Multilingual Performance Biases of Large Language Models in Education
作者: Vansh Gupta, Sankalan Pal Chowdhury, Vilém Zouhar, Donya Rooein, Mrinmaya Sachan
分类: cs.CL, cs.AI
发布日期: 2025-04-24 (更新: 2025-08-05)
💡 一句话要点
评估大型语言模型在多语言教育场景下的性能偏差,揭示低资源语言的性能瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多语言教育 性能偏差 低资源语言 教育任务评估
📋 核心要点
- 大型语言模型在教育领域应用广泛,但其多语言性能,尤其是在低资源语言上的表现,缺乏充分评估。
- 该研究通过多语言教育任务评估,揭示了LLM在不同语言上的性能差异,并与训练数据中的语言代表性关联。
- 实验结果表明,LLM在低资源语言上的性能显著低于英语,建议在部署前进行目标语言的有效性验证。
📝 摘要(中文)
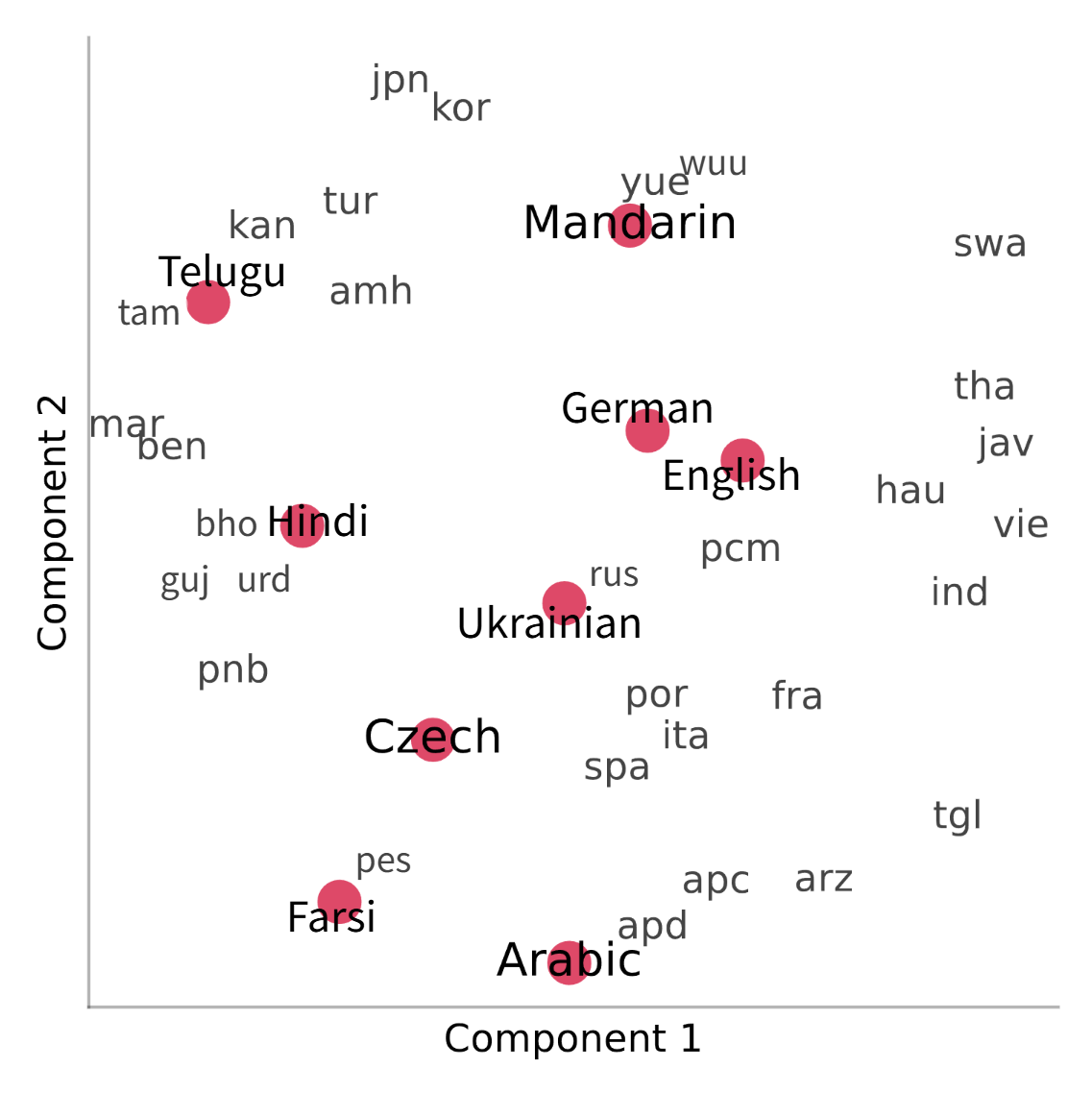
大型语言模型(LLMs)在教育领域的应用日益广泛。虽然这些应用正扩展到英语以外的语言,但目前的LLMs仍然主要以英语为中心。本文旨在确定LLMs在非英语语言教育环境中的使用是否合理。我们评估了流行的LLMs在八种语言(普通话、印地语、阿拉伯语、德语、波斯语、泰卢固语、乌克兰语、捷克语)以及英语中的四项教育任务上的表现:识别学生误解、提供有针对性的反馈、互动辅导和翻译评分。我们发现,在这些任务上的表现与训练数据中语言的代表性在一定程度上相关,低资源语言的任务表现较差。尽管这些模型在大多数语言中的表现都相当不错,但与英语相比,性能的频繁下降是显著的。因此,我们建议从业者在部署之前,首先验证LLM在目标语言中对于其教育任务的有效性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在多语言教育场景下的性能偏差。现有LLMs主要以英语为中心,在非英语语言上的教育应用效果未知。现有方法缺乏对LLMs在不同语言上的性能差异的系统性评估,以及对低资源语言性能瓶颈的深入分析。
核心思路:论文的核心思路是通过在多种语言的教育任务上评估LLMs的性能,来揭示其多语言性能偏差。通过对比不同语言的表现,并与训练数据中的语言代表性进行关联,从而分析LLMs在低资源语言上的性能瓶颈。这种方法能够为LLMs在多语言教育场景中的应用提供指导。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择流行的LLMs作为评估对象;2) 选择具有代表性的教育任务,包括识别学生误解、提供有针对性的反馈、互动辅导和翻译评分;3) 选择多种语言,包括英语、普通话、印地语、阿拉伯语、德语、波斯语、泰卢固语、乌克兰语和捷克语;4) 在选定的语言和任务上评估LLMs的性能;5) 分析不同语言的性能差异,并与训练数据中的语言代表性进行关联。
关键创新:论文的关键创新在于:1) 系统性地评估了LLMs在多语言教育场景下的性能偏差,填补了现有研究的空白;2) 揭示了LLMs在低资源语言上的性能瓶颈,为LLMs在多语言教育场景中的应用提供了指导;3) 将LLMs的性能与训练数据中的语言代表性进行关联,为LLMs的训练和优化提供了新的思路。
