Annif at SemEval-2025 Task 5: Traditional XMTC augmented by LLMs
作者: Osma Suominen, Juho Inkinen, Mona Lehtinen
分类: cs.CL, cs.AI, cs.DL, cs.IR, cs.LG
发布日期: 2025-04-28 (更新: 2025-08-21)
备注: 6 pages, 4 figures, published at SemEval-2025 workshop Task 5: LLMs4Subjects: https://aclanthology.org/2025.semeval-1.315/
期刊: Proceedings of the 19th International Workshop on Semantic Evaluation (SemEval-2025), 2424--2431
💡 一句话要点
Annif结合传统XMTC与LLM,提升多语言环境下主题标引的准确性和效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主题标引 多语言处理 大型语言模型 数据增强 XML多标签分类
📋 核心要点
- 现有主题标引方法在处理多语言数据时面临准确性和效率的挑战,尤其是在词汇资源有限的情况下。
- 该论文提出了一种结合传统XMTC算法与LLM的方法,利用LLM进行翻译和合成数据生成,从而增强模型性能。
- 实验结果表明,该方法在SemEval-2025 Task 5中取得了优异成绩,证明了其在多语言主题标引方面的有效性。
📝 摘要(中文)
本文介绍了Annif系统在SemEval-2025 Task 5(LLMs4Subjects)中的应用,该任务侧重于使用大型语言模型(LLM)进行主题标引。任务要求使用GND主题词表为来自双语TIBKAT数据库的书目记录创建主题预测。我们的方法结合了Annif工具包中实现的传统自然语言处理和机器学习技术,以及基于LLM的创新方法,用于翻译和合成数据生成,并融合来自单语模型的预测。在定量评估中,该系统在所有主题类别中排名第一,在tib-core-subjects类别中排名第二,在定性评估中排名第四。这些发现证明了将传统XMTC算法与现代LLM技术相结合以提高多语言环境中主题标引的准确性和效率的潜力。
🔬 方法详解
问题定义:论文旨在解决多语言环境下书目记录的主题标引问题。现有方法在处理不同语言时,由于语言差异和资源限制,往往难以保证标引的准确性和效率。特别是对于低资源语言,缺乏足够的训练数据和专业知识库,使得传统方法难以达到理想效果。
核心思路:论文的核心思路是将传统的XMTC(XML多标签分类)算法与现代大型语言模型(LLM)相结合。利用LLM强大的语言理解和生成能力,进行数据增强和跨语言知识迁移,从而弥补传统方法在多语言环境下的不足。通过融合传统方法和LLM的优势,提升主题标引的整体性能。
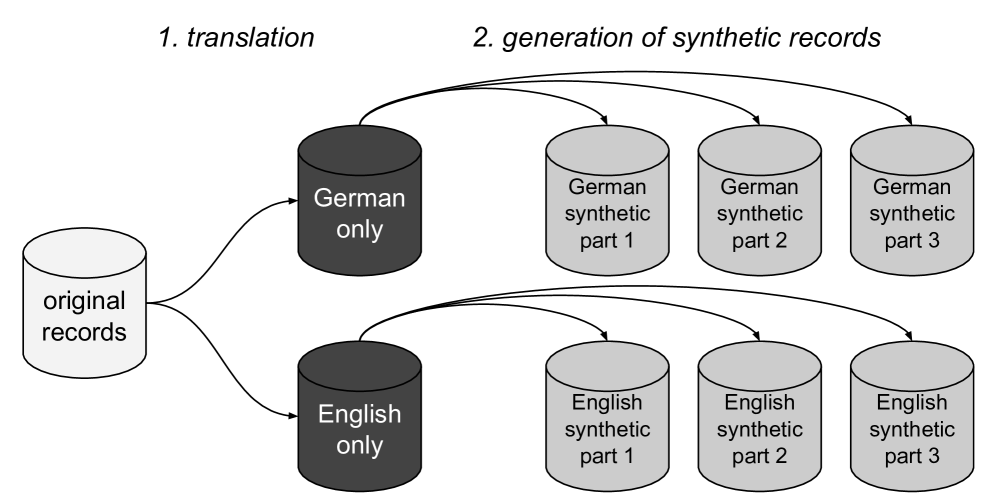
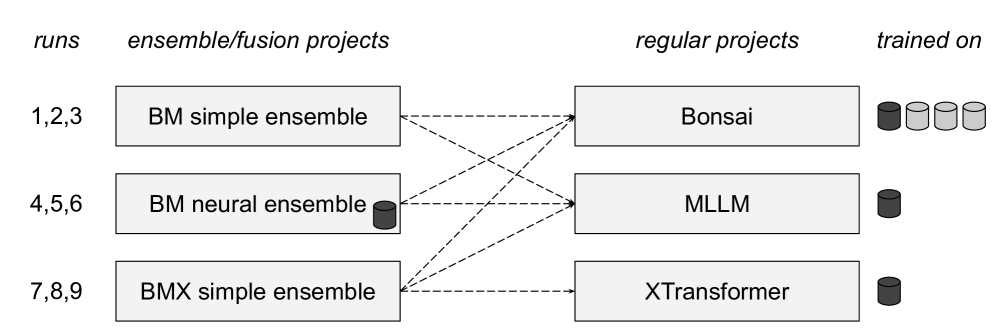
技术框架:整体框架包括以下几个主要模块:1) 数据预处理:对TIBKAT数据库中的书目记录进行清洗和格式化。2) LLM辅助:利用LLM进行翻译,将数据转换成统一的语言,并生成合成数据,扩充训练集。3) Annif模型训练:使用Annif工具包,基于传统机器学习算法(如TF-IDF、FastText)训练单语主题标引模型。4) 模型融合:将来自不同单语模型的预测结果进行融合,得到最终的主题预测结果。
