Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
作者: Yixin Cao, Shibo Hong, Xinze Li, Jiahao Ying, Yubo Ma, Haiyuan Liang, Yantao Liu, Zijun Yao, Xiaozhi Wang, Dan Huang, Wenxuan Zhang, Lifu Huang, Muhao Chen, Lei Hou, Qianru Sun, Xingjun Ma, Zuxuan Wu, Min-Yen Kan, David Lo, Qi Zhang, Heng Ji, Jing Jiang, Juanzi Li, Aixin Sun, Xuanjing Huang, Tat-Seng Chua, Yu-Gang Jiang
分类: cs.CL
发布日期: 2025-04-26
💡 一句话要点
LLM时代通用评估:超越基准的评测框架综述,关注能力评估与自动化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM评估 通用评估 能力评估 自动化评估 基准测试 泛化性
📋 核心要点
- 现有LLM评估方法依赖特定任务基准,难以全面衡量模型的核心能力,且泛化性不足。
- 论文提出一种基于能力的评估框架,并探索自动化评估方法,以应对LLM能力快速增长带来的挑战。
- 论文深入分析了评估方法、数据集、评估器和指标等多个角度,旨在提升LLM评估的通用性和可靠性。
📝 摘要(中文)
大型语言模型(LLMs)正以惊人的速度发展,并在学术界、工业界和日常应用中变得不可或缺。为了跟上现状,本综述探讨了LLM的兴起对评估带来的核心挑战。我们识别并分析了两个关键转变:(i)从特定任务到基于能力的评估,围绕知识、推理、指令遵循、多模态理解和安全性等核心能力重新组织基准;(ii)从手动到自动化的评估,包括动态数据集管理和“LLM-as-a-judge”评分。然而,即使有了这些转变,一个关键障碍仍然存在:评估的泛化问题。有限的测试集无法与模型的能力增长相匹配。我们将从方法、数据集、评估器和指标的角度剖析这个问题,以及上述两个转变的核心挑战。由于该领域的快速发展,我们将维护一个GitHub存储库(链接在每个部分中),以众包更新和更正,并热忱邀请贡献者和合作者。
🔬 方法详解
问题定义:现有LLM评估方法主要依赖于特定任务的基准测试,这些基准测试往往无法全面、准确地反映LLM的真实能力。此外,随着LLM能力的快速提升,固定的测试集难以覆盖所有可能的情况,导致评估结果的泛化性较差。现有方法在数据集构建、评估指标选择和评估过程自动化等方面存在诸多挑战。
