Can a Crow Hatch a Falcon? Lineage Matters in Predicting Large Language Model Performance
作者: Takuya Tamura, Taro Yano, Masafumi Enomoto, Masafumi Oyamada
分类: cs.CL
发布日期: 2025-04-28 (更新: 2025-08-08)
💡 一句话要点
提出 lineage-regularized 矩阵分解框架,利用模型谱系关系预测大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 性能预测 矩阵分解 谱系关系 图拉普拉斯正则化 冷启动问题 模型选择
📋 核心要点
- 现有方法在预测LLM性能时,忽略了模型之间的谱系关系,导致预测精度受限。
- 论文提出Lineage-Regularized Matrix Factorization (LRMF)框架,利用图拉普拉斯正则化器编码模型谱系。
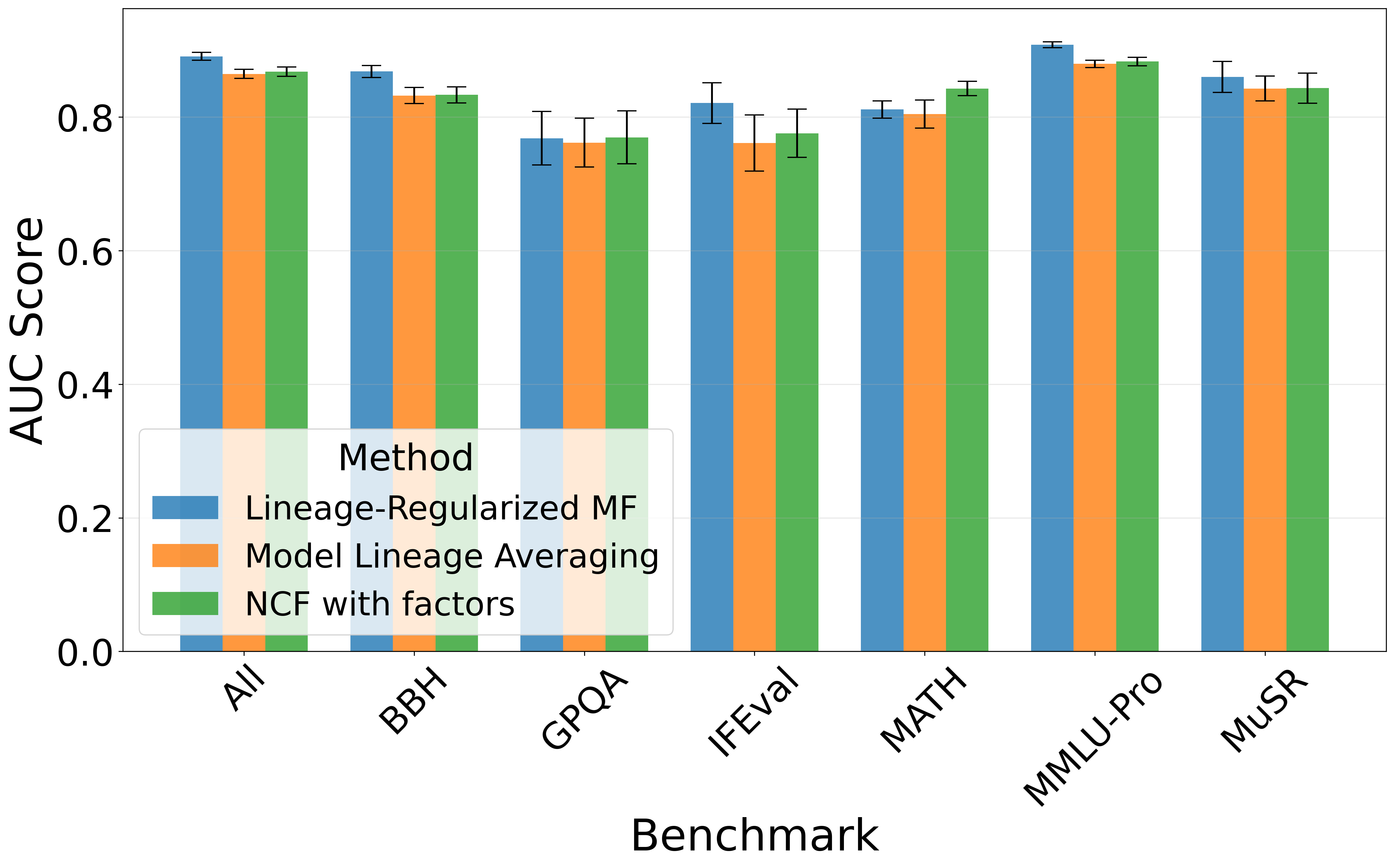
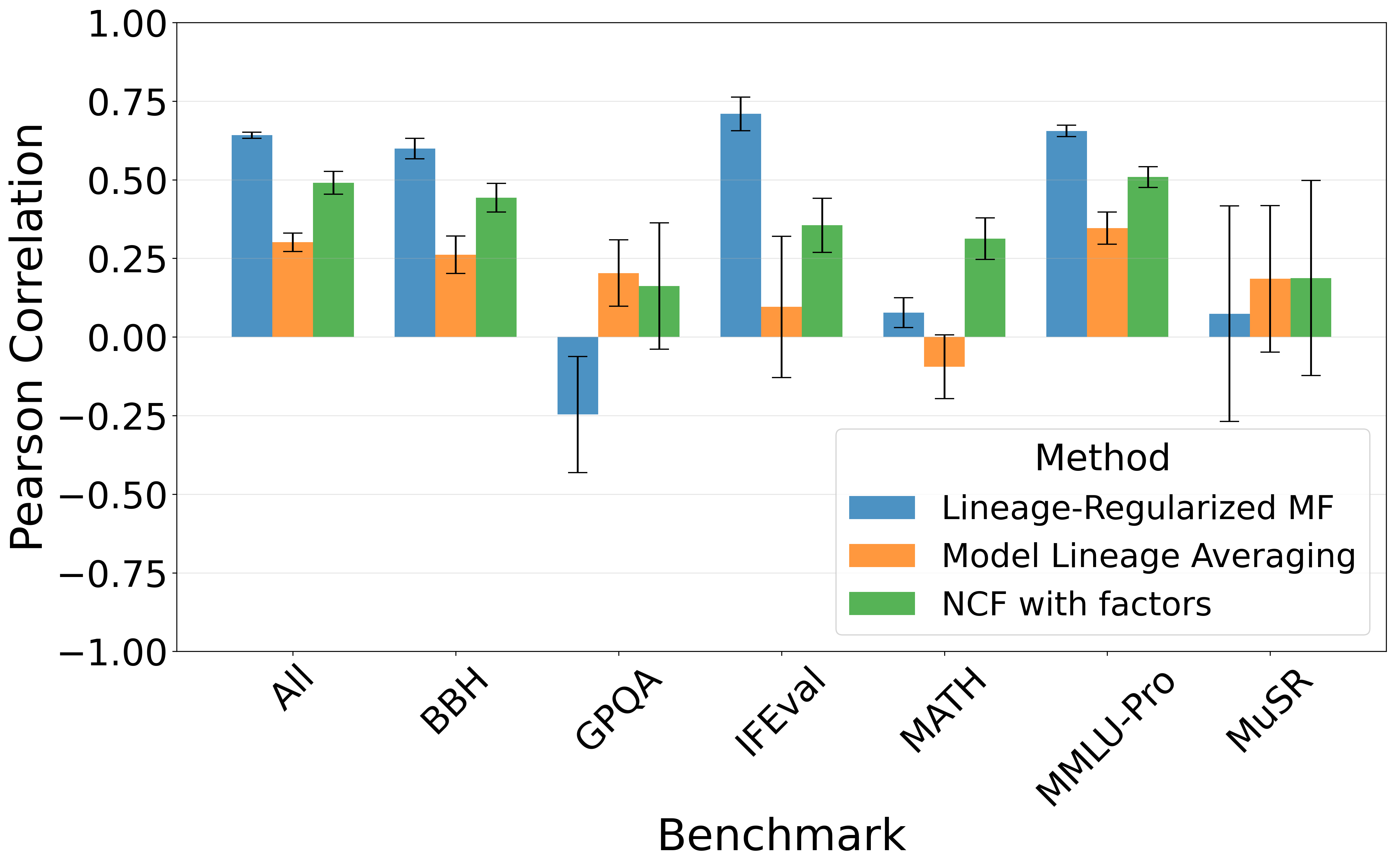
- 实验结果表明,LRMF在性能预测方面优于传统方法,Pearson相关系数提升0.15-0.30,并有效解决了冷启动问题。
📝 摘要(中文)
在对大型语言模型(LLM)进行大规模微调或合并之前,准确预测其性能可以显著减少计算成本和开发时间。虽然先前的缩放定律等方法考虑了参数大小或训练token等全局因素,但它们通常忽略了显式的谱系关系,即哪些模型是从哪些父模型派生或合并而来。本文提出了一种新的谱系正则化矩阵分解(LRMF)框架,该框架通过图拉普拉斯正则化器对LLM之间的祖先关系进行编码。通过利用多跳父子连接,LRMF在实例级别和基准级别性能预测方面均优于传统的矩阵分解和协同过滤方法。我们的大规模研究包括2,934个公开的Hugging Face模型和6个主要基准测试中的21,000多个实例,结果表明,与基线方法相比,引入谱系约束可使Pearson相关系数提高0.15-0.30。此外,LRMF有效地解决了冷启动问题,即使在数据最少的情况下,也能为新派生或合并的模型提供准确的估计。因此,这种谱系引导策略为现代LLM开发中超参数调整、数据选择和模型组合提供了一种资源高效的方式。
🔬 方法详解
问题定义:论文旨在解决在LLM微调或合并前,准确预测其性能的问题。现有方法如缩放定律,主要关注模型大小和训练数据量等全局因素,忽略了模型之间的谱系关系,导致预测精度不足,尤其是在新模型或数据稀疏的情况下,即冷启动问题。
