器,基于LLM的嵌入来预测哪些token可以安全地跳过。3) 推理阶段:在推理时,使用训练好的分类器来决定是否接受草稿模型生成的token。如果分类器预测该token可以接受,则直接跳过验证,从而加速推理过程。
关键创新:AutoJudge的关键创新在于其自动识别并接受“不重要”token的能力。与传统的推测解码方法不同,AutoJudge不需要逐token匹配原始模型的输出分布,而是通过学习哪些token对最终结果影响较小,从而实现有损推测解码。这种方法无需人工标注,并且可以自动适应不同的任务和模型。
关键设计:AutoJudge的关键设计包括:1) 半贪婪搜索算法:用于确定哪些token可以安全跳过。2) 轻量级分类器:基于LLM嵌入,预测token的重要性。3) 损失函数:用于训练分类器,目标是最大化推理速度,同时保证任务性能。分类器的具体结构和参数设置(例如,使用的嵌入维度、网络层数等)需要根据具体的任务和模型进行调整。
🖼️ 关键图片

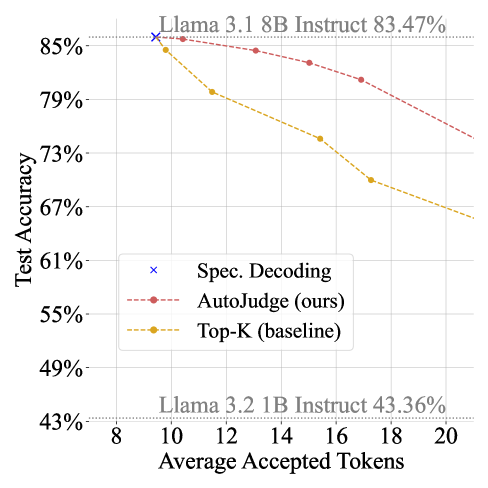
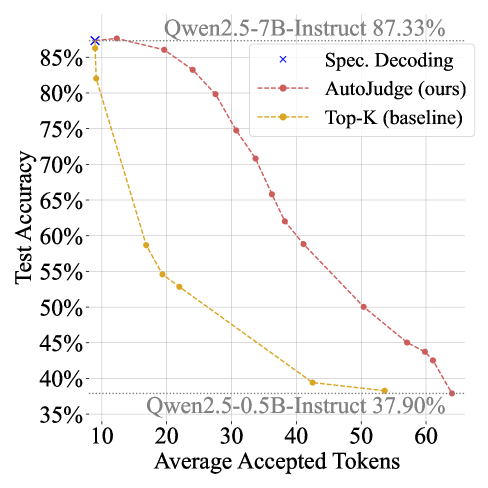
📊 实验亮点
AutoJudge在GSM8k数据集上,使用Llama 3.1 70B模型作为目标模型时,实现了高达2倍的加速,而精度损失仅为1%。在LiveCodeBench基准测试中,AutoJudge能够自动检测编程相关的关键token,并在Pass@1指标下降2%的情况下,每个推测周期接受超过25个token。
🎯 应用场景
AutoJudge可应用于各种需要加速LLM推理的场景,例如在线问答系统、代码生成、数学推理等。通过降低推理延迟,可以提升用户体验,并降低部署成本。该方法尤其适用于资源受限的设备,例如移动设备和边缘计算设备,可以使这些设备也能运行大型语言模型。
📄 摘要(原文)
We introduce AutoJudge, a method that accelerates large language model (LLM) inference with task-specific lossy speculative decoding. Instead of matching the original model output distribution token-by-token, we identify which of the generated tokens affect the downstream quality of the response, relaxing the distribution match guarantee so that the "unimportant" tokens can be generated faster. Our approach relies on a semi-greedy search algorithm to test which of the mismatches between target and draft models should be corrected to preserve quality and which ones may be skipped. We then train a lightweight classifier based on existing LLM embeddings to predict, at inference time, which mismatching tokens can be safely accepted without compromising the final answer quality. We evaluate the effectiveness of AutoJudge with multiple draft/target model pairs on mathematical reasoning and programming benchmarks, achieving significant speedups at the cost of a minor accuracy reduction. Notably, on GSM8k with the Llama 3.1 70B target model, our approach achieves up to $\approx2\times$ speedup over speculative decoding at the cost of $\le 1\%$ drop in accuracy. When applied to the LiveCodeBench benchmark, AutoJudge automatically detects programming-specific important tokens, accepting $\ge 25$ tokens per speculation cycle at $2\%$ drop in Pass@1. Our approach requires no human annotation and is easy to integrate with modern LLM inference frameworks.