Comparing Uncertainty Measurement and Mitigation Methods for Large Language Models: A Systematic Review
作者: Toghrul Abbasli, Kentaroh Toyoda, Yuan Wang, Leon Witt, Muhammad Asif Ali, Yukai Miao, Dan Li, Qingsong Wei
分类: cs.CL, cs.AI
发布日期: 2025-04-25 (更新: 2025-09-26)
💡 一句话要点
系统性评测大语言模型不确定性度量与缓解方法,并提出基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不确定性量化 模型校准 幻觉问题 系统性综述
📋 核心要点
- 大型语言模型面临幻觉问题,即自信地输出错误信息,因此准确评估和量化模型的不确定性至关重要。
- 该论文通过系统性地回顾和比较现有的大语言模型不确定性量化和校准方法,填补了相关研究的空白。
- 论文构建了严格的基准,并在两个常用数据集上评估了六种方法,为未来研究提供了参考,并指出了未来的研究方向。
📝 摘要(中文)
大型语言模型(LLM)已在许多领域实现了变革。然而,幻觉——自信地输出不正确的信息——仍然是LLM面临的主要挑战之一。这就引出了如何准确评估和量化LLM的不确定性的问题。关于传统模型的大量文献已经探索了不确定性量化(UQ)来测量不确定性,并采用了校准技术来解决不确定性与准确性之间的不一致。虽然其中一些方法已经适用于LLM,但文献缺乏对其有效性的深入分析,也没有提供全面的基准来对现有解决方案进行有见地的比较。在这项工作中,我们通过对LLM的UQ和校准的代表性先前工作进行系统调查并引入严格的基准来填补这一空白。使用两个广泛使用的可靠性数据集,我们凭经验评估了六种相关方法,这证明了我们综述的重要发现。最后,我们为关键的未来方向提供了展望,并概述了未解决的挑战。据我们所知,这项调查是第一个专门研究LLM的校准方法和相关指标的研究。
🔬 方法详解
问题定义:大型语言模型(LLM)虽然在各个领域取得了显著进展,但其固有的“幻觉”问题,即自信地生成不准确或虚假信息,仍然是一个主要的挑战。现有的不确定性量化(UQ)和校准方法虽然在传统模型上有所应用,但缺乏针对LLM的深入分析和系统性比较,难以评估其有效性,也缺乏统一的基准进行对比。
核心思路:该论文的核心思路是通过系统性的文献综述,整理现有的LLM不确定性量化和校准方法,并构建一个严格的基准,对这些方法进行实证评估。通过对比不同方法在相同数据集上的表现,从而深入分析其优缺点,为未来的研究提供指导。
技术框架:该研究的技术框架主要包含以下几个阶段: 1. 文献综述:系统性地回顾现有的关于LLM不确定性量化和校准的相关研究。 2. 方法选择:选择具有代表性的UQ和校准方法进行评估。 3. 基准构建:构建一个严格的基准,包括数据集和评估指标。 4. 实验评估:在基准上对选定的方法进行实验评估。 5. 结果分析:分析实验结果,总结不同方法的优缺点,并提出未来的研究方向。
关键创新:该论文的关键创新在于: 1. 系统性综述:首次对LLM的不确定性量化和校准方法进行了系统性的综述,填补了该领域的空白。 2. 严格基准:构建了一个严格的基准,为未来研究提供了一个统一的评估平台。 3. 实证评估:通过实验评估,深入分析了不同方法的优缺点,为未来的研究提供了指导。
关键设计:论文的关键设计包括: 1. 数据集选择:选择了两个广泛使用的可靠性数据集,确保评估结果的可靠性。 2. 评估指标:采用了多种评估指标,包括准确率、校准误差等,全面评估了不同方法的性能。 3. 方法选择:选择了具有代表性的UQ和校准方法,覆盖了不同的技术思路。
🖼️ 关键图片
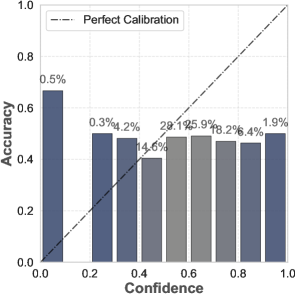
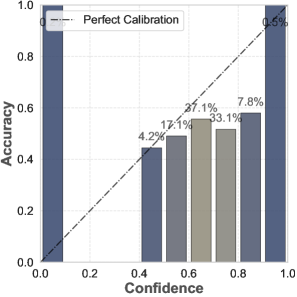
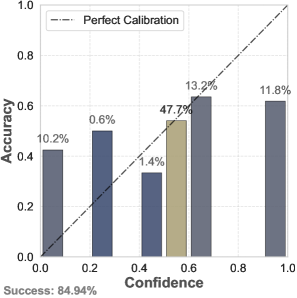
📊 实验亮点
该研究通过实验评估了六种相关方法,并使用两个广泛使用的可靠性数据集进行了验证。实验结果揭示了现有方法在LLM不确定性量化和校准方面的优缺点,为未来的研究提供了重要的参考依据。该研究是首个专门针对LLM校准方法和相关指标的系统性研究。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的大语言模型应用场景,例如医疗诊断、金融分析、法律咨询等。通过提高模型的不确定性感知能力,可以降低模型产生幻觉的风险,提高决策的准确性和安全性,从而提升用户信任度,并促进大语言模型在关键领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) have been transformative across many domains. However, hallucination -- confidently outputting incorrect information -- remains one of the leading challenges for LLMs. This raises the question of how to accurately assess and quantify the uncertainty of LLMs. Extensive literature on traditional models has explored Uncertainty Quantification (UQ) to measure uncertainty and employed calibration techniques to address the misalignment between uncertainty and accuracy. While some of these methods have been adapted for LLMs, the literature lacks an in-depth analysis of their effectiveness and does not offer a comprehensive benchmark to enable insightful comparison among existing solutions. In this work, we fill this gap via a systematic survey of representative prior works on UQ and calibration for LLMs and introduce a rigorous benchmark. Using two widely used reliability datasets, we empirically evaluate six related methods, which justify the significant findings of our review. Finally, we provide outlooks for key future directions and outline open challenges. To the best of our knowledge, this survey is the first dedicated study to review the calibration methods and relevant metrics for LLMs.