semi-PD: Towards Efficient LLM Serving via Phase-Wise Disaggregated Computation and Unified Storage
作者: Ke Hong, Lufang Chen, Zhong Wang, Xiuhong Li, Qiuli Mao, Jianping Ma, Chao Xiong, Guanyu Wu, Buhe Han, Guohao Dai, Yun Liang, Yu Wang
分类: cs.CL, cs.DC, cs.LG
发布日期: 2025-04-28
备注: 18 pages, 16 figures
💡 一句话要点
semi-PD:面向高效LLM服务的阶段解耦计算与统一存储
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型服务 解耦计算 统一存储 KV缓存管理 资源调度
📋 核心要点
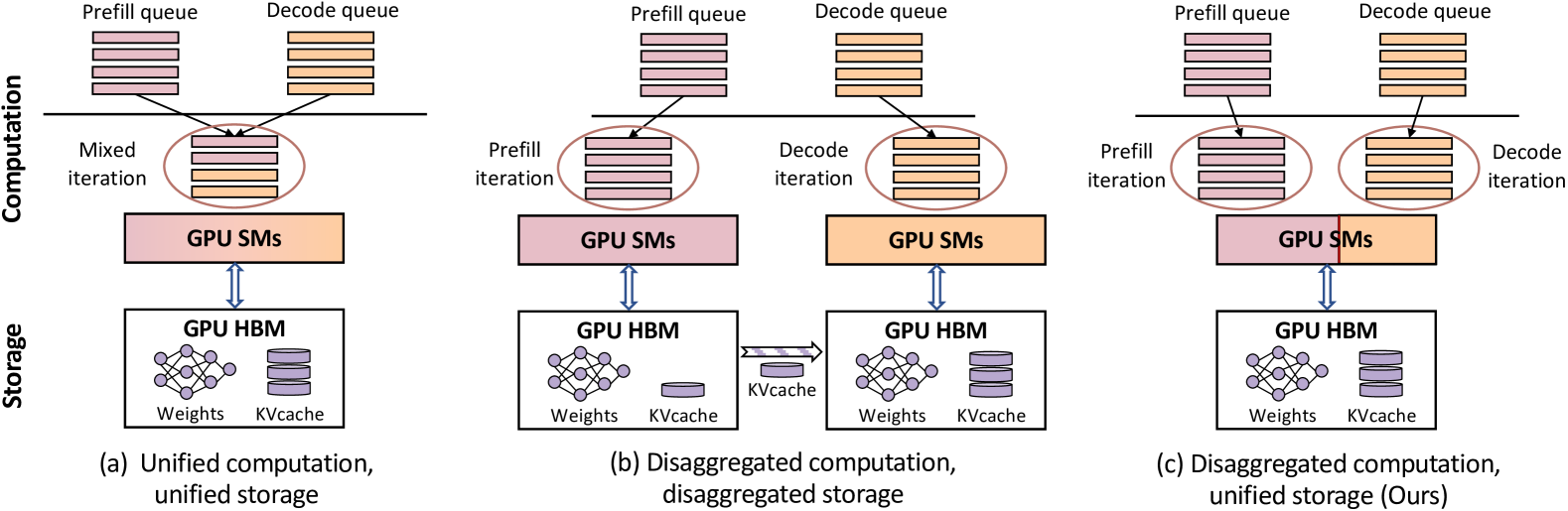
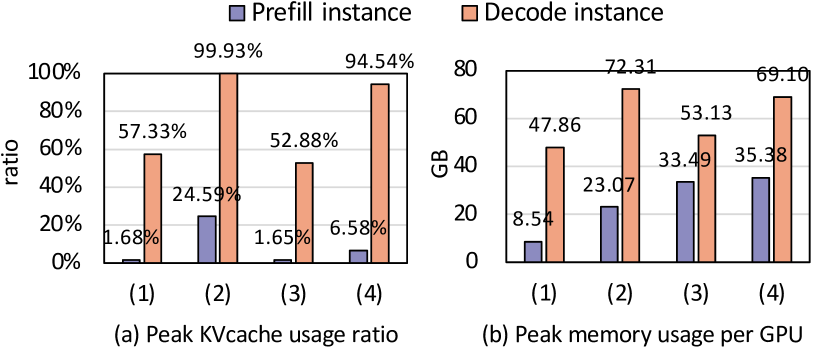
- 现有LLM服务系统在统一和解耦架构间面临权衡,解耦架构虽能避免延迟干扰,但引入了存储冗余和KV缓存传输开销。
- Semi-PD的核心思想是解耦计算与统一存储,通过计算资源控制器和统一内存管理器实现异步计算和内存访问。
- 实验结果表明,Semi-PD在高请求率下能显著降低延迟并提升请求服务数量,尤其在DeepSeek和Llama系列模型上。
📝 摘要(中文)
现有的大语言模型(LLM)服务系统分为两类:1)统一系统,其中预填充(prefill)阶段和解码(decode)阶段位于同一GPU上,共享统一的计算资源和存储;2)解耦系统,将两个阶段解耦到不同的GPU上。解耦系统的设计解决了统一系统中的延迟干扰和复杂的调度问题,但导致了存储挑战,包括:1)两个阶段的权重重复,阻碍了灵活部署;2)两个阶段之间的KV缓存传输开销;3)存储不平衡,导致GPU容量的大量浪费;4)由于迁移KV缓存的困难,导致次优的资源调整。这种存储效率低下在高请求率下导致较差的服务性能。本文提出了一种新的LLM服务系统semi-PD,其特点是解耦计算和统一存储。在semi-PD中,我们引入了一个计算资源控制器,以在流式多处理器(SM)级别实现解耦计算,并引入了一个统一的内存管理器来管理来自两个阶段的异步内存访问。semi-PD在两个阶段之间具有低开销的资源调整机制,以及一个服务级别目标(SLO)感知的动态分区算法来优化SLO的实现。与最先进的系统相比,semi-PD在更高的请求率下保持更低的延迟,在DeepSeek系列模型上将每个请求的平均端到端延迟降低了1.27-2.58倍,并在Llama系列模型上提供了1.55-1.72倍的请求服务,同时满足延迟约束。
🔬 方法详解
问题定义:现有LLM服务系统,特别是解耦系统,存在存储效率低下的问题。具体表现为:权重重复存储导致部署不灵活,KV缓存需要在不同阶段间传输产生额外开销,存储空间分配不平衡造成浪费,以及KV缓存迁移困难导致资源调整不佳。这些问题在高并发场景下会严重影响服务性能。
核心思路:Semi-PD的核心思路是将计算解耦和存储统一。解耦计算允许预填充和解码阶段异步执行,避免相互干扰;统一存储则避免了权重冗余和KV缓存传输开销,提高了存储利用率和资源调整的灵活性。这种设计旨在结合解耦计算的优势,同时克服解耦系统在存储方面的不足。
技术框架:Semi-PD包含两个主要组件:计算资源控制器和统一内存管理器。计算资源控制器负责在流式多处理器(SM)级别实现计算解耦,允许预填充和解码阶段异步使用计算资源。统一内存管理器负责管理来自两个阶段的异步内存访问,提供统一的存储视图,避免数据冗余和传输开销。此外,系统还包含一个低开销的资源调整机制和一个SLO感知的动态分区算法,用于优化服务质量。
关键创新:Semi-PD的关键创新在于将解耦计算和统一存储结合起来。与传统的统一系统相比,它避免了延迟干扰;与传统的解耦系统相比,它解决了存储效率低下的问题。通过计算资源控制器和统一内存管理器,Semi-PD实现了高效的资源管理和调度,从而提高了整体服务性能。
关键设计:Semi-PD的关键设计包括:1) 计算资源控制器如何将SM资源动态分配给预填充和解码阶段;2) 统一内存管理器如何管理KV缓存的存储和访问,避免数据冗余和传输;3) 低开销资源调整机制如何快速响应负载变化,调整资源分配;4) SLO感知的动态分区算法如何根据服务级别目标优化资源分配,保证服务质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Semi-PD在DeepSeek系列模型上将平均端到端延迟降低了1.27-2.58倍,并在Llama系列模型上提供了1.55-1.72倍的请求服务,同时满足延迟约束。这些结果表明,Semi-PD在提高LLM服务性能方面具有显著优势,尤其是在高请求率的场景下。
