Detect, Explain, Escalate: Sustainable Dialogue Breakdown Management for LLM Agents
作者: Abdellah Ghassel, Xianzhi Li, Xiaodan Zhu
分类: cs.CL
发布日期: 2025-04-26 (更新: 2026-01-08)
DOI: 10.1109/TASLPRO.2026.3653123
💡 一句话要点
提出'检测、解释、升级'框架以解决对话中断问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话管理 大型语言模型 实时检测 推理轨迹 资源效率 模型微调 用户信任
📋 核心要点
- 现有大型语言模型在对话中容易出现中断,影响用户体验和信任。
- 提出的框架通过微调小型模型和使用高级提示策略来高效检测和解释对话中断。
- 实验结果显示,微调模型在DBDC5上表现优越,推理成本降低54%,提升了整体性能。
📝 摘要(中文)
大型语言模型(LLMs)在对话AI应用中展现了显著能力,但其易受对话中断影响,给部署的可靠性和用户信任带来了挑战。本文提出了'检测、解释、升级'框架来管理LLM驱动的代理中的对话中断,强调资源高效的操作。我们的方法整合了两个关键策略:首先,微调了一个紧凑的8B参数模型,增强了教师生成的推理轨迹,作为高效的实时中断检测器和解释器。其次,系统评估前沿LLM,使用先进的提示策略进行高保真中断评估。我们的监控-升级管道将推理成本降低了54%,为高影响领域的稳健对话AI提供了一种经济有效且可解释的解决方案。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在对话中断时的检测和解释问题。现有方法在处理对话中断时效率低下,无法提供有效的用户支持。
核心思路:提出'检测、解释、升级'框架,通过微调小型模型并结合教师生成的推理轨迹,实现高效的实时中断检测和解释。设计的核心在于资源的高效利用,确保在必要时才调用更大的模型。
技术框架:整体架构包括三个主要模块:检测模块(微调的8B参数模型)、解释模块(基于推理轨迹的解释生成)和升级模块(在必要时调用更大的模型)。通过这些模块的协同工作,实现对话中断的有效管理。
关键创新:最重要的技术创新在于将小型模型与教师生成的推理轨迹结合,形成高效的实时检测和解释机制。这与现有方法的本质区别在于资源的节约和操作的高效性。
关键设计:在模型微调过程中,采用了特定的损失函数以优化分类和校准性能,并在网络结构上进行了精简,以确保在实时应用中的高效性。
🖼️ 关键图片


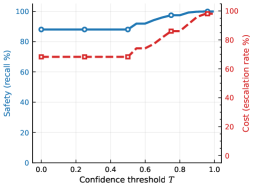
📊 实验亮点
实验结果表明,微调模型在DBDC5数据集上表现优于专门的分类器,准确率提升7%。同时,监控-升级管道将推理成本降低了54%,展示了其在实际应用中的经济效益。
🎯 应用场景
该研究的潜在应用领域包括客户服务、医疗咨询和教育等高影响领域。通过提供稳健的对话管理,能够显著提升用户体验和信任度,推动对话AI技术的广泛应用。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated substantial capabilities in conversational AI applications, yet their susceptibility to dialogue breakdowns poses significant challenges to deployment reliability and user trust. This paper introduces a "Detect, Explain, Escalate" framework to manage dialogue breakdowns in LLM-powered agents, emphasizing resource-efficient operation. Our approach integrates two key strategies: (1) We fine-tune a compact 8B-parameter model, augmented with teacher-generated reasoning traces, which serves as an efficient real-time breakdown detector and explainer. This model demonstrates robust classification and calibration on English and Japanese dialogues, and generalizes to the BETOLD dataset, improving accuracy by 7% over its baseline. (2) We systematically evaluate frontier LLMs using advanced prompting (few-shot, chain-of-thought, analogical reasoning) for high-fidelity breakdown assessment. These are integrated into an "escalation" architecture where our efficient detector defers to larger models only when necessary, substantially reducing operational costs and computational overhead. Our fine-tuned model and prompting strategies achieve state-of-the-art performance on DBDC5 and strong results on BETOLD, outperforming specialized classifiers on DBDC5 and narrowing the performance gap to larger proprietary models. The proposed monitor-escalate pipeline reduces inference costs by 54%, providing a cost-effective and interpretable solution for robust conversational AI in high-impact domains. Code and models are publicly available.