核心思路:核心思路是利用LLM之间的谱系关系,即模型之间的父子关系,来提升性能预测的准确性。通过将谱系关系编码到模型中,可以利用父模型的性能信息来辅助预测子模型的性能,从而提高预测精度,尤其是在数据稀疏的情况下。
技术框架:LRMF框架的核心是矩阵分解,将模型和任务的性能表示为一个矩阵,然后通过矩阵分解来预测缺失的性能值。关键在于引入了图拉普拉斯正则化器,该正则化器利用LLM的谱系图来约束矩阵分解过程。谱系图中的节点代表LLM,边代表父子关系。图拉普拉斯正则化器鼓励具有相似谱系关系的LLM具有相似的性能。
关键创新:关键创新在于将LLM的谱系关系显式地编码到性能预测模型中。与传统的矩阵分解方法相比,LRMF考虑了模型之间的继承关系,从而能够更准确地预测模型的性能。此外,LRMF通过图拉普拉斯正则化器,能够有效地利用多跳父子连接,从而进一步提高预测精度。
关键设计:LRMF的目标函数包含三个部分:矩阵分解损失、谱系正则化损失和L2正则化损失。矩阵分解损失衡量预测性能与实际性能之间的差异。谱系正则化损失鼓励具有相似谱系关系的LLM具有相似的性能。L2正则化损失用于防止过拟合。图拉普拉斯矩阵的构建基于LLM的谱系图,边的权重可以根据父子关系的强度进行调整。模型的训练采用梯度下降法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LRMF在2934个Hugging Face模型和6个主要基准测试的21000多个实例上, consistently 优于传统的矩阵分解和协同过滤方法。引入谱系约束后,Pearson相关系数提高了0.15-0.30。LRMF还能够有效解决冷启动问题,即使在数据稀疏的情况下,也能准确预测新模型的性能。
🎯 应用场景
该研究成果可应用于LLM的开发和部署过程中,例如,在选择合适的预训练模型、调整超参数、选择训练数据以及进行模型合并时,可以利用LRMF框架预测模型的性能,从而降低计算成本和开发时间。此外,该方法还可以用于评估新模型的潜在价值,指导模型开发的优先级。
📄 摘要(原文)
Accurately forecasting the performance of Large Language Models (LLMs) before extensive fine-tuning or merging can substantially reduce both computational expense and development time. Although prior approaches like scaling laws account for global factors such as parameter size or training tokens, they often overlook explicit lineage relationships-i.e., which models are derived or merged from which parents. In this work, we propose a novel Lineage-Regularized Matrix Factorization (LRMF) framework that encodes ancestral ties among LLMs via a graph Laplacian regularizer. By leveraging multi-hop parent-child connections, LRMF consistently outperforms conventional matrix factorization and collaborative filtering methods in both instance-level and benchmark-level performance prediction. Our large-scale study includes 2,934 publicly available Hugging Face models and 21,000+ instances across 6 major benchmarks, showing that the introduction of lineage constraints yields up to 0.15-0.30 higher Pearson correlation coefficients with actual performance compared to baseline methods. Moreover, LRMF effectively addresses the cold-start problem, providing accurate estimates for newly derived or merged models even with minimal data. This lineage-guided strategy thus offers a resource-efficient way to inform hyperparameter tuning, data selection, and model combination in modern LLM development.