TD-EVAL: Revisiting Task-Oriented Dialogue Evaluation by Combining Turn-Level Precision with Dialogue-Level Comparisons
作者: Emre Can Acikgoz, Carl Guo, Suvodip Dey, Akul Datta, Takyoung Kim, Gokhan Tur, Dilek Hakkani-Tür
分类: cs.CL, cs.AI
发布日期: 2025-04-28 (更新: 2025-07-16)
💡 一句话要点
TD-EVAL:结合Turn级精度与Dialogue级比较,重新审视面向任务型对话的评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 任务型对话系统 对话评估 Turn级别评估 Dialogue级别评估 大型语言模型 对话连贯性 知识一致性 策略合规性
📋 核心要点
- 现有TOD系统评估方法侧重于对话层面,忽略了Turn级别的关键中间错误,导致评估不全面。
- TD-EVAL框架结合Turn级细粒度分析和Dialogue级整体比较,更全面地评估TOD系统。
- 实验表明,TD-EVAL能有效识别传统指标遗漏的错误,并与人类判断有更好的一致性。
📝 摘要(中文)
大型语言模型(LLM)正在推动面向任务型对话(TOD)系统的变革,然而,评估这些系统的现有方法对于其日益增长的复杂性而言仍然不足。传统的自动指标虽然能有效评估早期的模块化系统,但它们仅关注对话层面,无法检测用户-代理交互过程中可能出现的关键中间错误。本文提出了TD-EVAL(Turn and Dialogue-level Evaluation),这是一个两步评估框架,它将细粒度的Turn级分析与整体的Dialogue级比较相结合。在Turn级别,我们沿着三个TOD特定的维度评估每个响应:对话连贯性、后端知识一致性和策略合规性。同时,我们设计了TOD Agent Arena,它使用成对比较来衡量Dialogue级别的质量。通过在MultiWOZ 2.4和τ-Bench上的实验,我们证明了TD-EVAL有效地识别了传统指标遗漏的对话错误。此外,TD-EVAL比传统和基于LLM的指标更好地与人类判断对齐。这些发现表明,TD-EVAL为TOD系统评估引入了一种新的范例,通过一个即插即用的框架,高效地评估Turn级别和系统级别,以供未来研究。
🔬 方法详解
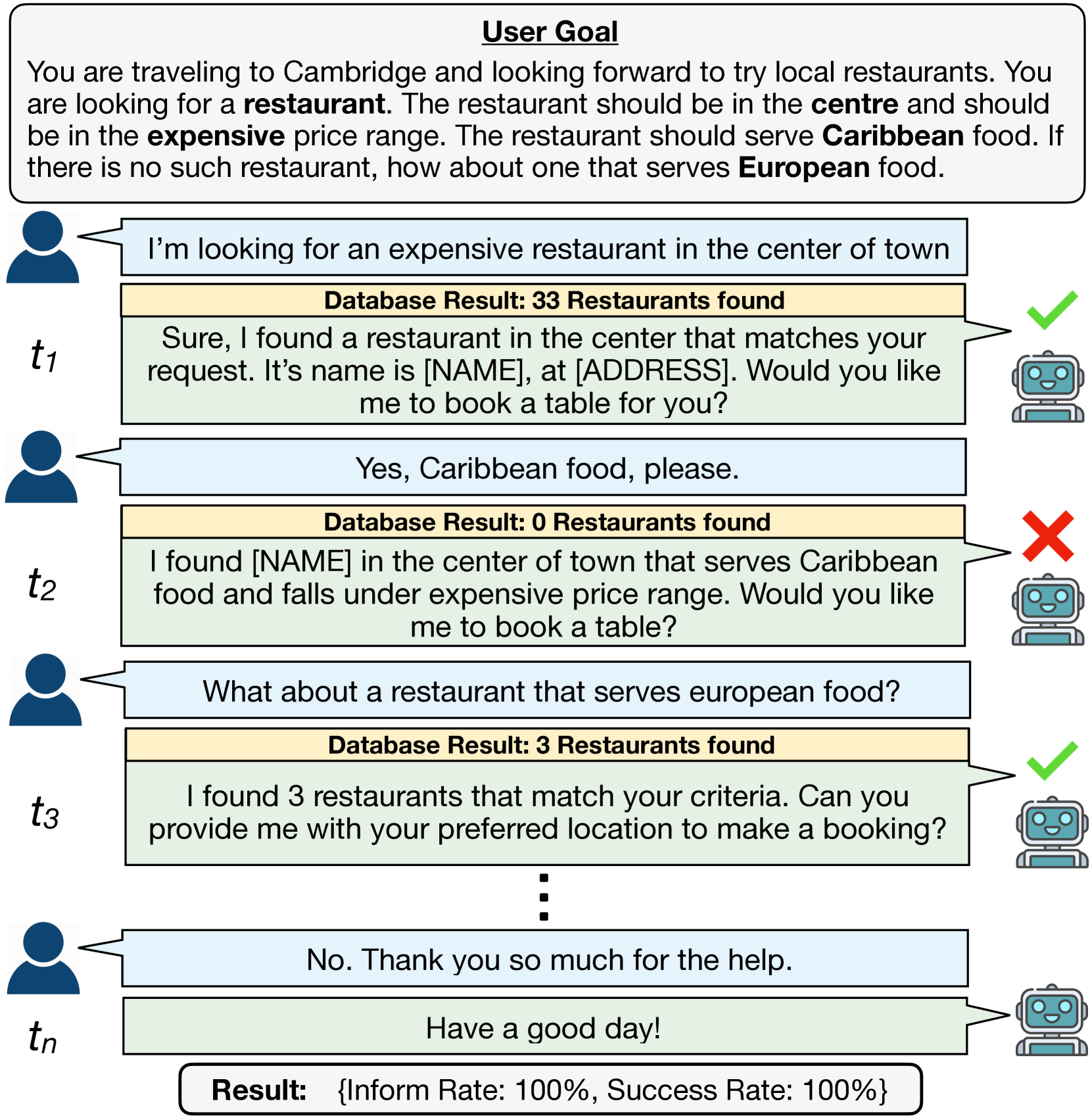
问题定义:现有面向任务型对话(TOD)系统的评估方法,特别是自动评估指标,主要关注对话级别的整体表现,而忽略了对话过程中每个Turn的质量。这种评估方式无法捕捉到对话过程中出现的中间错误,例如对话不连贯、知识不一致或策略不合规等问题。这些Turn级别的错误累积起来会严重影响对话的最终质量,因此需要一种更细粒度的评估方法。
