Random-Set Large Language Models
作者: Muhammad Mubashar, Shireen Kudukkil Manchingal, Fabio Cuzzolin
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-25
备注: 16 pages, 6 figures
💡 一句话要点
提出随机集大语言模型(RSLLM)以量化LLM的不确定性并提升答案正确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不确定性量化 随机集 信念函数 层次聚类 幻觉检测 可信人工智能
📋 核心要点
- 现有LLM在生成高质量文本的同时,缺乏有效的不确定性量化方法,难以评估生成文本的可信度。
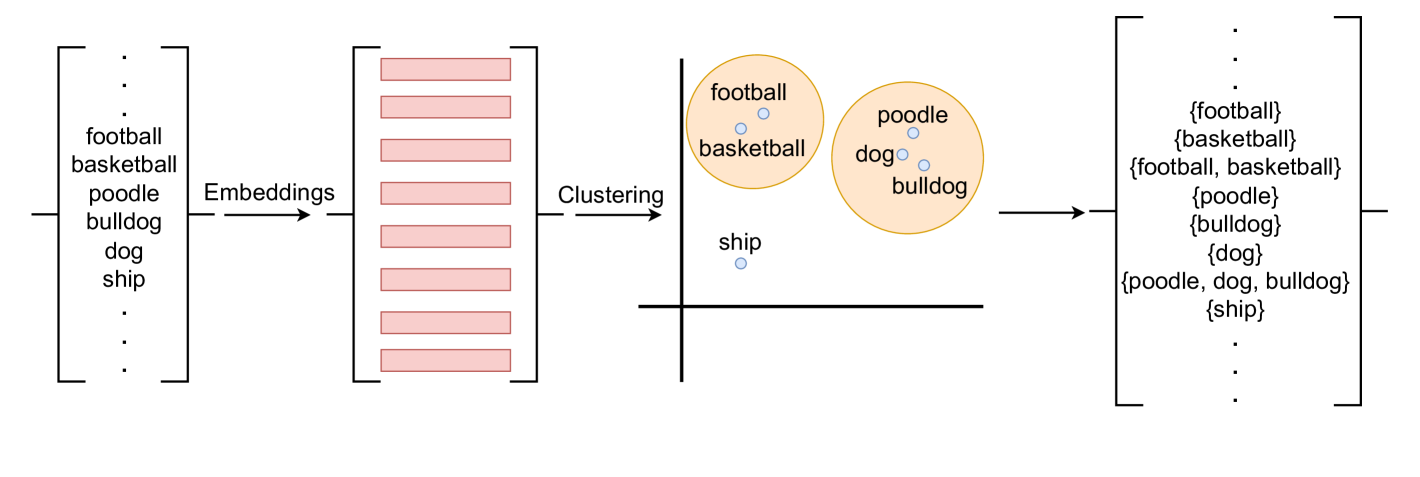
- RSLLM通过预测token空间上的随机集(信念函数)来表示不确定性,利用层次聚类提取token的焦点子集以提高效率。
- 实验结果表明,RSLLM在CoQA和OBQA数据集上优于标准模型,并能有效估计预测的不确定性,检测幻觉。
📝 摘要(中文)
本文研究了大语言模型(LLM)中的不确定性量化问题。提出了一种新颖的随机集大语言模型(RSLLM)方法,该方法预测token空间上的有限随机集(信念函数),而不是像传统LLM那样预测概率向量。为了提高效率,还提出了一种基于层次聚类的方法,提取并使用token的“焦点”子集预算,而不是使用所有可能的token集合,从而使该方法具有可扩展性和有效性。RS-LLM通过与其预测的信念函数相关的可信集的大小来编码由其生成过程中训练集的大小和多样性引起的认知不确定性。在CoQA和OBQA数据集上使用Llama2-7b、Mistral-7b和Phi-2模型对所提出的方法进行了评估,结果表明,在答案正确性方面,该方法优于标准模型,同时显示出估计预测中二阶不确定性的潜力,并提供检测幻觉的能力。
🔬 方法详解
问题定义:现有的大语言模型虽然在文本生成方面表现出色,但缺乏有效的不确定性量化机制。这使得我们难以判断生成文本的可信度,尤其是在对可靠性要求较高的应用场景中。现有的基于概率向量的LLM无法直接表示模型自身的不确定性,容易产生幻觉。
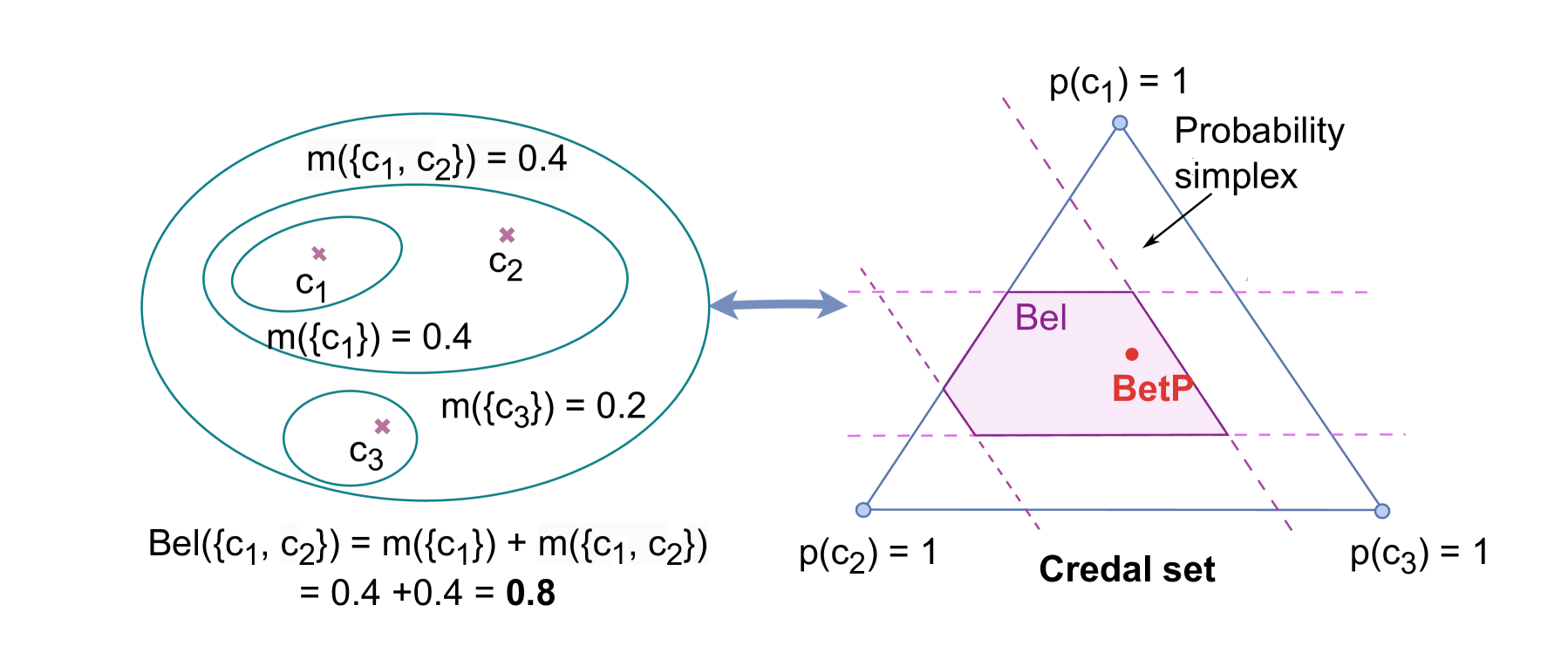
