Assessing the Potential of Generative Agents in Crowdsourced Fact-Checking
作者: Luigia Costabile, Gian Marco Orlando, Valerio La Gatta, Vincenzo Moscato
分类: cs.CL, cs.AI, cs.MA
发布日期: 2025-04-24 (更新: 2025-10-25)
备注: This paper has been published in Online Social Networks and Media (https://doi.org/10.1016/j.osnem.2025.100326). Please cite the published version accordingly
期刊: Online Social Networks and Media, Volume 48, September 2025, 100326
DOI: 10.1016/j.osnem.2025.100326
💡 一句话要点
利用生成式Agent模拟众包事实核查,提升效率与降低偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式Agent 众包事实核查 大型语言模型 信息真实性 认知偏差
📋 核心要点
- 现有众包事实核查易受质量波动和人为偏见影响,限制了其可靠性和可扩展性。
- 利用大型语言模型驱动的生成式Agent模拟人类行为,参与众包事实核查流程,旨在提升效率和一致性。
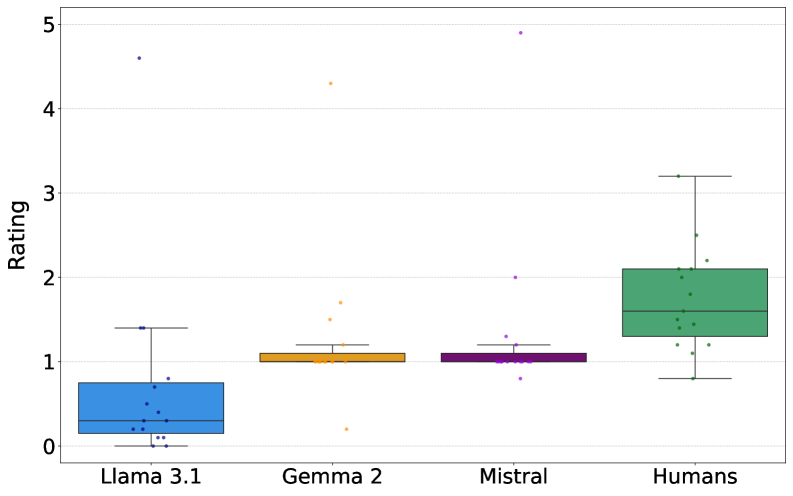
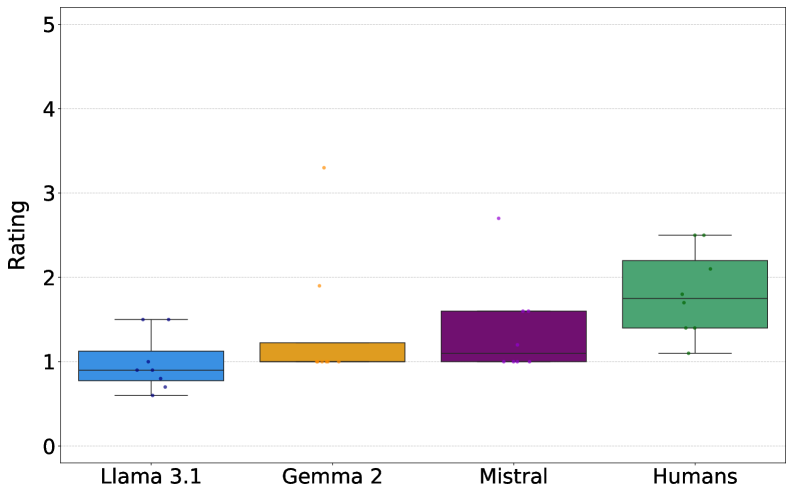
- 实验表明,Agent群体在真实性分类上优于人类,内部一致性更高,且对社会认知偏见更不敏感。
📝 摘要(中文)
在线错误信息的日益泛滥,催生了对可扩展、可靠的事实核查解决方案的迫切需求。众包事实核查——由非专业人士评估声明的真实性——提供了一种经济高效的替代方案,以取代专家验证,尽管存在质量和偏差方面的担忧。受某些背景下取得的良好结果的鼓舞,X(前身为Twitter)、Facebook和Instagram等主要平台已开始从集中式审核转向分散的、基于众包的方法。与此同时,大型语言模型(LLM)的进步在包括声明检测和证据评估在内的核心事实核查任务中表现出强大的性能。然而,它们在众包工作流程中的潜在作用仍未被探索。本文研究了由LLM驱动的生成式Agent(模拟人类行为和决策的自主实体)是否能够对传统上由人类群体保留的事实核查任务做出有意义的贡献。使用La Barbera等人(2024)的协议,我们模拟了具有不同人口统计和意识形态特征的生成式Agent群体。Agent检索证据,评估声明的多个质量维度,并发布最终的真实性判断。我们的结果表明,Agent群体在真实性分类方面优于人类群体,表现出更高的内部一致性,并显示出对社会和认知偏差的敏感性降低。与人类相比,Agent更系统地依赖于诸如准确性、精确性和信息性等信息性标准,这表明决策过程更结构化。总的来说,我们的发现突出了生成式Agent作为可扩展、一致且较少偏见的众包事实核查系统贡献者的潜力。
🔬 方法详解
问题定义:论文旨在解决众包事实核查中人为因素引入的偏差和不一致性问题。现有方法依赖于人类评估员,其判断易受个人背景、意识形态和社会认知偏见的影响,导致事实核查结果的可靠性降低。此外,人工评估的成本较高,难以扩展到大规模的在线内容审核。
核心思路:论文的核心思路是利用大型语言模型(LLM)驱动的生成式Agent来模拟人类评估员的行为,从而实现自动化、可扩展且更客观的事实核查流程。通过赋予Agent不同的“人格”和背景,可以模拟多样化的观点,并减少单一来源的偏见。Agent的决策过程基于预定义的规则和证据评估,从而提高了一致性和可解释性。
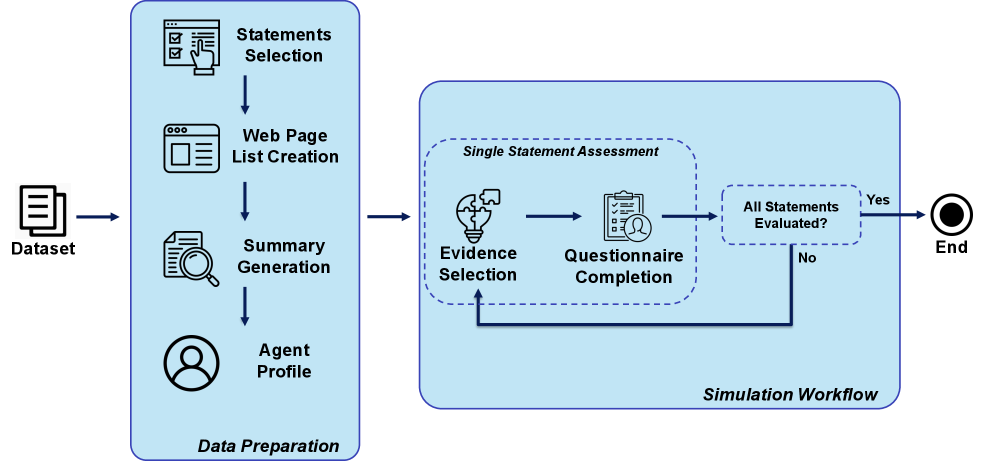
技术框架:该研究采用La Barbera等人(2024)提出的众包事实核查协议,并将其应用于生成式Agent。整体流程包括以下几个阶段:1) 声明输入:接收需要核查的声明。2) 证据检索:Agent利用搜索引擎或知识库检索与声明相关的证据。3) 证据评估:Agent根据预定义的质量维度(如准确性、精确性和信息性)评估证据。4) 真实性判断:Agent综合评估结果,给出最终的真实性判断。5) 群体决策:多个Agent的判断结果进行汇总,形成最终的众包结论。
关键创新:该研究的关键创新在于将生成式Agent引入众包事实核查领域,并验证了其在提升效率、一致性和降低偏见方面的潜力。与传统的人工评估相比,Agent可以更系统地依赖客观证据,并减少人为因素的干扰。此外,通过模拟不同背景的Agent,可以更好地应对复杂和有争议的声明。
