Theory of Mind in Large Language Models: Assessment and Enhancement
作者: Ruirui Chen, Weifeng Jiang, Chengwei Qin, Cheston Tan
分类: cs.CL, cs.AI
发布日期: 2025-04-26 (更新: 2025-08-25)
备注: Accepted to ACL 2025 main conference
💡 一句话要点
综述LLM心智理论能力:评估基准与提升策略分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心智理论 大型语言模型 评估基准 增强策略 社交智能 自然语言处理 人工智能
📋 核心要点
- 现有LLM在理解和模拟人类心理状态方面仍面临挑战,尤其是在复杂社交情境中。
- 本文通过分析现有评估基准和增强策略,系统性地综述了LLM的心智理论能力。
- 该研究为未来提升LLM在更真实和多样化场景下的心智理论能力提供了方向性指导。
📝 摘要(中文)
心智理论(ToM)是人类社会智能的基石,它指的是推断自身和他人心理状态的能力。随着大型语言模型(LLM)日益融入日常生活,理解它们解释和响应人类心理状态的能力对于实现有效互动至关重要。本文通过分析评估基准和增强策略,综述了LLM的ToM能力。在评估方面,我们重点关注最近提出的和广泛使用的基于故事的基准。在增强方面,我们深入分析了旨在提高LLM的ToM能力的最新方法。此外,我们概述了未来研究的有希望的方向,以进一步提升这些能力,并使LLM更好地适应更真实和多样化的场景。我们的综述为有兴趣评估和提升LLM的ToM能力的研究人员提供了一个宝贵的资源。
🔬 方法详解
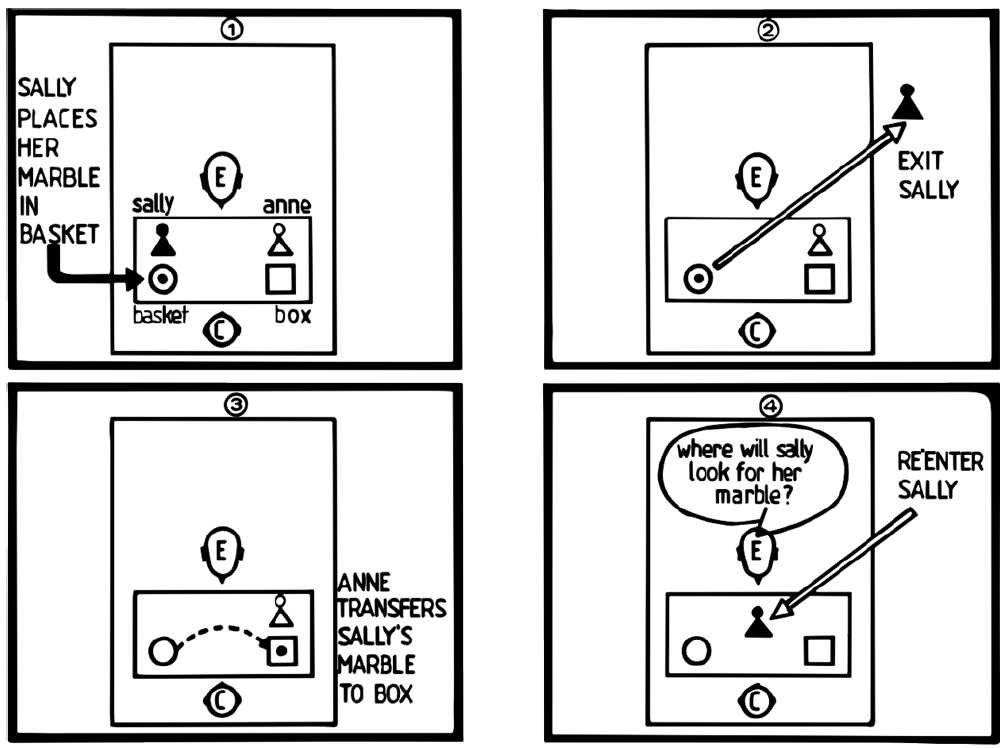
问题定义:论文旨在解决大型语言模型(LLM)在心智理论(ToM)方面的能力评估和提升问题。现有方法在评估LLM的ToM能力时,缺乏全面性和针对性,难以准确反映LLM在复杂社交场景下的表现。同时,提升LLM的ToM能力的方法也存在局限性,例如泛化能力不足,难以适应真实世界的复杂情况。