核心思路:本文的核心思路是使用随机集(Random Set)来表示LLM生成过程中的不确定性。与传统的概率向量不同,随机集能够表示多个可能的token集合,从而更好地捕捉模型的不确定性。通过预测token空间上的有限随机集(信念函数),RSLLM能够编码由训练数据引起的认知不确定性。
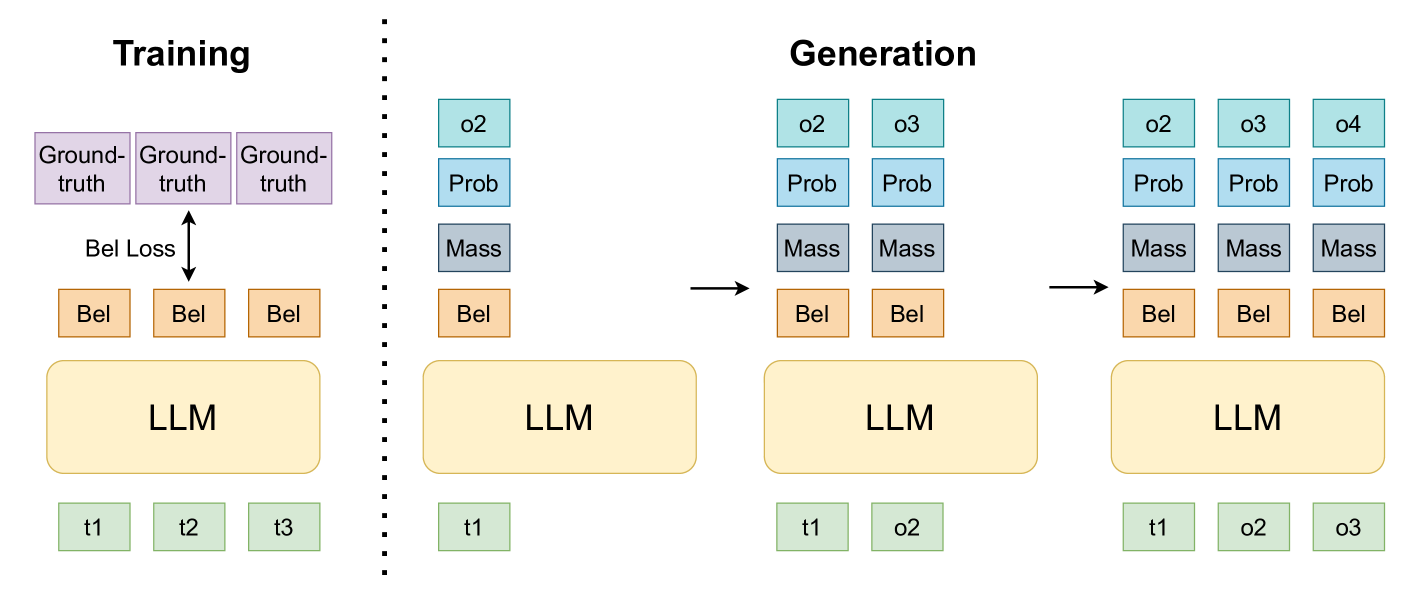
技术框架:RSLLM的整体框架包括以下几个主要阶段:1) 使用标准LLM生成token序列;2) 利用层次聚类方法从token空间中提取“焦点”子集,构建token集合的层级结构;3) 基于提取的焦点子集,构建信念函数,预测每个子集的置信度;4) 使用预测的信念函数进行不确定性量化和幻觉检测。
关键创新:RSLLM的关键创新在于使用随机集来表示LLM的不确定性。与传统的概率方法相比,随机集能够更灵活地表示多个可能的token集合,从而更好地捕捉模型的不确定性。此外,通过层次聚类提取焦点子集,有效降低了计算复杂度,使得RSLLM能够应用于大规模的LLM。
关键设计:RSLLM的关键设计包括:1) 层次聚类算法的选择,用于提取token的焦点子集;2) 信念函数的构建方法,用于预测每个焦点子集的置信度;3) 不确定性量化的指标,用于评估模型预测的不确定性;4) 幻觉检测的策略,用于识别模型生成的错误或不一致的信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RSLLM在CoQA和OBQA数据集上优于标准模型Llama2-7b、Mistral-7b和Phi-2,在答案正确性方面有所提升。此外,RSLLM还能够有效估计预测的不确定性,并提供检测幻觉的能力。这些结果表明,RSLLM是一种有效的不确定性量化方法,可以提高LLM的可靠性和可信度。
🎯 应用场景
RSLLM可应用于对可靠性要求较高的自然语言处理任务,例如问答系统、医疗诊断、金融分析等。通过量化模型的不确定性,RSLLM可以帮助用户更好地理解模型的预测结果,并避免盲目信任模型可能产生的错误信息。此外,RSLLM还可以用于检测和缓解LLM的幻觉问题,提高生成文本的质量和可靠性。
📄 摘要(原文)
Large Language Models (LLMs) are known to produce very high-quality tests and responses to our queries. But how much can we trust this generated text? In this paper, we study the problem of uncertainty quantification in LLMs. We propose a novel Random-Set Large Language Model (RSLLM) approach which predicts finite random sets (belief functions) over the token space, rather than probability vectors as in classical LLMs. In order to allow so efficiently, we also present a methodology based on hierarchical clustering to extract and use a budget of "focal" subsets of tokens upon which the belief prediction is defined, rather than using all possible collections of tokens, making the method scalable yet effective. RS-LLMs encode the epistemic uncertainty induced in their generation process by the size and diversity of its training set via the size of the credal sets associated with the predicted belief functions. The proposed approach is evaluated on CoQA and OBQA datasets using Llama2-7b, Mistral-7b and Phi-2 models and is shown to outperform the standard model in both datasets in terms of correctness of answer while also showing potential in estimating the second level uncertainty in its predictions and providing the capability to detect when its hallucinating.