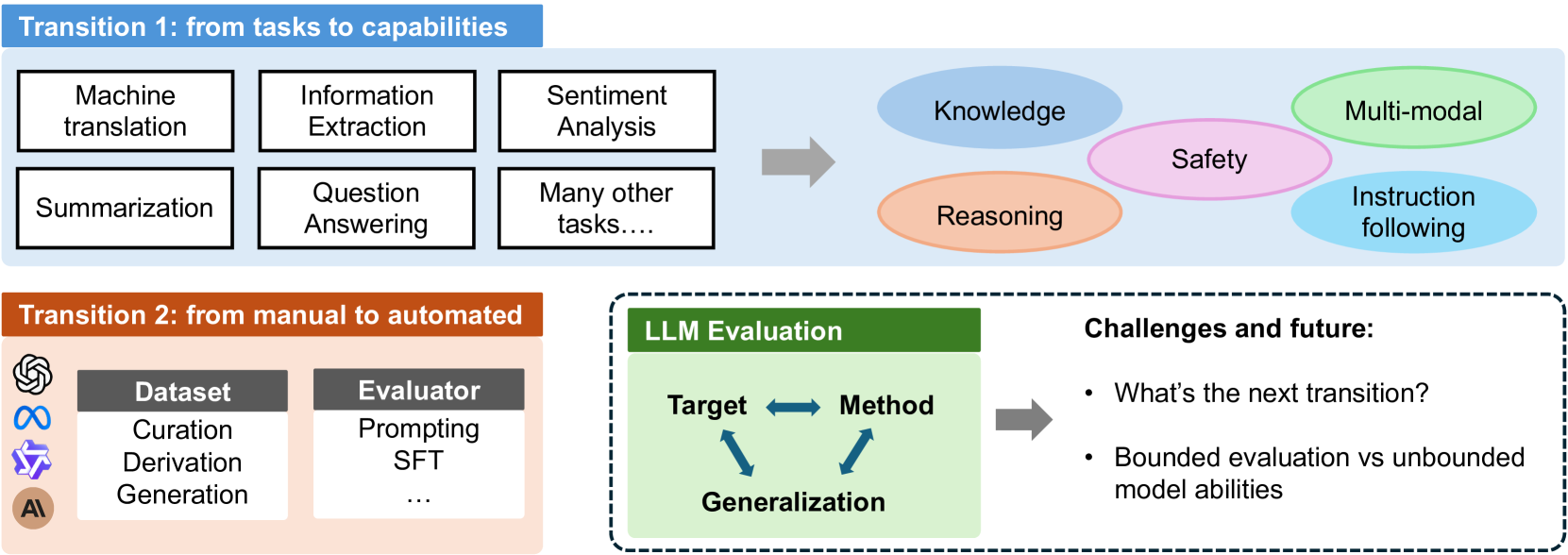
核心思路:论文的核心思路是从两个关键转变入手,重新审视LLM的评估方法。首先,从关注特定任务的性能转向关注模型的核心能力,例如知识掌握、推理能力、指令遵循能力、多模态理解能力和安全性。其次,推动评估过程的自动化,包括动态数据集的构建和利用LLM自身作为评估者。通过这两个转变,旨在构建一个更加通用、可靠和可扩展的LLM评估框架。
技术框架:该论文是一篇综述性文章,并没有提出一个具体的模型或算法框架。但是,它梳理了LLM评估领域的研究现状,并提出了一个概念性的框架,包括以下几个主要方面:1) 基于能力的评估:将评估任务分解为对LLM核心能力的评估,例如知识、推理、指令遵循等。2) 自动化评估:利用LLM自身的能力进行评估,例如使用LLM生成评估问题、判断答案的正确性等。3) 动态数据集构建:根据LLM的能力发展,动态地更新和扩充评估数据集。4) 评估指标:设计更加全面、客观的评估指标,以反映LLM的真实能力。
关键创新:该论文的关键创新在于提出了LLM评估的两个重要转变方向:从任务特定到能力导向,以及从手动到自动化。这种转变能够更好地应对LLM能力快速增长带来的挑战,并提高评估的通用性和可靠性。此外,论文还强调了评估泛化性的重要性,并从方法、数据集、评估器和指标等多个角度分析了影响泛化性的因素。
关键设计:由于是综述文章,没有具体的技术细节。但文章强调了几个关键的设计方向:1) 设计能够有效评估LLM核心能力的评估任务。2) 开发能够自动生成评估问题和判断答案正确性的LLM评估器。3) 构建能够反映LLM能力发展趋势的动态数据集。4) 设计能够全面、客观地反映LLM能力的评估指标。
🖼️ 关键图片
📊 实验亮点
该论文是一篇综述,没有具体的实验结果。但它总结了当前LLM评估领域的研究进展,并指出了未来的发展方向。论文强调了评估泛化性的重要性,并提出了基于能力的评估和自动化评估等关键概念,为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于LLM的开发、测试和部署等多个环节。通过更全面、准确的评估,可以帮助开发者更好地了解LLM的优缺点,从而有针对性地进行改进。此外,该研究还可以为LLM的应用提供指导,帮助用户选择最适合其需求的LLM模型。未来的影响在于推动LLM评估体系的标准化和自动化,加速LLM技术的进步和应用。
📄 摘要(原文)
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.