核心思路:论文的核心思路是通过系统性地分析现有的评估基准和增强策略,为研究人员提供一个全面的视角,从而促进LLM在ToM方面的研究进展。通过对现有方法的优缺点进行深入分析,为未来的研究方向提供指导。
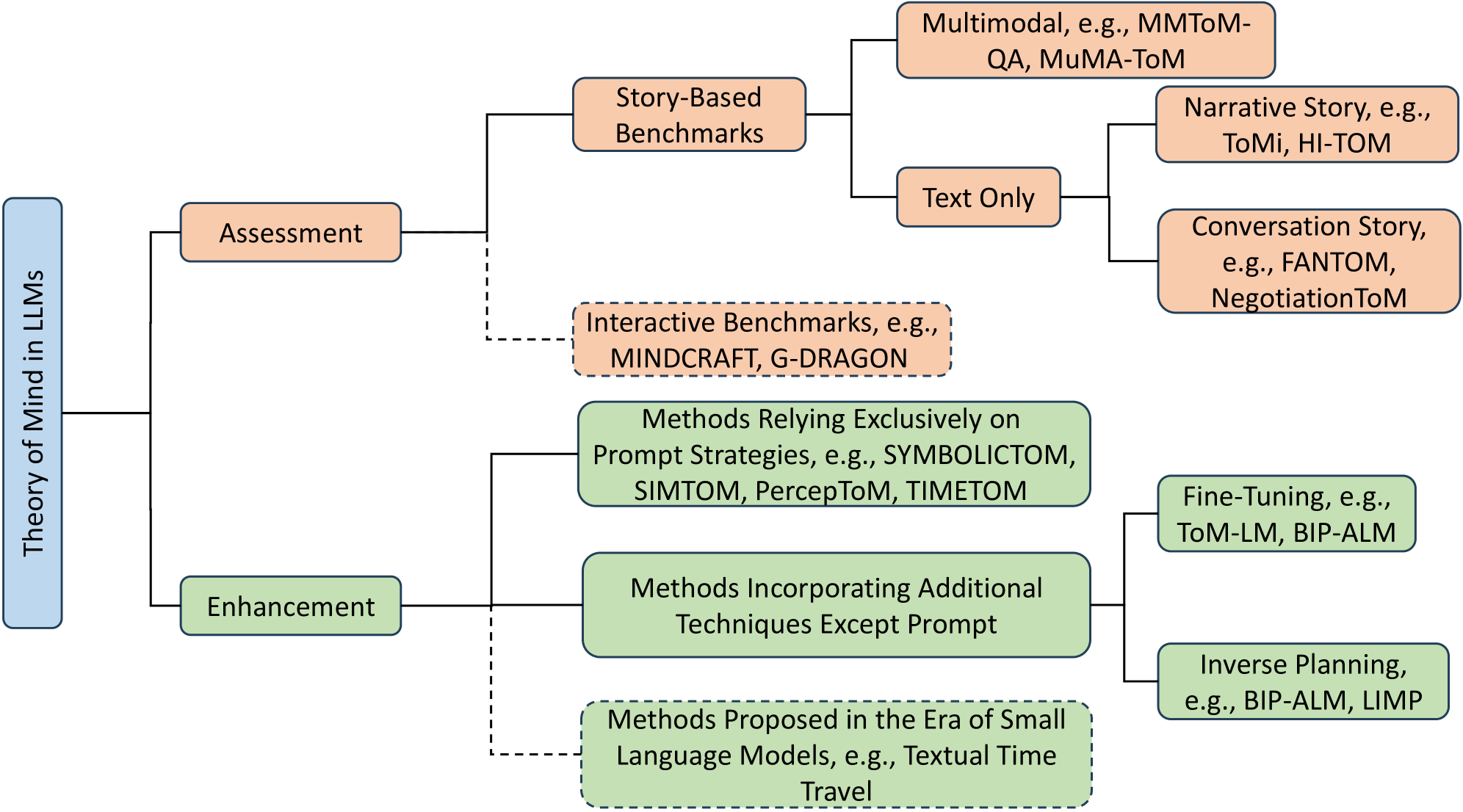
技术框架:论文主要分为两个部分:评估和增强。在评估方面,论文重点关注基于故事的基准测试,分析其设计原理和局限性。在增强方面,论文对现有的提升LLM的ToM能力的方法进行分类和总结,例如基于知识的方法、基于推理的方法和基于学习的方法。
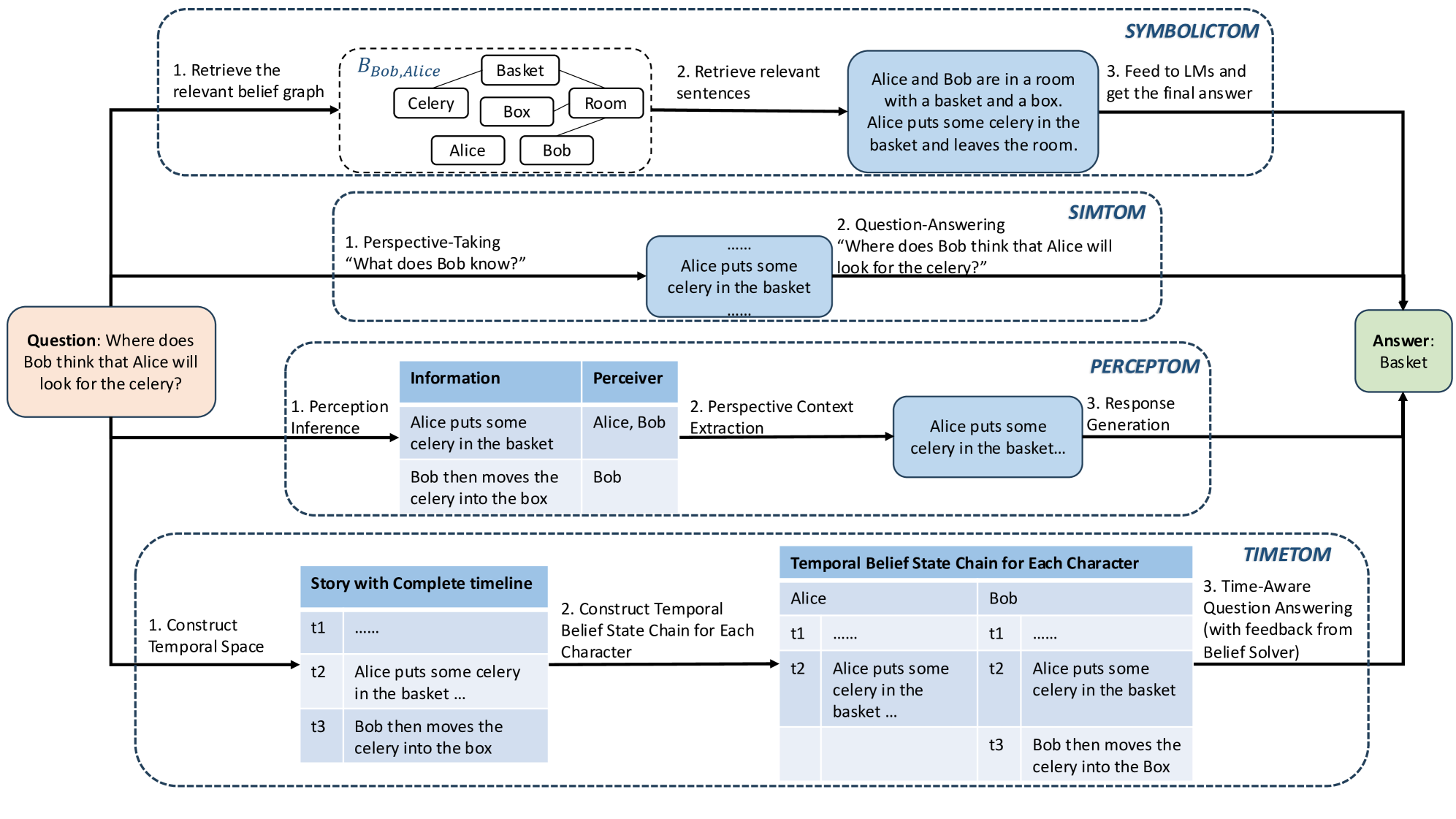
关键创新:论文的主要创新在于其系统性和全面性。它不是简单地罗列现有的方法,而是对这些方法进行了深入的分析和比较,指出了它们的优缺点,并提出了未来的研究方向。这种系统性的分析对于推动LLM在ToM方面的研究具有重要意义。
关键设计:论文的关键设计在于其对评估基准和增强策略的分类和分析框架。对于评估基准,论文关注其故事背景、问题类型和评估指标。对于增强策略,论文关注其核心思想、技术实现和实验结果。通过这种框架,论文能够全面地评估现有方法,并为未来的研究提供指导。
🖼️ 关键图片
📊 实验亮点
该综述论文重点分析了基于故事的ToM评估基准,并深入探讨了各种提升LLM的ToM能力的方法。通过对现有方法的优缺点进行比较,为未来的研究方向提供了有价值的见解。该论文为研究人员提供了一个全面的资源,有助于他们更好地理解和提升LLM的ToM能力。具体性能数据和提升幅度在论文中针对不同方法有详细描述,但此处作为综述不进行具体数值罗列。
🎯 应用场景
该研究成果可应用于开发更智能、更人性化的AI系统,例如:智能助手、社交机器人、教育软件等。提升LLM的心智理论能力有助于它们更好地理解人类意图、预测人类行为,从而实现更自然、更有效的交互。此外,该研究还有助于开发更可靠的AI系统,避免因误解人类意图而导致的错误行为。
📄 摘要(原文)
Theory of Mind (ToM)-the ability to reason about the mental states of oneself and others-is a cornerstone of human social intelligence. As Large Language Models (LLMs) become increasingly integrated into daily life, understanding their ability to interpret and respond to human mental states is crucial for enabling effective interactions. In this paper, we review LLMs' ToM capabilities by analyzing both evaluation benchmarks and enhancement strategies. For evaluation, we focus on recently proposed and widely used story-based benchmarks. For enhancement, we provide an in-depth analysis of recent methods aimed at improving LLMs' ToM abilities. Furthermore, we outline promising directions for future research to further advance these capabilities and better adapt LLMs to more realistic and diverse scenarios. Our survey serves as a valuable resource for researchers interested in evaluating and advancing LLMs' ToM capabilities.