关键创新:最重要的技术创新点在于将LLM应用于主题标引任务的数据增强和跨语言知识迁移。传统方法依赖于人工标注数据,成本高昂且难以扩展到多种语言。而利用LLM可以自动生成大量合成数据,并进行跨语言翻译,从而有效缓解数据稀缺问题。此外,通过模型融合,可以充分利用不同语言模型的优势,提升整体性能。
关键设计:在LLM辅助模块,使用了预训练的语言模型进行翻译和数据生成。具体参数设置未知。在Annif模型训练模块,使用了TF-IDF和FastText等特征提取方法,并采用了多标签分类算法。模型融合阶段,采用了加权平均等方法,对不同模型的预测结果进行加权融合。具体的权重参数设置未知。
🖼️ 关键图片
📊 实验亮点
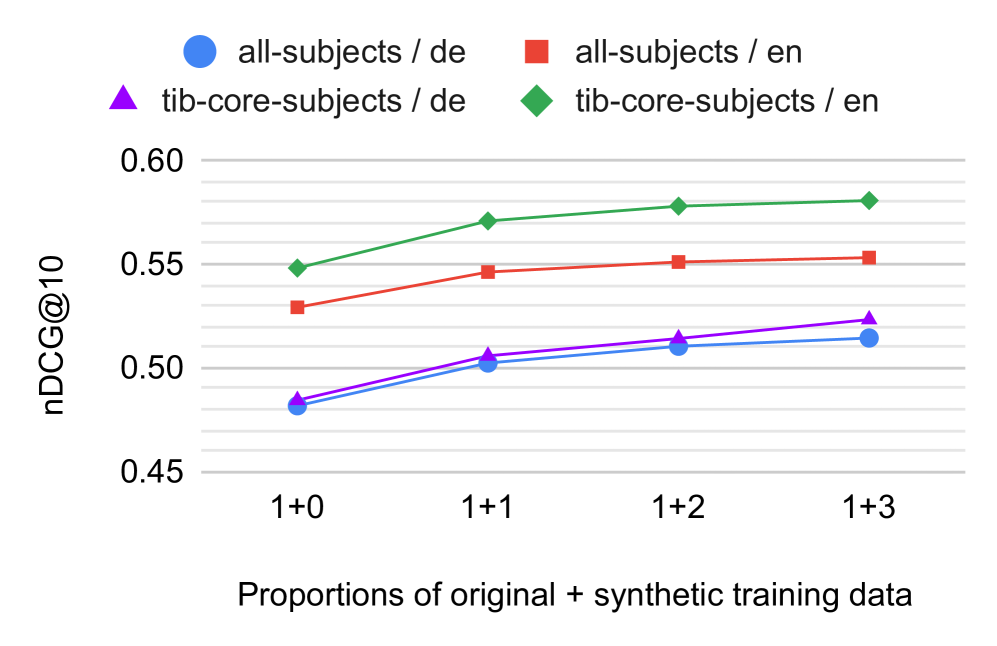
该系统在SemEval-2025 Task 5的定量评估中表现出色,在所有主题类别中排名第一,在tib-core-subjects类别中排名第二。定性评估中排名第四。这些结果表明,结合传统XMTC算法与LLM能够显著提升多语言主题标引的性能。具体的性能提升幅度未知,需要参考SemEval-2025 Task 5的官方报告。
🎯 应用场景
该研究成果可广泛应用于图书馆、档案馆等信息机构,用于提升书目数据的自动标引效率和准确性。通过结合传统方法和LLM,可以有效处理多语言数据,降低人工标引成本,提高信息检索的效率。未来,该方法有望应用于更广泛的文本分类和信息检索领域,例如新闻分类、专利检索等。
📄 摘要(原文)
This paper presents the Annif system in SemEval-2025 Task 5 (LLMs4Subjects), which focussed on subject indexing using large language models (LLMs). The task required creating subject predictions for bibliographic records from the bilingual TIBKAT database using the GND subject vocabulary. Our approach combines traditional natural language processing and machine learning techniques implemented in the Annif toolkit with innovative LLM-based methods for translation and synthetic data generation, and merging predictions from monolingual models. The system ranked first in the all-subjects category and second in the tib-core-subjects category in the quantitative evaluation, and fourth in qualitative evaluations. These findings demonstrate the potential of combining traditional XMTC algorithms with modern LLM techniques to improve the accuracy and efficiency of subject indexing in multilingual contexts.