🎯 应用场景
Semi-PD适用于对延迟敏感且需要高吞吐量的大语言模型服务场景,例如在线对话机器人、智能客服、实时翻译等。通过提高资源利用率和降低延迟,Semi-PD能够降低服务成本,提升用户体验,并支持更大规模的并发请求。未来,该技术有望应用于边缘计算设备,实现低延迟的本地化LLM服务。
📄 摘要(原文)
Existing large language model (LLM) serving systems fall into two categories: 1) a unified system where prefill phase and decode phase are co-located on the same GPU, sharing the unified computational resource and storage, and 2) a disaggregated system where the two phases are disaggregated to different GPUs. The design of the disaggregated system addresses the latency interference and sophisticated scheduling issues in the unified system but leads to storage challenges including 1) replicated weights for both phases that prevent flexible deployment, 2) KV cache transfer overhead between the two phases, 3) storage imbalance that causes substantial wasted space of the GPU capacity, and 4) suboptimal resource adjustment arising from the difficulties in migrating KV cache. Such storage inefficiency delivers poor serving performance under high request rates. In this paper, we identify that the advantage of the disaggregated system lies in the disaggregated computation, i.e., partitioning the computational resource to enable the asynchronous computation of two phases. Thus, we propose a novel LLM serving system, semi-PD, characterized by disaggregated computation and unified storage. In semi-PD, we introduce a computation resource controller to achieve disaggregated computation at the streaming multi-processor (SM) level, and a unified memory manager to manage the asynchronous memory access from both phases. semi-PD has a low-overhead resource adjustment mechanism between the two phases, and a service-level objective (SLO) aware dynamic partitioning algorithm to optimize the SLO attainment. Compared to state-of-the-art systems, semi-PD maintains lower latency at higher request rates, reducing the average end-to-end latency per request by 1.27-2.58x on DeepSeek series models, and serves 1.55-1.72x more requests adhering to latency constraints on Llama series models.