APE-Bench I: Towards File-level Automated Proof Engineering of Formal Math Libraries
作者: Huajian Xin, Luming Li, Xiaoran Jin, Jacques Fleuriot, Wenda Li
分类: cs.CL
发布日期: 2025-04-27 (更新: 2025-05-22)
💡 一句话要点
提出APE-Bench I基准,用于评估LLM在形式化数学库文件级自动化证明工程中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动化证明工程 形式化数学库 大型语言模型 基准测试 定理证明
📋 核心要点
- 现有形式化定理证明基准缺乏对真实世界形式化数学库工程实践的覆盖,无法有效评估LLM在复杂证明任务中的能力。
- 论文提出自动化证明工程(APE)范式,利用LLM自动化证明工程任务,并构建了基于Mathlib4的现实基准APE-Bench I。
- 实验结果表明,现有LLM在局部编辑任务上表现良好,但在处理复杂证明工程任务时性能显著下降,揭示了现有方法的局限性。
📝 摘要(中文)
大型语言模型(LLMs)在形式化定理证明方面展现出潜力,但现有基准测试仅限于孤立的静态证明任务,无法捕捉真实世界形式化数学库中迭代、工程密集型的工作流程。受软件工程领域类似进展的启发,我们引入了自动化证明工程(APE)范式,旨在利用LLMs自动化特征添加、证明重构和错误修复等证明工程任务。为了促进这方面的研究,我们提出了APE-Bench I,这是第一个基于Mathlib4真实提交历史构建的现实基准,包含以自然语言描述的各种文件级任务,并通过Lean编译器和LLM-as-a-Judge的混合方法进行验证。我们进一步开发了Eleanstic,这是一个可扩展的并行验证基础设施,针对Mathlib多个版本的证明检查进行了优化。最先进的LLMs的实验结果表明,它们在局部编辑方面表现出色,但在处理复杂的证明工程方面性能显著下降。这项工作为开发证明工程中的智能体工作流程奠定了基础,未来的基准测试将针对多文件协调、项目规模验证以及能够规划、编辑和修复形式化库的自主智能体。
🔬 方法详解
问题定义:论文旨在解决现有形式化定理证明基准无法有效评估LLM在真实世界形式化数学库工程实践中能力的问题。现有基准通常是孤立的、静态的证明任务,缺乏对迭代、工程密集型工作流程的模拟,无法反映实际的证明工程挑战。
核心思路:论文的核心思路是将软件工程中的自动化思想引入到形式化证明领域,提出自动化证明工程(APE)范式。通过构建一个基于真实形式化数学库(Mathlib4)提交历史的基准测试,来评估LLM在特征添加、证明重构和错误修复等实际证明工程任务中的能力。
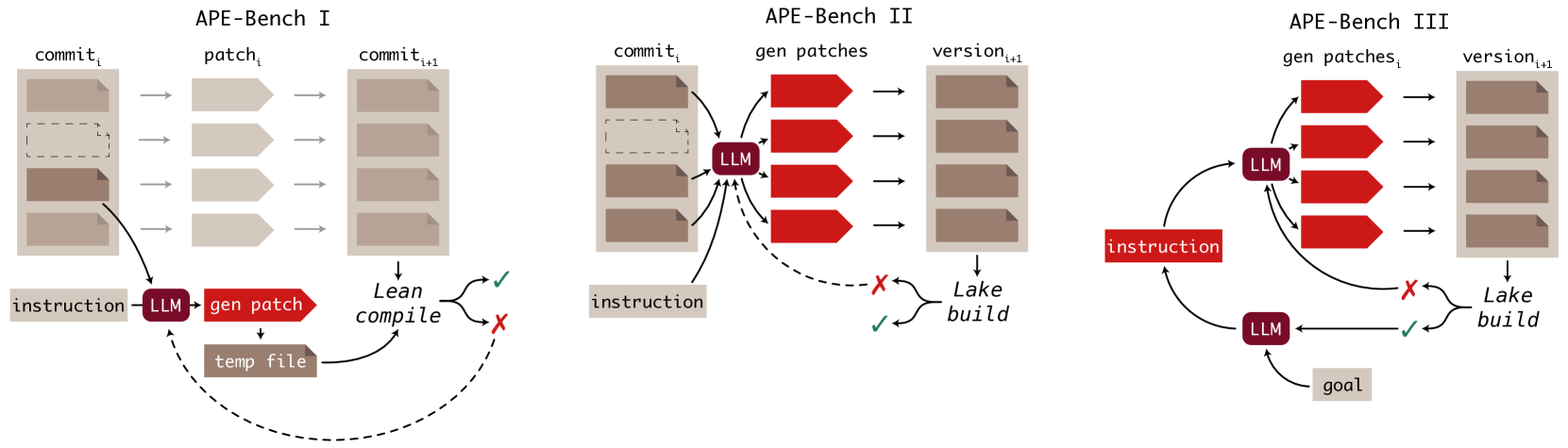
技术框架:APE-Bench I的整体框架包括以下几个主要组成部分:1) 从Mathlib4的真实提交历史中提取文件级别的证明工程任务,并用自然语言描述这些任务。2) 使用Lean编译器和LLM-as-a-Judge的混合方法来验证LLM生成的证明。3) 开发Eleanstic,一个可扩展的并行验证基础设施,用于高效地检查Mathlib多个版本的证明。
关键创新:APE-Bench I的关键创新在于其真实性和复杂性。它不是一个人工设计的、简化的基准,而是直接从真实的形式化数学库的开发过程中提取任务。这使得它能够更好地反映实际的证明工程挑战,并为LLM提供更具挑战性的测试环境。此外,混合验证方法结合了Lean编译器的可靠性和LLM的灵活性,提高了验证的效率和准确性。
关键设计:APE-Bench I的关键设计包括:1) 任务的多样性,涵盖了特征添加、证明重构和错误修复等不同类型的证明工程任务。2) 任务的粒度,选择文件级别的任务,以平衡任务的复杂性和可管理性。3) 验证方法,采用Lean编译器进行初步验证,然后使用LLM-as-a-Judge进行更细致的评估。Eleanstic并行验证框架利用多核CPU,加速验证过程。