关键设计:研究中,Agent的人格和背景通过prompt工程进行定义,例如,可以指定Agent的年龄、性别、教育程度、政治立场等。证据评估的质量维度是预先定义的,并赋予不同的权重。Agent的决策过程基于这些维度进行加权平均,并设置阈值来判断声明的真实性。此外,研究还探索了不同的群体决策策略,例如多数投票和加权平均。
🖼️ 关键图片
📊 实验亮点
实验结果表明,生成式Agent群体在真实性分类方面优于人类群体,内部一致性更高,且对社会和认知偏差的敏感性降低。Agent更系统地依赖于准确性、精确性和信息性等客观标准进行判断,表明其决策过程更加结构化。这些结果突出了生成式Agent在众包事实核查中的巨大潜力。
🎯 应用场景
该研究成果可应用于大规模在线内容审核、社交媒体平台的事实核查、新闻媒体的信源验证等领域。通过部署生成式Agent,可以显著提高事实核查的效率和覆盖范围,减少错误信息的传播,并提升公众对信息的信任度。未来,该技术还可用于个性化信息推荐,根据用户的偏好和信任度过滤不实信息。
📄 摘要(原文)
The growing spread of online misinformation has created an urgent need for scalable, reliable fact-checking solutions. Crowdsourced fact-checking - where non-experts evaluate claim veracity - offers a cost-effective alternative to expert verification, despite concerns about variability in quality and bias. Encouraged by promising results in certain contexts, major platforms such as X (formerly Twitter), Facebook, and Instagram have begun shifting from centralized moderation to decentralized, crowd-based approaches. In parallel, advances in Large Language Models (LLMs) have shown strong performance across core fact-checking tasks, including claim detection and evidence evaluation. However, their potential role in crowdsourced workflows remains unexplored. This paper investigates whether LLM-powered generative agents - autonomous entities that emulate human behavior and decision-making - can meaningfully contribute to fact-checking tasks traditionally reserved for human crowds. Using the protocol of La Barbera et al. (2024), we simulate crowds of generative agents with diverse demographic and ideological profiles. Agents retrieve evidence, assess claims along multiple quality dimensions, and issue final veracity judgments. Our results show that agent crowds outperform human crowds in truthfulness classification, exhibit higher internal consistency, and show reduced susceptibility to social and cognitive biases. Compared to humans, agents rely more systematically on informative criteria such as Accuracy, Precision, and Informativeness, suggesting a more structured decision-making process. Overall, our findings highlight the potential of generative agents as scalable, consistent, and less biased contributors to crowd-based fact-checking systems.