核心思路:TD-EVAL的核心思路是将Turn级别的评估与Dialogue级别的评估相结合,从而实现对TOD系统更全面、更准确的评估。通过Turn级别的评估,可以检测到对话过程中的细微错误,而Dialogue级别的评估则可以衡量对话的整体质量。这种结合的方式既能保证评估的准确性,又能提高评估的效率。
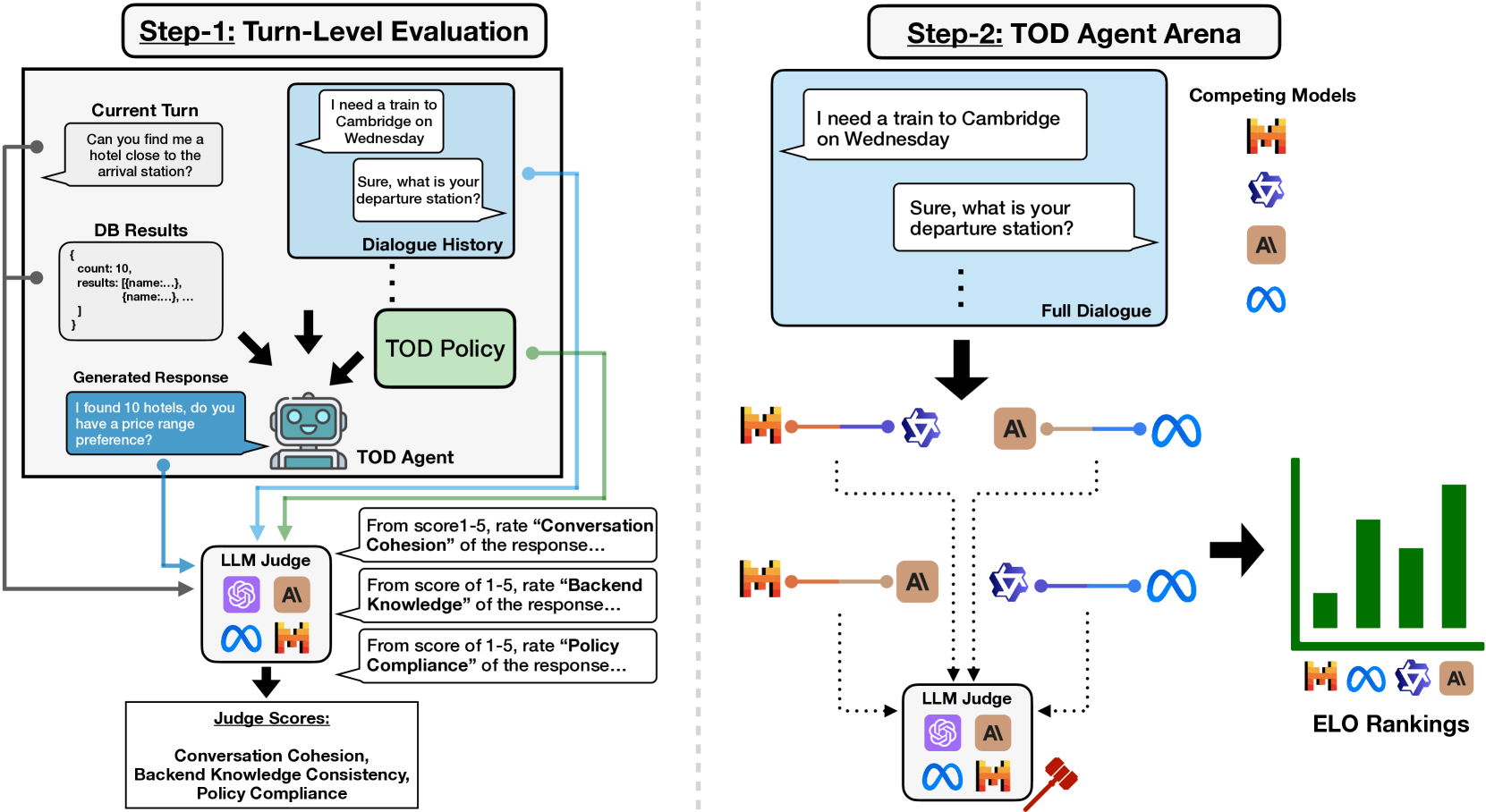
技术框架:TD-EVAL框架包含两个主要模块:Turn级别评估和Dialogue级别评估。Turn级别评估主要关注三个维度:对话连贯性、后端知识一致性和策略合规性。对于每个Turn,TD-EVAL会评估其在这三个维度上的表现。Dialogue级别评估则采用成对比较的方式,通过TOD Agent Arena来衡量对话的整体质量。TOD Agent Arena会比较两个TOD系统生成的对话,并判断哪个对话质量更高。
关键创新:TD-EVAL的关键创新在于其将Turn级别评估与Dialogue级别评估相结合的评估框架。传统的评估方法要么只关注Dialogue级别,要么只关注Turn级别,而TD-EVAL则将两者结合起来,从而实现了更全面、更准确的评估。此外,TD-EVAL还引入了TOD Agent Arena,通过成对比较的方式来衡量Dialogue级别的质量,这种方式更符合人类的直觉。
关键设计:在Turn级别评估中,对话连贯性、后端知识一致性和策略合规性三个维度的具体评估方法未知,论文中可能使用了预训练语言模型或规则来进行判断。在Dialogue级别评估中,TOD Agent Arena的具体实现方式未知,可能使用了人工评估或自动评估模型来进行成对比较。损失函数和网络结构等技术细节在论文中没有明确说明。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TD-EVAL能够有效识别传统指标遗漏的对话错误,并且与人类判断具有更好的一致性。在MultiWOZ 2.4和τ-Bench数据集上,TD-EVAL的表现优于传统的自动评估指标和基于LLM的评估指标。具体的性能提升数据未知,但论文强调了TD-EVAL在错误识别和与人类判断对齐方面的优势。
🎯 应用场景
TD-EVAL可应用于面向任务型对话系统的开发和评估。开发者可以使用TD-EVAL来识别系统中的薄弱环节,并进行改进。研究人员可以使用TD-EVAL来比较不同TOD系统的性能,并推动该领域的发展。该框架具有即插即用的特性,方便集成到现有的开发流程中,加速TOD系统的迭代和优化。
📄 摘要(原文)
Task-oriented dialogue (TOD) systems are experiencing a revolution driven by Large Language Models (LLMs), yet the evaluation methodologies for these systems remain insufficient for their growing sophistication. While traditional automatic metrics effectively assessed earlier modular systems, they focus solely on the dialogue level and cannot detect critical intermediate errors that can arise during user-agent interactions. In this paper, we introduce TD-EVAL (Turn and Dialogue-level Evaluation), a two-step evaluation framework that unifies fine-grained turn-level analysis with holistic dialogue-level comparisons. At turn level, we evaluate each response along three TOD-specific dimensions: conversation cohesion, backend knowledge consistency, and policy compliance. Meanwhile, we design TOD Agent Arena that uses pairwise comparisons to provide a measure of dialogue-level quality. Through experiments on MultiWOZ 2.4 and τ-Bench, we demonstrate that TD-EVAL effectively identifies the conversational errors that conventional metrics miss. Furthermore, TD-EVAL exhibits better alignment with human judgments than traditional and LLM-based metrics. These findings demonstrate that TD-EVAL introduces a new paradigm for TOD system evaluation, efficiently assessing both turn and system levels with a plug-and-play framework for future research.