🖼️ 关键图片


📊 实验亮点
在APE-Bench I基准测试上,最先进的LLM在局部编辑任务上表现出较好的性能,但在处理复杂的证明工程任务时性能显著下降。这表明现有LLM在处理复杂的、需要全局理解和推理的证明工程任务方面仍存在较大差距,为未来的研究提供了明确的方向。
🎯 应用场景
该研究成果可应用于自动化形式化验证、智能定理证明辅助工具开发等领域。通过自动化证明工程,可以提高形式化数学库的开发效率和质量,降低开发成本。未来,该技术有望应用于软件安全、硬件验证等关键领域,提升系统的可靠性和安全性。
📄 摘要(原文)
Recent progress in large language models (LLMs) has shown promise in formal theorem proving, yet existing benchmarks remain limited to isolated, static proof tasks, failing to capture the iterative, engineering-intensive workflows of real-world formal mathematics libraries. Motivated by analogous advances in software engineering, we introduce the paradigm of Automated Proof Engineering (APE), which aims to automate proof engineering tasks such as feature addition, proof refactoring, and bug fixing using LLMs. To facilitate research in this direction, we present APE-Bench I, the first realistic benchmark built from real-world commit histories of Mathlib4, featuring diverse file-level tasks described in natural language and verified via a hybrid approach combining the Lean compiler and LLM-as-a-Judge. We further develop Eleanstic, a scalable parallel verification infrastructure optimized for proof checking across multiple versions of Mathlib. Empirical results on state-of-the-art LLMs demonstrate strong performance on localized edits but substantial degradation on handling complex proof engineering. This work lays the foundation for developing agentic workflows in proof engineering, with future benchmarks targeting multi-file coordination, project-scale verification, and autonomous agents capable of planning, editing, and repairing formal libraries.