关键设计:论文的关键设计包括:1) 选择了具有代表性的教育任务,能够全面评估LLMs在教育领域的应用能力;2) 选择了多种语言,覆盖了高资源和低资源语言,能够揭示LLMs在不同语言上的性能差异;3) 采用了标准化的评估指标,能够客观地评估LLMs的性能;4) 对实验结果进行了深入的分析,能够揭示LLMs在低资源语言上的性能瓶颈。
🖼️ 关键图片
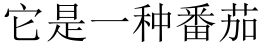

📊 实验亮点
实验结果表明,LLM在不同语言上的性能存在显著差异,低资源语言(如泰卢固语、乌克兰语、捷克语)上的性能明显低于英语。例如,在识别学生误解的任务中,低资源语言的准确率平均下降了15%-20%。这些结果强调了在多语言教育场景下,需要对LLM的性能进行充分评估和验证。
🎯 应用场景
该研究成果可应用于多语言教育平台的设计与优化,帮助教育者选择合适的LLM,并针对特定语言和任务进行微调。同时,该研究也为LLM的开发者提供了改进方向,例如增加低资源语言的训练数据,从而提升LLM在多语言教育场景下的应用效果。未来,该研究可扩展到更多教育任务和语言,为全球教育公平做出贡献。
📄 摘要(原文)
Large language models (LLMs) are increasingly being adopted in educational settings. These applications expand beyond English, though current LLMs remain primarily English-centric. In this work, we ascertain if their use in education settings in non-English languages is warranted. We evaluated the performance of popular LLMs on four educational tasks: identifying student misconceptions, providing targeted feedback, interactive tutoring, and grading translations in eight languages (Mandarin, Hindi, Arabic, German, Farsi, Telugu, Ukrainian, Czech) in addition to English. We find that the performance on these tasks somewhat corresponds to the amount of language represented in training data, with lower-resource languages having poorer task performance. Although the models perform reasonably well in most languages, the frequent performance drop from English is significant. Thus, we recommend that practitioners first verify that the LLM works well in the target language for their educational task before deployment.